微软专利为VR头显MR透视提出机器学习选择性叠加图像内容解决方案
呈现透视合成图像
(映维网Nweon 2022年05月31日)对于当前VR头显支持的MR透视功能,其性能大多存在限制,用户体验不佳。另外,今天的技术需要多个摄像头,但这会导致额外的重量、成本和能耗。针对这个问题,行业正在积极探索各种解决方案。例如在名为“Using machine learning to selectively overlay image content”的专利申请中,微软就提出了一种利用机器学习来选择性叠加图像内容的方式。
概括来说,系统可以访问具有第一样式的第一图像,并访问具有第二样式的第二图像。在对样式进行深度神经网络(DNN)学习之后,将第一图像的副本作为输入馈送给DNN。DNN通过将第一图像副本从第一样式转换为随后的第二样式来修改第一图像副本。
结果,转换后的第一图像副本的修改样式双边匹配第二样式。通过这种方式,头显可以从一个图像中选择性地提取一个或多个部分,进行匹配的翘曲,并将所述部分叠加到另一个图像,从而呈现质量提升的透视合成图像。
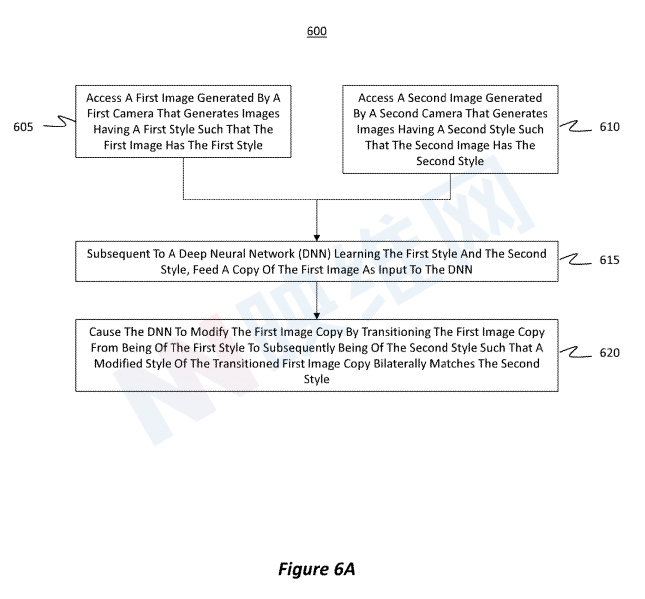
图6A示出了示例方法的流程图。方法600包括访问由第一摄像头生成的第一图像的动作(动作605),第一摄像头生成具有第一样式的图像。所述方法进一步包括访问由第二摄像头生成的第二图像的动作(动作610),第二摄像头生成具有第二样式的图像。
在DNN学习第一样式和第二样式之后,可以将第一图像的副本作为输入馈送给DNN的动作(动作615)。图7A是这种过程的示例。
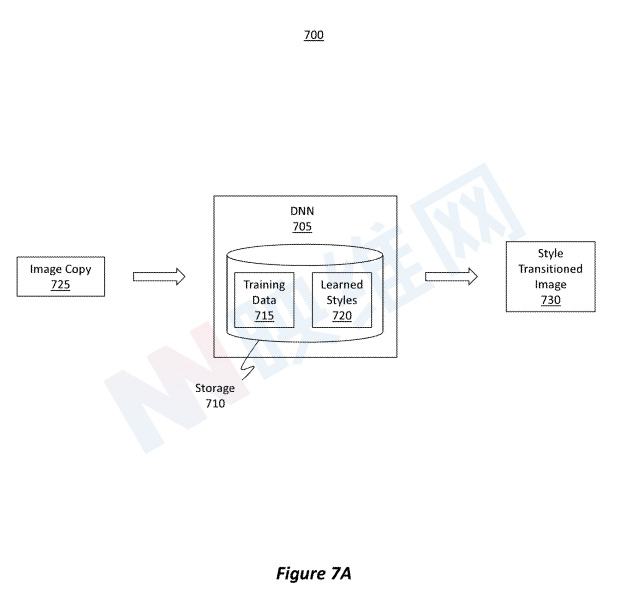
图7A示出了样式转换过程700。DNN 705接受过识别和应用不同样式的训练。例如,DNN 705包括包含用于训练DNN 705的训练数据715的存储器710或与之相关联的存储器710。根据训练数据715,DNN 705学习了样式720,可见光样式、微光样式和热数据样式。
图7A同时示出了图像副本725,其代表动作615中提到的第一图像的副本。图像的副本可用于保留原始图像而不修改原始图像。
返回图6A,动作620将第一图像副本从第一样式转换为随后的第二样式,从而允许DNN修改第一图像副本。因此,经过转换的第一图像副本的修改样式双边匹配第二样式。其中,双边匹配意味着一幅图像的特征、特征和编辑操作与另一幅图像的特征、特征和编辑操作相关联。
