微软AR/VR专利分享用谐振LC传感器+机器学习来识别面部表情
识别面部表情
(映维网Nweon 2023年07月25日)除了眼动追踪,面部追踪同样开始成为XR头显的标配。但如果是使用摄像头进行检测,所述组件可能会遮挡眼睛的视图,并进一步影响可穿戴设备的视觉设计。
所以为了避免使用摄像头来追踪面部表情,在名为“Interpretation of resonant sensor data using machine learning”的专利申请中,微软就介绍了一种利用谐振式电感-电容LC传感器和机器学习方法来识别面部表情的方法,这家公司指出,谐振式LC传感器代替摄像头进行面部追踪,从而可以减小传感设备的尺寸、重量、成本和/或功耗。
在一个实施例中,专利描述的头显设备可以配置为识别面部表情并将其作为用户输入。为了避免使用摄像头来追踪面部表情,可以利用谐振式LC传感器。其中,每个谐振式LC传感器配置为输出响应于靠近谐振式LC传感器的表面积位置的信号。
每个谐振LC传感器包括配置用于近场电磁检测的天线和谐振电路,而谐振电路包括天线、放大器和振荡器。每个谐振式LC传感器通过在天线产生振荡信号并检测谐振式LC传感器在选定频率下的近场响应来操作。谐振LC电路的谐振频率作为感测表面的天线接近度的函数而变化,从而允许表面相对于被感测天线的位置发生变化。
同时,可以利用经过训练的机器学习函数从谐振LC传感器输出确定潜在的面部表情。然后,确定的面部表情可以用作计算系统的输入。例如,确定的表情可以用来控制计算设备的功能,或者将其映射至Avatar。
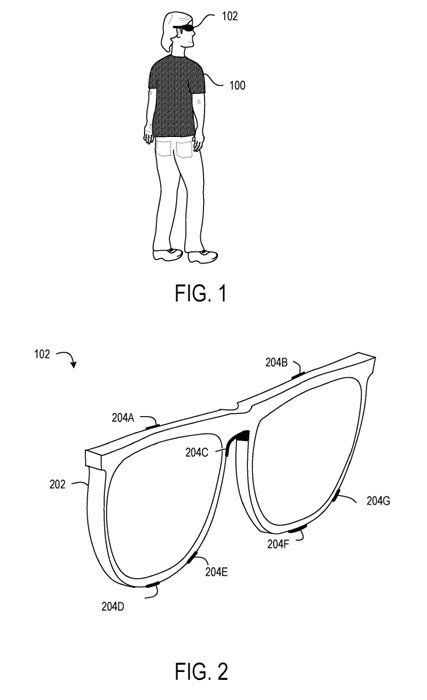
图1示出了佩戴头显的的用户100,所述头显包括用于面部追踪的谐振LC传感器。图2示出适于与传感组件102一起使用的示例框架202。框架202包括空间分布在框架202上的多个谐振LC传感器204A-G。每个传感器可以配置为感测脸部的不同部分,例如左眉、右眉和鼻子。
每个谐振式LC传感器204配置为输出信号,而所述信号提供有关靠近相应谐振式LC传感器的面部位置的信息。使用谐振式LC传感器代替摄像头进行面部追踪,从而可以减小传感设备102的尺寸、重量、成本和/或功耗。
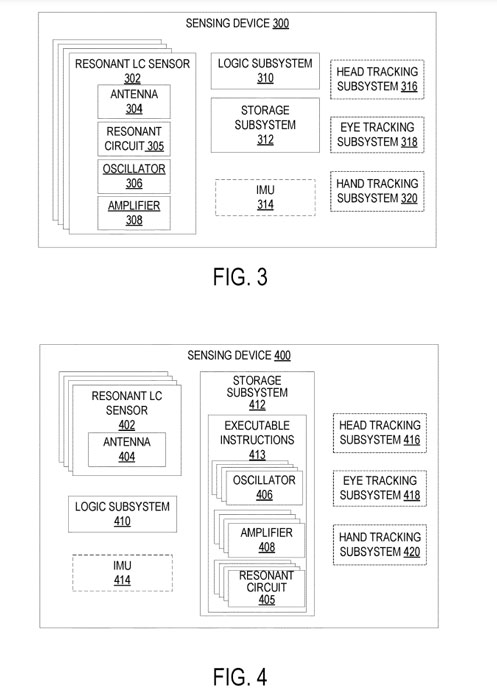
图3示出了示例性传感组件300的框图。传感组件300包括多个谐振LC传感器302,每个传感器配置为输出响应于与相应谐振LC传感器相邻的表面位置的信号。每个谐振LC传感器302包括天线304、谐振电路305、振荡器306和放大器308。谐振电路305包括天线304的电容和/或电感与一个或多个其他无功元件组合。
天线304用于近场电磁探测。在一个实施例中,天线304可包括质量因子在150至2000范围内的窄带天线。使用这种窄带天线可以提供比具有较低质量因数的天线更高的灵敏度。所述振荡器306和放大器308被配置为在天线304产生振荡信号,所述天线304检测近场响应,近场响应随所述被感测表面相对于所述天线304的位置的函数而变化。
