微软发布预训练的类人控制模型库MoCapAct,助力人工仿人控制的高级研究
发布了一个预训练的类人控制模型库MoCapAct
(映维网Nweon 2022年09月05日)要令两足人形机器人像摇滚歌手米克·贾格尔一样跳舞需要什么?实际上,即便是令它们简单地站起来,自由行走,或者以其他我们认为理所当然的方式移动都是一个挑战。
为了帮助社区实现仿人控制的高级研究,微软和佐治亚理工学院日前发布了一个预训练的类人控制模型库MoCapAct,从而允许研究人员以传统方法所需计算资源的一小部分来实现人工仿人控制的高级研究。

在为人类设计的环境中,两足行走提供了无与伦比的多功能性。通过混合和匹配广泛的基本运动技能,从步行到跳跃到单脚平衡,人们可以跳舞、踢球、以及进行其他复杂的高水平运动。如果机器人要充分发挥其作为辅助技术的潜力,掌握各种两足运动是一项重要要求。
然而,即便是上述技能中最简单的一项,其都需要数个关节的精细编排。复杂的工程可以控制这种复杂性,但要令两足机器人具备通用性,或是后继的元宇宙,它显然需要进行学习。训练具有人形形态的人工智能代理,并使其在整个人类运动多样性中匹配人类的表现,这是人工物理智能的最大挑战之一。由于物理机器人实验的变化无常,目前这方面的研究主要是在仿真中进行。
遗憾的是,它涉及计算密集型方法,从而限制了研究社区的参与。针对这个问题,微软研究院的机器人学习小组和佐治亚理工学院发布了一个大型的预训练类人控制模拟库MoCapAct,从而允许研究人员以传统方法所需计算资源的一小部分来实现人工仿人控制的高级研究。
人形机器人控制研究的计算资源要求非常高。学习运动技能的主要途径是使用动捕MoCap。MoCap这种动画技术在过去数十年中广泛应用于娱乐行业。它包括在演员执行任务(如慢跑)时记录其身体上的多个关键点的运动,如肘部、肩部和膝盖。
因此,MoCap片段认为是人体运动非常简洁和精确的总结。由于这一点,与机器学习的其他主要领域中的训练数据相比,可以用更少的计算从MoCap片段中提取有用的信息。除此之外,MoCap数据广泛可用。CMU运动捕捉数据集等存储库包含人体任何常见运动的数小时片段,下面显示了数个示例的可视化。所以,为什么仿人机器人模仿人类动作如此困难呢?
需要注意的是,MoCap片段不包含在物理机器人上或在模拟物理力的模拟中模拟演示运动所需的所有信息。它们只向我们展示了动作技能的样子,而不是导致演员肌肉产生动作的潜在肌肉运动。
即便MoCap系统记录了相关信号,其都不会有多大帮助:模拟人形机器人和真实机器人通常使用电机而不是肌肉,这是一种截然不同的关节形式。尽管如此,仿人机器人的驱动都由一种控制信号驱动。如果与使用MoCap数据作为指导的其他学习和优化方法相结合,则MoCap片段是计算控制信号的有价值辅助工具。
微软和佐治亚理工学院希望通过MoCapAct消除的计算瓶颈正是由所述方法带来,亦即强化学习(RL)。在模拟中,大部分人工智能运动研究目前都集中于此,RL可以通过给定的MoCap片段中的姿势序列来恢复控制输入序列。结果是一种与MoCap片段无法区分的运动行为。
