微软专利介绍用机器学习为HoloLens用户提供完整面部显示效果
计算补充完整用户面部图像
(映维网 2021年12月20日)在进行视频通话时,任何头戴式显示器系统都必须克服的一个基本问题是:如何呈现用户的完整面部。挑战在于,头显遮蔽面部,尤其是眼睛;用户通常是可以移动;以及用户不在合适的捕获设备的视场范围内。
在名为“Computing images of head mounted display wearer”的专利申请中,微软介绍了一种利用机器学习装置来计算补充完整用户面部图像的方法和系统。
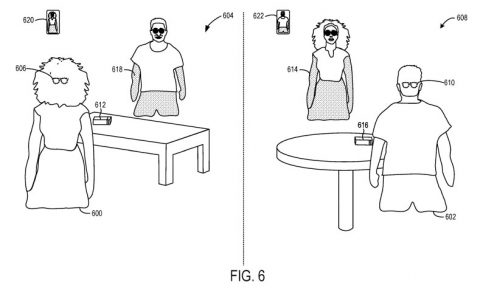
图1是佩戴头显102并参与视频会议呼叫的人员100的示意图,其中远程方112将所述人员感知成没有佩戴头显时的形象。
在一个实现中,图1中的示例涉及非对称头显视频呼叫,其中远程方112可以使用传统显示器,例如带有集成网络摄像头的笔记本电脑。远程方112从本地用户接收虚拟网络摄像头流,其中用户100可以描述为没有佩戴头显时的形象,并且其面部表情与用户100的真实面部表情匹配。虚拟网络摄像头的视点是根据用户偏好预先配置或设置。
在图1的示例中,存在两个额外的面向面部的捕获设备,但由于它们被HMD主体遮挡,因此不可见。两个附加的面部面向捕获设备包括第一眼睛面向捕获设备和第二眼睛面向捕获设备。第一和第二眼睛面向捕获设备可以分别是面向右眼的捕获设备和面向左眼的捕获设备,并且可以是红外捕获设备。第一和第二眼睛面向捕获设备的视场布置成包括眼睛本身、鼻子的一部分以及眼睛周围的脸颊区域。
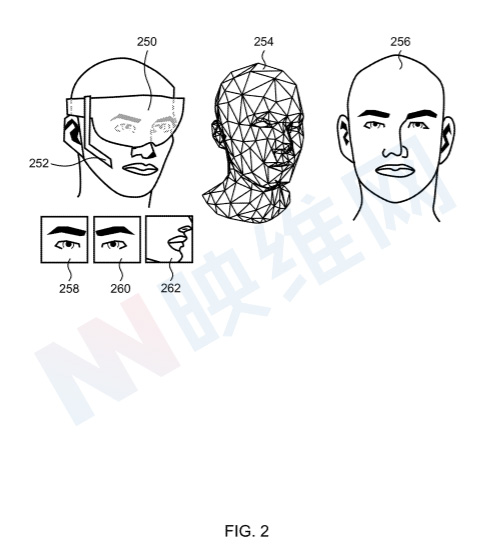
如图2所示,在臂架104中,由面向左眼的捕获设备捕获的图像258、由面向右眼的捕获设备捕获的图像260和由捕获设备捕获的图像262都是在同一时间间隔内拍摄。注意,每个面部捕捉设备都具有面部的局部视图,并且无法获得面部的完整视图。
由于头显本身遮挡了佩戴者的大部分面部,因此不可能使用捕获设备获得面部的完整视图。由于头显和佩戴者面部之间的空间很小,因此无法从头显内的视角观察佩戴者的整个面部,因此有必要进行预测判断。可用于进行预测的观测数据源包括来自面部捕捉设备的经验观测传感器数据。
可以发现,使用三个具有面向面部的捕捉设备可以获得特别好的结果。这是因为眼睛和口腔区域对于预测头显用户的表情非常重要。
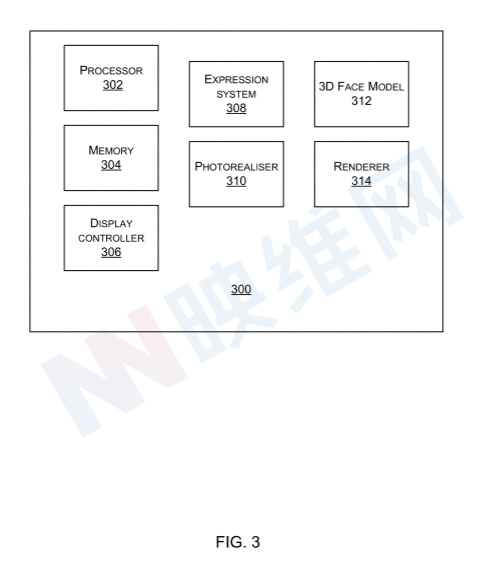