在一个实施例中,选择振荡信号与谐振式LC传感器的目标谐振频率有一定的偏移,因为这样的配置可以提供比振荡信号更经常处于谐振式LC信号的谐振频率更低的功率操作。
传感组件300同时包括逻辑子系统310和存储子系统312。逻辑子系统310可以配置为使用机器学习方法检测面部表情。例如,存储在存储子系统312中的指令可以配置为使用训练过的机器学习函数将传感器输出映射到面部姿态。
传感组件300可进一步包括可选的惯性测量单元314。来自IMU 314的IMU数据可用于检测感测组件的位置变化。
图4示出另一示例感测组件400。传感组件400包括多个谐振LC传感器402,每个传感器包括天线404。天线404可以类似地配置为图3中所示的天线。
但与传感组件300相反,传感组件400包括由逻辑子系统410可执行的存储指令413,以实现对于每个谐振LC传感器402,谐振电路405,振荡器406和放大器408。传感组件400可以进一步包括可选IMU 414,如上所述的关于传感组件300。
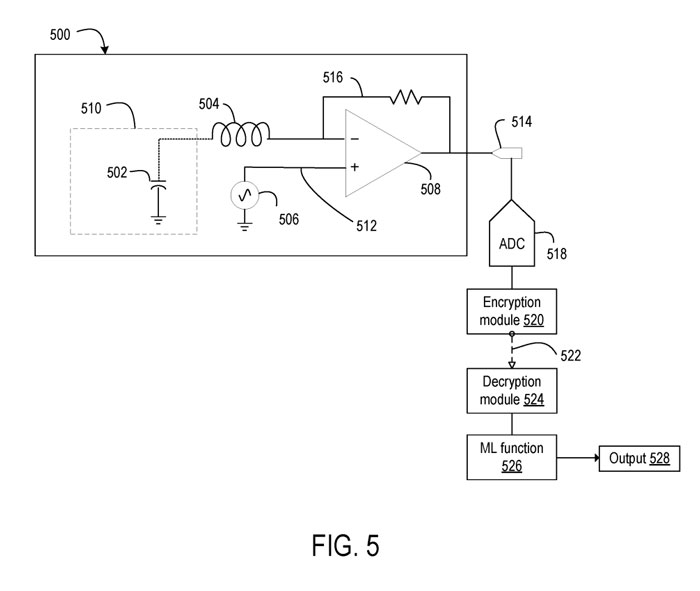
图5示出示例谐振LC传感器500的电路图。谐振式LC传感器500是传感组件300的谐振式LC传感器的示例。谐振LC传感器500包括电感504、振荡器506、放大器508和天线510,天线包括电容,电容502表示。所述振荡器506配置为在节点512上输出被驱动信号,所述放大器508配置为根据通过反馈回路516在节点512接收到的被驱动信号在天线中产生振荡信号。
天线510的电容502与电感504一起构成串联谐振器。天线510的电容是靠近天线510的表面的函数,因此根据靠近传感器的表面位置的变化而变化。在一个实施例中,可以包括单独的电容器以向谐振电路提供额外的电容,例如,将谐振电路调谐到选定的谐振频率。
谐振LC传感器500输出的信号通过模数转换器(ADC) 518转换为数字值。在一个示例中,来自ADC 518的数据在本地处理,而在其他示例中,来自ADC的数据远程处理。在任何一种情况下,可以通过在将数据发送到另一设备之前通过加密模块522对来自ADC 518的数据进行加密,从而进一步处理维护面部追踪数据的隐私。
面部追踪传感器数据可能在转换为数字值后进行加密,这有助于防止黑客攻击并保护用户数据隐私。由于来自每个传感器的信息是一维的(例如电压信号或电流信号),并且传感器的总数相对较少,因此来自谐振LC传感器系统的面部追踪传感器数据的加密效率相对较高。
相比之下,使用摄像头的面部追踪系统的图像数据可能需要使用更多的资源来加密,因为每个通道有诸多像素,在彩色图像数据的情况下则需要众多颜色通道。面部追踪数据的相对低维度可以允许加密以足够的采样率有效地执行,以实时追踪面部表情,而不会像使用图像传感器那样影响功耗。
通过通信通道522发送的面部追踪数据由解密模块524解密,然后输入到经过训练的机器学习函数526中分类为面部表情。在各种示例中,解密模块524和机器学习功能526可以位于传感器500所在的设备的本地,或可以远离传感器500所在的设备。对于该函数识别的每个面部表情,机器学习函数526确定输入数据代表该面部表情的概率。从概率中,输出一个确定的面部表情,并用作计算设备的输入。