从单独的MoCap片段中学习的单个基本行为的控制策略可以为运动研究打开大门,例如,将所述行为组合成单个“多技能”神经网络,并通过在它们之间切换来训练更高级别的运动能力方法。然而,由于需要学习数千种基本的运动技能,RL昂贵的试错法为进入这一研究路径造成了巨大障碍。所以,微软和佐治亚理工学院希望通过MoCapAct数据集解决这个问题。
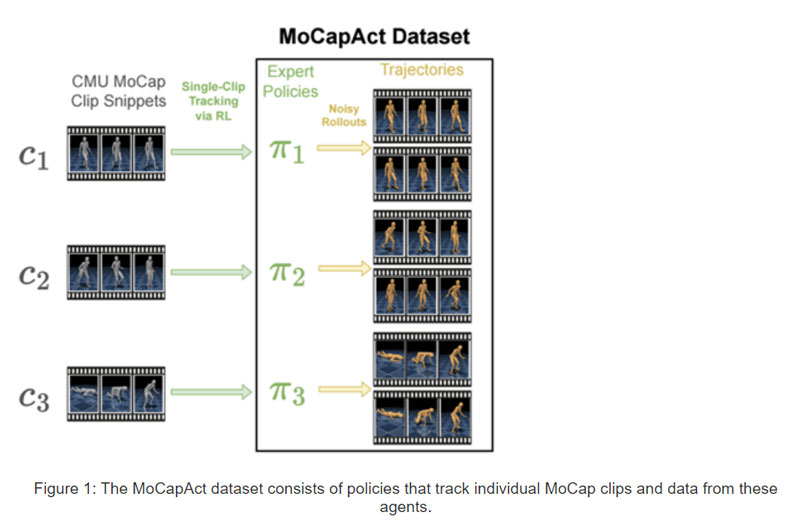
MoCapAct数据集旨在与高度流行的dm_control类人仿真环境和广泛的CMU运动捕捉数据集兼容,并以两种方式服务于研究社区:
-
对于来自CMU运动捕捉数据集的2500多个MoCap剪辑片段中的每一个,它提供了一个RL训练的“expert”控制策略(表示为PyTorch模型),使得dm_control的类人机器人能够忠实地再现剪辑片段中描述的技能:
-
对于上述每一个训练过的技能策略,MoCapAct提供了一组记录的轨迹,而所述轨迹是通过在dm_control的类人代理执行技能的控制策略生成。轨迹可以认为是训练有素的expert MoCap片段。但它与原始MoCap数据的一个关键区别是,它们既包含low-level感官测量,又包含拟人智能体的控制信号。与典型的MoCap数据不同,所述轨迹适合于通过直接模仿学习匹配和提高技能。这是一种比RL更有效的技术。
团队给出了两个如何使用MoCapAct数据集的示例。
首先,他们训练基于神经概率运动基元的分层策略。为了实现这一点,研究人员将数千个MoCapAct的剪辑专用策略组合到一个能够执行多种不同技能的单一策略中。代理具有一个将MoCap帧作为输入并输出学习的技能的high-level组件。low-level组件则将人形机器人学习的技能和感觉测量作为输入,并输出运动动作。
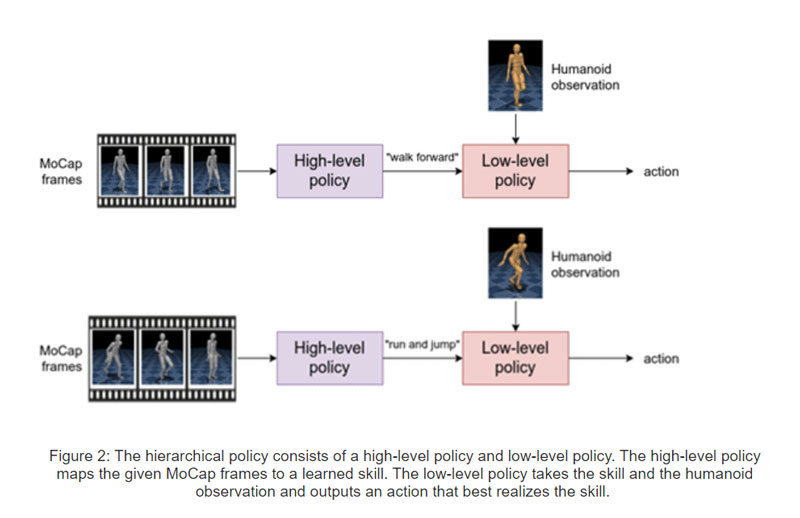
这种分层结构提供了一个重要的好处。如果保留low-level组件,他们可以通过向low-level策略输入不同的技能来控制仿人机器人。因此,可以重新使用low-level策略来有效地学习新任务。
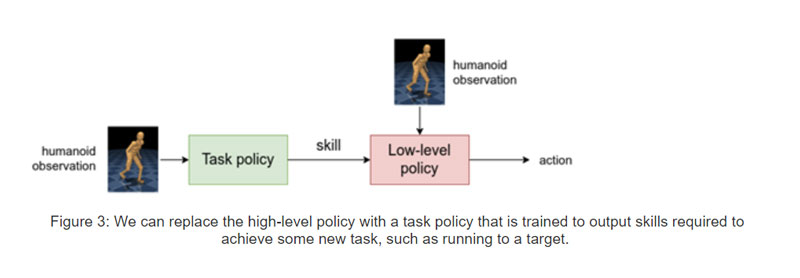
有鉴于此,他们用任务策略取代high-level策略,然后对任务策略进行训练,以引导low-level策略实现特定任务。下面是一个示例。请注意,人形机器人使用了一系列的low-level技能,如跑步、转弯和侧步。
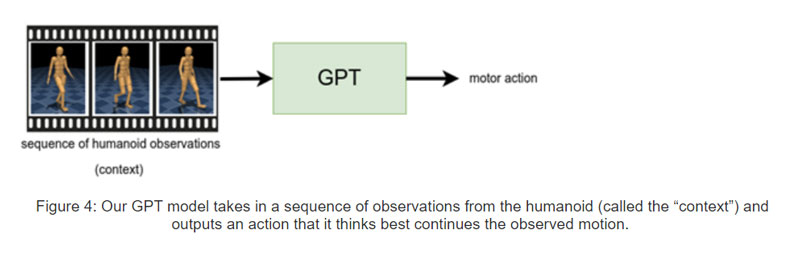
第二个示例以动作完成为中心,这是受sentence completion任务的启发。这里,研究人员使用GPT架构,它接受一系列感官测量并输出一个运动动作。他们训练一种控制策略,从数据集中获取一秒钟的感觉测量,并从expert那里输出相应的运动动作。然后,在对人形机器人执行策略之前,首先通过执行expert一秒钟来生成“提示”(视频中的红色人形机器人)。
之后,令策略在每个时间步控制人形机器人(视频中的青铜人形机器人),它不断地进行前一秒的感官测量并预测运动动作。团队发现,所述策略可以可靠地重复剪辑片段的基本运动。
相关论文:MoCapAct: A Multi-Task Dataset for Simulated Humanoid Control
除了数据集,团队同时发布了用于生成策略和结果的代码。更多信息请访问相关官网。