微软专利提出标记的虚拟对象和物理对象,实现多全息图批量抓取移动
语义标记虚拟对象和物理对象
(映维网 2021年09月21日)增强现实设备通常可以计算和维护由摄像头成像的物理环境的连续更新表示。例如,所述设备可以执行表面重建过程,产生和更新物理环境的网格表示。所述设备同时可以基于物理环境的计算表示在物理环境内的世界锁定位置显示全息图。
如果要通过所述设备将虚拟对象从一个位置移动到另一个位置,用户一般是通过特定手势动作输入来“抓取”虚拟对象,并将虚拟对象带到新位置。但当用户将虚拟对象移动到不同的房间以及尝试移动多个虚拟对象时,这可能会变得十分复杂。例如,为了将多个不同的虚拟对象移动到新位置,用户可能必须在两个房间之间来回移动几次。
所以,微软申请了一份名为“Semantically tagged virtual and physical objects”的专利发明,并希望通过语义标记的虚拟对象和物理对象,然后再利用方便的语音命令来解决所述问题。
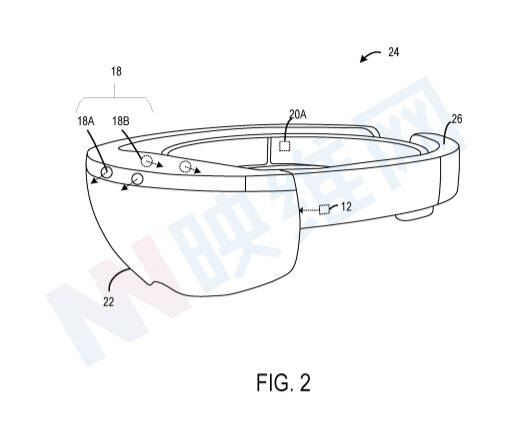
专利描述的头戴式显示设备包括显示设备、摄像头设备、输入设备和处理器。
一个或多个朝外摄像头18可配置为捕获和/或测量物理环境的物理环境属性。在一个示例中,一个或多个朝外摄像头18可包括配置为收集物理空间的可见光图像的可见光摄像头或RBG摄像头。另外,一个或多个朝外摄像头18可包括配置为收集物理空间的深度图像的深度摄像头。更具体地,在一个示例中,深度摄像头是红外飞行时间深度摄像头。在另一示例中,深度摄像头是红外结构光深度摄像头。
处理器12可利用来自外向摄像头18A的数据来生成和/或更新物理环境的三维模型。处理器12可以使用来自朝外摄像头18B的数据来识别物理环境的表面和/或测量物理环境的一个或多个表面参数。处理器12可以执行指令以生成/更新显示设备所显示的虚拟场景,识别物理环境的表面,并基于物理环境中识别的表面识别对象。
可以评估头显设备24相对于物理环境的位置和/或方向,以便增强现实图像可以以期望的方向准确显示在期望的真实位置。如上所述,处理器12可执行指令以生成包括表面重建信息的物理环境三维模型,包括生成可用于识别对象之间的表面和边界的物理环境几何表示,并基于经过训练的人工智能机器学习模型识别物理环境中的对象。
处理器配置为存储与一个或多个语义标记关联的物理对象和虚拟对象的数据库。处理器同时配置为经由输入设备从用户接收自然语言输入,并对自然语言输入执行语义处理,以确定用户指定的操作,并识别由自然语言输入指示的一个或多个语义标签。处理器进一步配置为基于所识别的一个或多个语义标记选择目标虚拟对象和目标物理对象,基于目标物理对象对目标虚拟对象执行确定的用户指定操作,以及在与目标物理对象关联的物理位置显示目标虚拟对象。
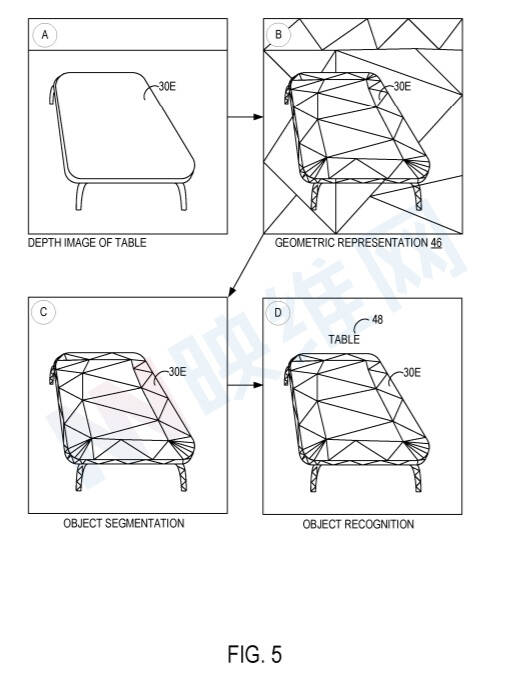
图5示是表面重建和分解管道示例。图5A是头显摄像头获取的深度图像。在表面重建和分解管道中,通过表面重建技术处理深度图像,以生成物理环境的几何表示。图5B是表面网格形式的几何表示示例。