尽管特征、特征和编辑操作可能不完全相同,但它们充分相关(或与阈值量相关),以确保两个图像的结果样式彼此对应。
当然,可以执行相反的操作。例如,可以将第二图像的副本作为输入馈送到DNN。然后,可以通过将第二图像副本从第二样式转换为随后的第一样式,从而允许DNN修改第二图像副本,使得转换后的第二图像副本的修改样式与第一样式双边匹配。

如图6B进一步描述,第一图像和转换后的第二图像副本可以构成第一样式的第一立体图像对。另外,第二图像和转换后的第一图像副本可以构成第二样式的第二立体图像对。可以对第一图像和转换后的第一图像副本执行视差校正,以令第一图像和转换后的第一图像副本的透视图彼此对齐,并且与用户的瞳孔对齐。
同时,实施例可以对第二图像和经过转换的第二图像副本执行视差校正,以令第二图像和经过转换的第二图像副本的透视图彼此对齐,并与用户的另一个瞳孔对齐。
图7A示出DNN 705如何能够接收图像副本725作为输入并对图像副本725执行样式转换。样式转换将图像副本725的样式转换为新样式,从而创建新图像,如样式转换后的图像730所示。样式转换后的图像730具有与指示DNN 705将图像副本725转换为的样式相对应的样式。
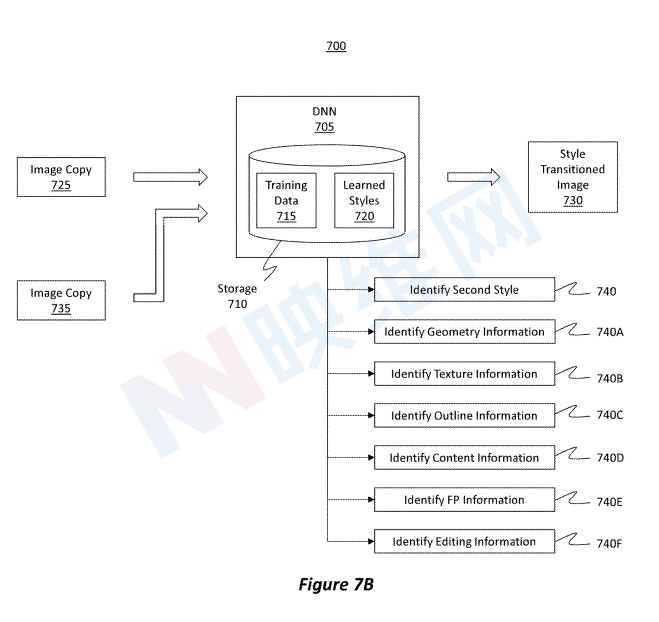
如图7B所示,另一图像的所选样式同时馈入作为输入到DNN 705。换句话说,除了图像副本725之外,可以将另一个图像或图像副本735同时馈送到DNN 705中。图像副本735的样式是DNN 705将图像副本725转换为的样式。
在接收到图像副本735后,DNN 705能够识别第二样式(动作740),所述样式对应于图像副本735的样式。如上所述,DNN 705的任务是将图像副本725的样式转换为第二样式。另外,DNN 705能够识别几何信息(动作 740A)、识别纹理信息(动作 740B)、识别轮廓信息(动作 740C)、识别内容信息(动作 740D)、识别特征点信息(动作 740E)和/或识别编辑信息(动作 740F)。
基于从图像副本735提取或学习的上述信息,DNN 705能够调整其初始学习数据,以便更充分地将图像副本725的样式转换为图像副本735中体现的样式。
因此,第二图像的副本可以作为输入馈送到DNN 705。作为响应,DNN 705随后可以执行一系列操作。例如,响应于接收第二图像副本和第一图像副本作为输入,DNN能够通过分析第二图像副本的属性来识别体现在第二图像副本中的第二样式。