机器学习函数526可以使用针对多个不同面部表情中的每一个或多个用户中的每一个的标记谐振LC传感器数据进行训练。机器学习函数526可以使用与谐振LC传感相关的其他变量进行训练。
获得用于训练机器学习函数526的标记训练数据是一项重要的任务。因此,合成训练数据的产生可能比使用物理训练数据更有效。
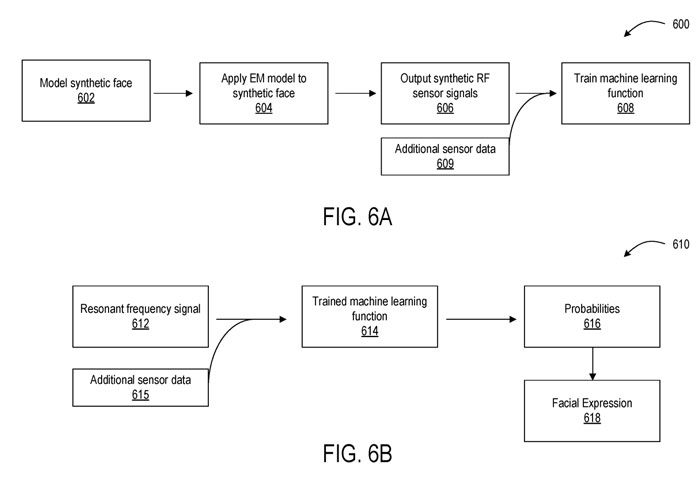
图6A示意性地示出了一种示例合成训练方法600。在602,合成训练方法600包括对合成人脸进行建模以表示来自不同人群的面部表情。接下来,将包含一个或多个谐振LC传感器的面部追踪设备的电磁特性建模的电磁模型应用于合成面部604。
电磁模型对传感器的电路元件、应用于被建模传感器的信号以及建模传感器相对于面部的位置进行建模,并针对不同的面部表情输出一组合成谐振频率(RF)传感器信号606,其中所述合成RF信号模拟由所述合成面部再现的面部表情产生的RF信号。
然后可以用合成数据训练机器学习函数,如608所示。训练后的机器学习函数可以使用任何合适的机器学习算法,包括但不限于期望最大化、k近邻、极限学习机、神经网络如循环神经网络等等。
额外的传感器数据609,如手部追踪、头部追踪、注视点追踪、图像、音频、IMU和/或环境数据可以进一步用作输入,以帮助训练机器学习功能。使用额外的传感器数据以及谐振LC传感器数据可能有助于提供情景和/或过滤噪点,从而提高确定面部表情的准确性。
例如,IMU数据可能表明,面部追踪传感器信号的变化是由于用户行走或移动头部时的头显运动,而不是由于故意的面部表情。作为另一个例子,眼动追踪可以帮助持续地提供用户头部中心的位置,从而提供从头显到用户头部的绝对距离。在这样的例子中,机器学习函数可以用这些额外的传感器数据进行训练。
上述数据可以与谐振LC传感器数据融合,然后使用任何合适的数据融合方法输入到机器学习函数中。例如,通过摄像头获取的运动追踪数据可以处理以识别运动,并且表示已识别运动的数据可以与谐振LC传感器数据连接,从而输入到机器学习功能中。
来自谐振LC传感器系统上的惯性测量单元的惯性运动数据同样可以与RF传感器数据连接以输入到机器学习功能中。
经过训练后,训练好的机器学习函数可以用于在部署阶段对面部追踪传感器数据进行分类。如图6B中的方法610所示。方法610包括在612处从一个或多个谐振LC传感器获得信号。
如上所述,可以以加密形式接收信号,然后对其进行解密。然后将信号输入到经过训练的机器学习函数614中。
基于所述输入数据,所述训练的机器学习函数输出概率616,所述输入数据表示所述函数训练以分类的多个面部表情中的每一个。
为了识别面部手势,可以将来自谐振LC传感器的时间数据输入到机器学习功能中。在其他示例中,可以输入单个帧,并且机器学习功能随时间输出的面部姿势变化可用于识别面部姿态。
可以选择具有最高概率的面部表情作为确定的面部表情以用作计算设备输入618。在一个示例中,可以为所确定的面部表情确定置信度,如果置信度不满足置信度阈值,则可以丢弃结果。