图3是用于计算用户面部图像的装置300的示意图。在某些情况下,图3的装置与头显集成。在其它情况下,所述装置远离HMD,例如在伴随计算设备中或在云服务部署中。伴随计算设备是物理上接近头显并且与头显有线或无线通信的计算设备。伴随计算设备的例子有智能手机、智能手表和笔记本电脑等
所述用户面部图像计算装置包括至少一个处理器302、存储器304和显示控制器306,后者控制头显对一个或多个虚拟对象的显示。所述装置进一步包括表情系统308,表情系统308将由至少一个面部捕捉设备捕捉的传感器数据作为输入,并计算表情参数的输出值。所述表情系统包括机器学习模型,机器学习模型经训练以从输入图像计算表情参数。照片校准器310是经训练以将从3D面部模型渲染的图像映射到照片级真实感图像的机器学习模型。
所述装置包括具有参数的三维面部模型312。在一个实施例中,3D面部模型312具有标识、表情和姿势参数。标识参数指定三维人脸模型的实例化所代表的个人。表情参数指定三维人脸模型的形状和外观。姿势参数指定三维人脸模型的可移动组件的位置和方向,如颌骨、颈部骨骼、眼球、舌头。姿势参数的值是使用来自一个或多个捕获设备的数据推断出来。
在某些情况下,眼睛姿势和下巴姿势是使用眼睛和臂架摄像头的输出确定。可以使用仅包含表情参数的三维人脸模型,例如在预配置姿势和标识参数的位置,或者在不需要移动下巴和眼睛的位置。所述装置同时包括渲染器314,其用于渲染来自3D面部模型312的图像。渲染器是用于渲染来自3D模型的图像的任何设备,例如商用计算机图形渲染器,其使用光线追踪和关于虚拟camera的视点的信息来渲染图像。
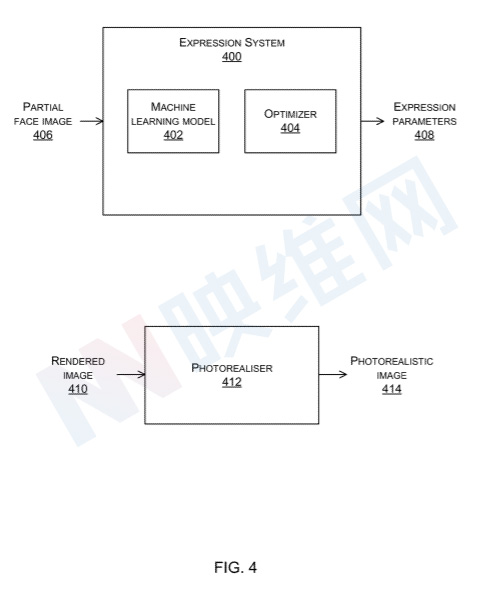
诸如图3的表情系统400包括机器学习模型402和优化器404。经过训练的机器学习模型是神经网络,或任何其他合适类型的机器学习模型。在一个示例中,表情系统400的机器学习模型402已经使用了描述头显用户面部局部视图的合成图像进行训练,合成图像与已知表情参数相关。
在一个示例中,通过从参数化面部模型采样、将表情应用于采样的参数化面部模型、添加虚拟头显和虚拟照明、从虚拟头显中的一个或多个面部捕捉设备的视点渲染来生成合成图像。
在一个示例中,参数化面部模型是由多个单独模型形成的复合模型。各个模型包括一个或多个:几何模型、纹理模型、头发模型和眼睛颜色模型。几何模型基于线性身份和表达基础,采用线性混合蒙皮控制眼睛、下巴和头部运动。为了从几何模型中采样,可以使用高斯混合模型。
纹理模型由反照率纹理和置换纹理组成。反照率纹理表示肤色,而置换表示褶皱和孔隙水平置换。头发模型由定义头发、眉毛和胡须的各个发束的曲线组成。眼睛颜色模型是基于示例的眼睛颜色采样器。