例如,DNN能够基于第二图像副本捕获的透视识别几何信息,基于第二图像副本捕获的透视识别轮廓信息,通过分析第二图像捕获的纹理识别纹理信息等等。
基于从第二图像副本的属性识别第二样式的DNN,以及基于几何信息、轮廓信息、纹理信息或任何其他识别信息,DNN通过将第一图像副本从第一样式转换为随后的第二样式来修改第一图像副本,使得转换后的第一图像副本的修改样式双边匹配第二样式。
DNN能够接收两个不同样式的图像作为输入(例如第一样式的第一输入图像和第二样式的第二输入图像)。为了响应输入,DNN能够执行修改和转换以生成两个输出图像。例如,第一样式的第一输入图像转换为第二样式的第一输出图像,第二样式的第二输入图像转换为第一样式的第二输出图像。
方法600进一步包括将转换后的第一图像副本的选定部分叠加到第一图像,从而生成合成图像的动作(动作630)。或者,可以将第一图像的部分叠加到转换后的第一图像副本。换句话说,专利描述的实施例能够从一个图像中选择性地提取一个或多个部分,并将所述部分叠加到另一个图像上。
例如,如果第一个样式是可见光样式,第二个样式是热数据样式,则转换后的第一个图像副本包括热数据,使得至少一定的热数据叠加在第一个图像,并且合成图像包括可见光数据和至少一定的热数据。
当转换为另一种样式时,图像随后将包括另一种样式类型的数据。作为另一示例,可以将热数据叠加到可见光图像或弱光图像。随后,合成图像可以显示在头显显示器(动作635)。
方法600中讨论的第二图像和转换后的第一图像副本构成第二样式的立体图像对。由于这两幅图像是从不同的角度拍摄,并且这两幅图像将捕获至少一定的重叠内容,所以这两幅图像可用于执行立体深度匹配。
翘曲图像以准备叠加图像内容
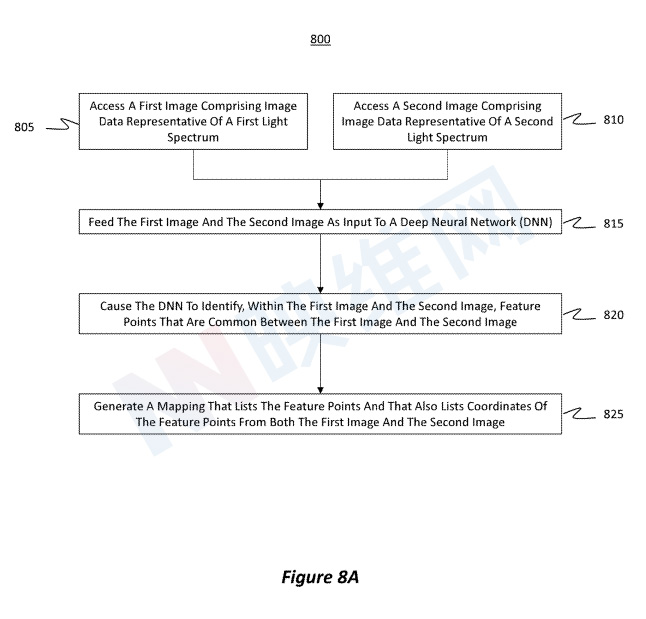
如上所述,头显可以配置为将来自一个图像的内容覆盖到另一个图像,以形成所谓的合成图像,然后可以将其显示给用户。图8A和8B示出了一个流程图,其中图像使用不同的光谱数据,以便在两个图像之间精确对齐或叠加内容。

方法800包括访问包含代表第一光谱的图像数据的第一图像(动作805)。另外,方法800包括访问包括代表第二光谱的图像数据的第二图像(动作810)。动作805和810可以彼此串行或并行地执行。
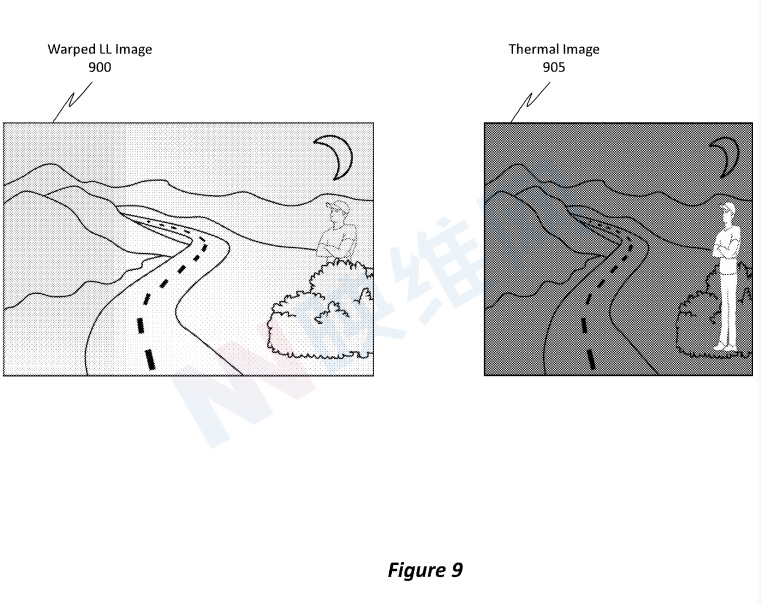