在表面重建和分解管道中,包括深度图像的场景数据由诸如FCN的人工智能机器学习模型处理,以识别对象边界并将物理环境的几何表示分割为检测到的物理对象。在图5C中,系统已经识别了桌子的几何表示的对象边界,并且桌子的几何表示已经分割成检测对象。
在图5D中,经过训练的人工智能学习模型可以处理检测到的对象,并基于对象的不同因素或特征识别检测到的对象,例如几何形状、大小、颜色、表面纹理等。检测到的对象可识别为桌子,并且相应的“桌子”语义标签可与识别的物理对象相关联。应当理解,可以基于其他因素选择其他语义标签并将其与所识别的对象相关联。例如,如果识别的对象位于已被语义标记为“客厅”的房间中,则位于房间中的识别表对象可以继承“客厅”语义标记。以这种方式,每个检测到的物理对象可以与一个或多个语义标记相关联,并且对检测到的物理对象的引用可以与一个或多个语义标记一起存储在数据库中。
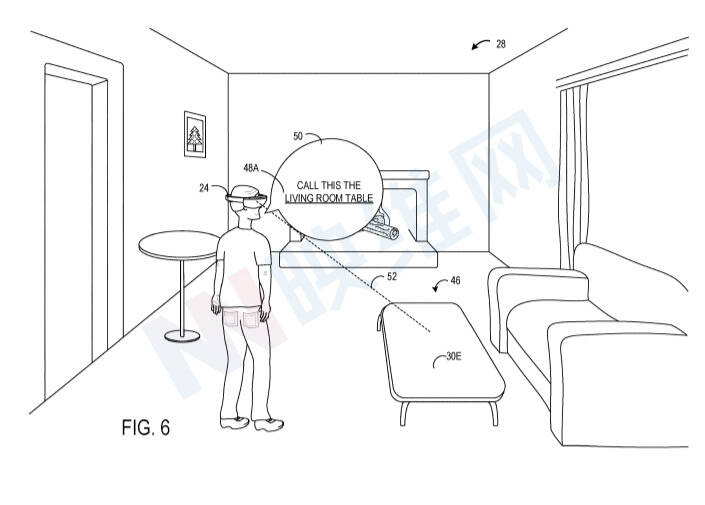
图6是基于用户输入对检测到的对象进行语义标记。如图所示,头显可以通过麦克风输入设备接收作为语音输入的用户输入。可以基于用户输入启动用于对检测到的物理对象进行语义标记的过程。例如,在通过自然语言处理模块进行处理之后,头显可以检测到用户正尝试基于术语“将它叫作”来命名对象。自然语言处理模块可以训练为基于其他术语来启动所述过程,例如,“命名所述对象”、“将所述对象称为”等。
在所示的示例中,头显检测到桌子对象,并且检测到当前用户注视方向正朝向桌子。所以,头显设备可以将术语“它”解析为指向与当前用户注视方向相交的物理对象。
由深度神经网络处理器和/或处理器执行的自然语言处理模块处理用户输入,以识别“客厅桌子”的用户指定语义标签。处理器随后可配置为将检测到的物理对象与数据库中的用户指定语义标签相关联。以上述方式,语义标签可以基于用户输入和/或通过经过训练的人工智能机器学习模型,并以编程方式与物理环境中的物理对象相关联。
在完成语义标记后,用户可以利用语音命令完成一个或批量操作。例如,将虚拟植物移动到客厅桌子。
作为具体示例,如果自然语言输入是“将虚拟植物移动到客厅桌子”,则自然语言处理模块可配置为识别动词“移动”,并选择移动操作作为用户指定的操作。自然语言处理模块可进一步将名词“虚拟植物”和“客厅桌子”识别为识别的语义标签。通过将所识别的语义标签与数据库进行比较,处理器可以确定标签“虚拟植物”指的是植物的虚拟对象,并且标签“客厅桌子”指的是客厅中的物理桌子。所以,处理器可以选择植物虚拟对象作为目标虚拟对象,并选择客厅桌子物理对象作为目标物理对象。
以这种方式,用户可以轻松地完成移动操作。
相关专利:Microsoft Patent | Semantically tagged virtual and physical objects
名为“Semantically tagged virtual and physical objects”的微软专利申请最初在2021年5月提交,并在日前由美国专利商标局公布。