在其他实施例中,可以将时间阈值应用于面部姿势以排除微表情,因为微表情是自发和短暂出现的表情,因此不太可能表示预期的计算设备输入。
在一个实施例中,面部表情可能与设备功能有预先确定的映射关系。可以将计算设备配置为接收面部表情到设备功能/控制输入的用户定义映射的输入。允许用户定义的映射有助于进一步个性化用户体验。
另外,用户定义的映射可用于使计算设备的控制适应用户的特定能力。通过面部表情进行的控制输入同时可用于控制与传感设备通信的其他设备,例如家庭或工作场所环境中的设备。
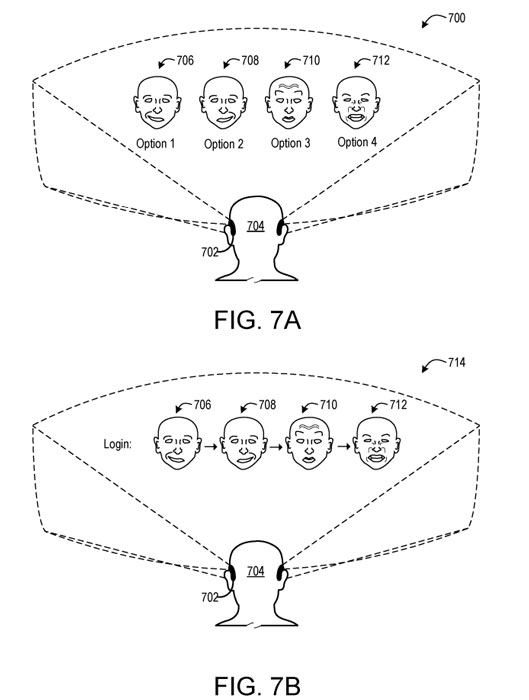
在一个实施例中,可以显示Avatar以向用户提供一个或多个指导和视觉反馈。图7A显示了一个示例使用场景700,其中用户704所佩戴的头戴式显示设备702正在显示多个Avatar,
Avatar的表情706、708、710、712可以作为显示的可选计算设备功能菜单的一部分一起显示。在所述示例中,可以通过执行相关的显示的面部表情来选择计算设备功能。在另一示例中,如图7B所示,表情706、708、710、712显示为面部表情序列,由用户按顺序执行以触发特定的可选输入。检测序列的性能可以表明用户704打算触发关联的可选输入的高可能性。
面部表情可以用于用户身份验证。在这样的示例中,Avatar可以显示一个或多个面部表情,并且用户可以模仿所述表情。
可以对谐振LC传感器数据进行分类,以确定是否执行了表情,并将其与先前存储的表情用户数据进行比较。如果传感器数据与图示表情不匹配和/或与先前为用户存储的传感器数据不匹配,则设备可能保持锁定状态。这可能有助于防止潜在的未经授权的用户访问设备。
检测到的面部表情同时可以用于与他人交流,以表达情感。例如,Avatar可以呈现为执行第一用户的面部表情,以便在远程设备呈现给第二用户。在这样的示例中,关于第一用户的面部表情的分类的信息可以作为情感表情发送到远程设备,以通过表示第一用户的Avatar显示给第二用户。
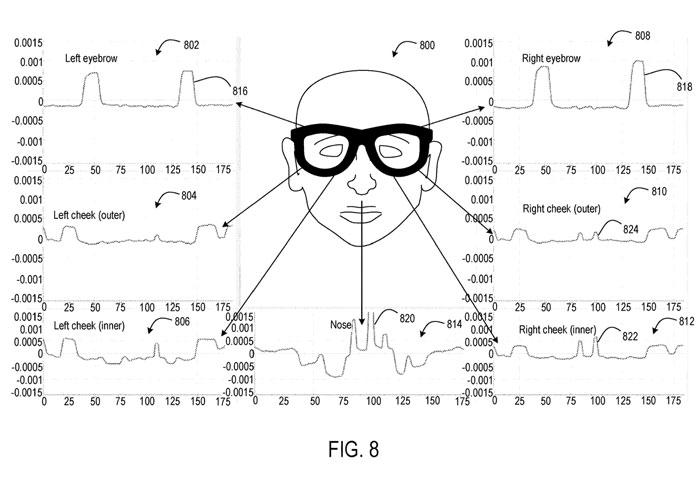
图8显示了通过头显谐振LC传感器收集的示例性实验性面部追踪传感器数据。
戴着头显的用户在图表显示为800。每个谐振LC传感器配置为感知用户面部的不同部分。图例描述了用于左眉(802)、左外颊(804)、左内颊(806)、右眉(808)和鼻子(814)的示例信号。信号波形中的峰值和上升表示在面部区域中检测到的用户面部运动。
举个例子,信号峰值为816的左眉和818的右眉表示用户在这个实验中抬起了两个眉毛。鼻子的信号峰值为820,右内颊的信号峰值为822,右外颊的信号峰值为824,这表明用户在脸的右侧在笑。
相关专利:Microsoft Patent | Interpretation of resonant sensor data using machine learning
名为“Interpretation of resonant sensor data using machine learning”的微软专利申请最初在2021年11月提交,并在日前由美国专利商标局公布。