图9示出了可代表动作805中的第一图像的翘曲LL图像900和可代表动作810中的第二个图像的热图像905。翘曲的LL图像900标记为“翘曲”,因为已经对其应用了一个或多个变换。
例如,视差校正可以应用于图像,以确保翘曲LL图像900的透视图与用户瞳孔的透视图对齐,即翘曲LL图像900可以是视差校正图像。相反,变换尚未应用于热图像905。
比较这两幅图,我们可以看到热图像905比翘曲的LL图像900更小和更倾斜。由于所述的特征差异,如果直接将来自热图像905的内容叠加到翘曲的LL图像900,则内容会错位,并且产生的合成图像看起来是低质量图像。
针对这个问题,图8A的方法800包括将第一图像和第二图像作为输入馈送到深度神经网络(DNN)(动作815)。例如,图10示出了作为输入馈入DNN 1010的第一图像1000和第二图像1005。
返回图8A,然后DNN在第一图像和第二图像内识别(动作820)第一图像和第二图像之间共同的特征点。例如,假设第一个图像是弱光图像,第二个图像是热图像。在这种情况下,即使微光图像表示使用微光数据的环境,而热图像表示使用热数据的环境,DNN都能够识别特征点。
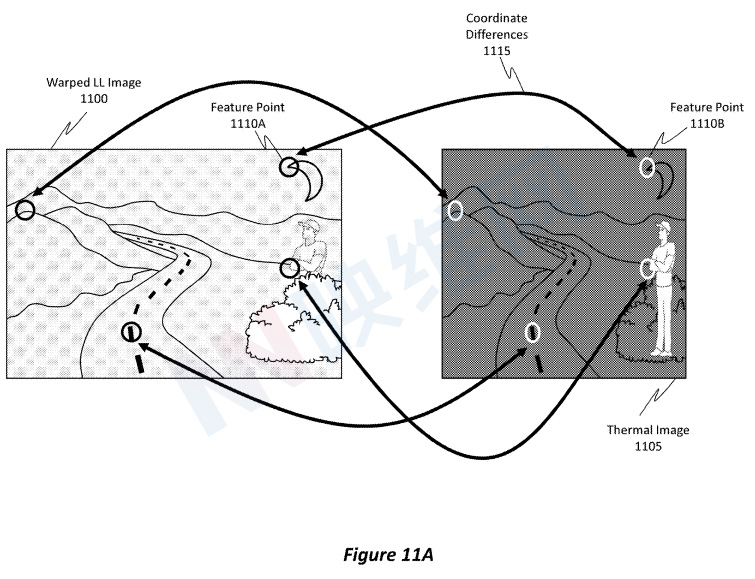
图11A提供了所述动作的有用说明。具体地,图11A示出了代表方法800中的第一图像的翘曲LL图像1100和代表第二图像的热图像1105。
图11A同时示出了DNN如何识别两个图像之间的对应特征点,例如特征点1110A和特征点1110B。即便翘曲的LL图像1100和热图像1105包括不同类型的数据,DNN都能够分析这两个图像的特征,并识别这两个图像中通常表示相同对象或特征的特征点。
返回图8A,可以生成映射(动作825),其中映射列出了特征点,并且列出了来自第一图像和第二图像的特征点的坐标。图10示出DNN 1010如何能够生成对应映射1015。另外如图11A所示,DNN能够识别两个图像之间的坐标差1115。即,特征点1110A位于翘曲LL图像1100内的特定像素坐标集处。
类似地,特征点1110B位于热图像1105内的特定像素坐标集处。由于两幅图像的大小、几何结构或潜在的透视角度不同,坐标可能会不同,但DNN能够识别差异,如坐标差异1115所示。
另外,DNN 1010能够识别两幅图像特征之间的差异。所述差异至少反映了可能已经对翘曲的LL图像900执行的任何不同翘曲1020,亦即为校正视差而执行的任何翘曲或变换。如前所述,翘曲1020包括但不限于倾斜、旋转、平移等。