可以对上述各个模型进行单独采样,以获得可渲染的完整人脸标识。
面部设置完成后,将头显模型以遮挡感知的方式放置在合成头部。放置基于平均头部形状的手动放置,如果设备与头部相交,则调整平均头部形状。
为了模拟面向嘴巴的摄像头的照明和背景对象,高动态范围图像(HDRI)可用作场景的照明和背景。从库中为每个场景采样不同的HDRI,并可以选择每n帧旋转一次HDRI,以模拟头部旋转和背景运动。要对人脸捕捉设备进行建模,需要使用焦距、景深和分辨率来匹配头显真实人脸捕捉设备的属性。
表情系统的机器学习模型402使用带损失函数的监督训练进行训练,所述损失函数是训练示例的预测表情参数值和已知表情参数值之间差异的度量。在一个例子中,机器学习模型是一个卷积神经网络,并使用反向传播进行训练。
在各种示例中,表情系统神经网络的设计使得可以从大量不同的用户群体中以一般方式进行训练,然后适应具有最少数据的个人。
照片校准器412是一种机器学习模型,它将渲染图像410映射到照片级真实感图像414。可以使用成对的数据对光校准器的机器学习模型进行训练,每对数据包括从摄像头捕获的照片,并描绘具有表情的真实人员的正面视图,以及配置与表情对应的参数值时从3D人脸模型渲染的图像。

图5是具有中性姿势和中性表情的普通人的模板网格500,其中显示模板网格覆盖有光滑表面。首先基于个体的身份对模板网格500进行变形,以创建图5的502中所示的结果,结果是具有中性表情的特定个体的面部的三维模型。使用基于表情参数值的第二变形来变形图5的502中的结果,以给出图5的504中所示的结果,结果表示与502中相同的个体,但具有微笑和闭着眼睛的表情。当姿态参数的值添加时,结果显示在图5的506中,其中头部向后倾斜,头部向右转动,下巴打开。姿势参数设置眼睛以及颈部和下巴骨骼的姿势。
普通人的模板网格500旨在作为所有人脸的平均值,并有助于将专利所述技术泛化到不同的个人。
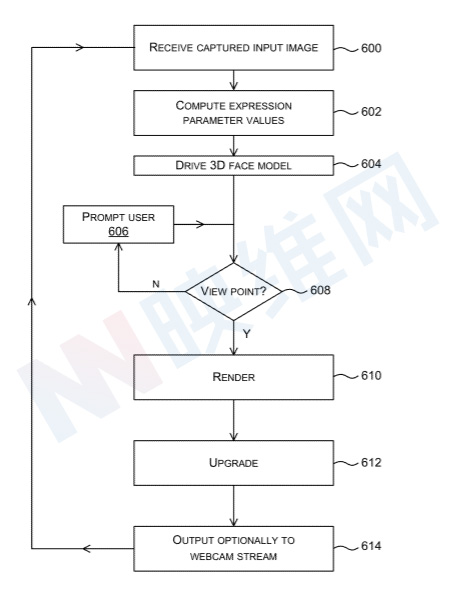
图6是用于计算头显用户面部图像的设备的操作方法的流程图。简单来说,首先从至少一个面向面部的捕获设备接收捕获的输入图像,然后再交由机器学习装置来计算补充被输入图像中被头显遮挡的部分,从而呈现完整的人脸图像。
相关专利:Microsoft Patent | Computing images of head mounted display wearer
名为“Computing images of head mounted display wearer”的微软专利申请最初在2020年6月提交,并在日前由美国专利商标局公布。