然后,方法800可包括翘曲第二图像的动作(动作835),以使第二图像中特征点的坐标对应于第一图像中特征点的坐标。实施例能够翘曲第二(或第一)图像,使图像中的特征点坐标与另一图像中的特征点坐标相对应。翘曲第二图像可以包括对第二图像执行以下任何操作:拉伸操作、收缩操作、倾斜操作、旋转操作、平移操作或缩放操作。
另外,所述实施例能够显示合成图像,合成图像包括第二图像叠加在第一图像相应部分的的选定翘曲部分。举例来说,第二图像可以是微光图像或热图像。实施例能够分析第二图像以识别明亮区域和/或“热”区域(或冷区域)。可以选择、提取识别区域,然后将其叠加到第一图像的相应部分。在
在一个实施例中,为了改进翘曲过程,实施例可以另外向DNN馈送第三图像。第三图像可对应于第一图像,但第三图像可能尚未进行任何视差校正。通过所述输入,DNN能够识别在视差校正操作期间对第一图像的特征点所做的更改,然后可以将相关更改应用于第二图像中的特征点。
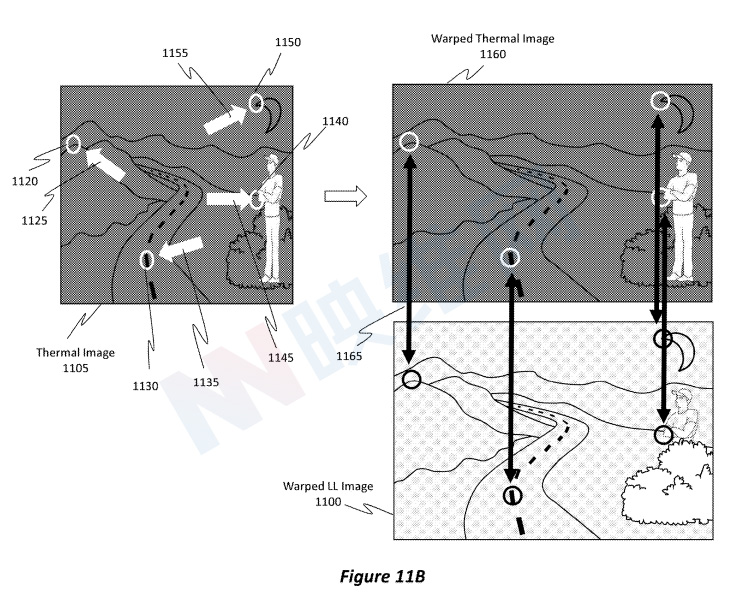
图11B显示了翘曲的LL图像1100和热图像1105。在这两幅图像中,可以识别出任意数量的对应特征点。然后,实施例翘曲特征点,使得特征点的定位在两个图像之间彼此对齐。
例如,特征点1120正在翘曲1125,以向左和向上推动。特征点1130正在翘曲1135,以向左和向下推动。特征点1140正在翘曲1145,以向右推动。特征点1150正在翘曲1155,以向上和向右推动。需要注意的是,所述翘曲是二维翘曲,而不是三维几何翘曲(如依赖深度的视差校正)。
在任意数量的特征点执行翘曲操作后,生成翘曲热图像1160,其中翘曲热图像1160与翘曲LL图像1100相对应或对齐。如对应1165所示,翘曲热图像1160中的山的特征点位于与翘曲LL图像1100中的山相同的像素坐标。现在,翘曲的热图像1160与翘曲的LL图像1100对齐(像素方向)。
相关专利:Microsoft Patent | Using machine learning to selectively overlay image content
名为“Using machine learning to selectively overlay image content”的微软专利申请最初在2022年2月提交,并在日前由美国专利商标局公布。