微软专利介绍控制计算机生成表情的方法,提高Avatar社交性
控制计算机生成表情
(映维网Nweon 2023年12月05日)当前的Avatar存在各种缺点。例如,人们依赖于看到对方的面部表情作为一种交流方式,而大多数Avatar在交谈过程中没有提供用户表情的指示。
在两份同名为“Controlling computer-generated facial expressions”的专利申请中,微软介绍了一种控制计算机生成表情的方法,从而提高Avatar的社交性。
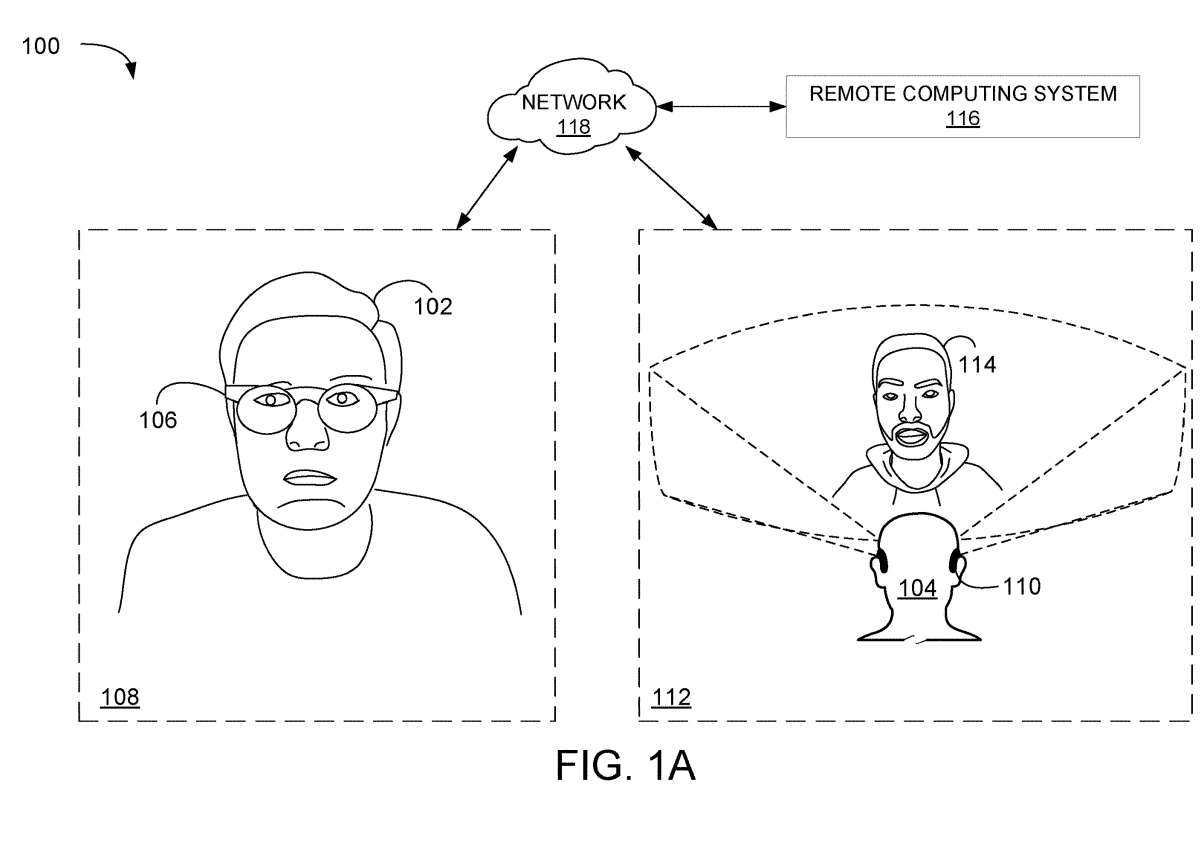

图1A和1B的示例场景使用Avatar来呈现计算机生成面部表情。在AR/VR环境100中,第一用户102和第二用户104正在通信。
在所描述的示例中,第一用户102在第一位置108使用第一头戴式设备106,第二用户104在第二位置112使用第二头戴式设备110。第二头戴式设备110显示代表第一用户102的Avatar114。
Avatar 114显示的计算机生成面部表情至少部分基于通过第一头戴式设备106的传感器获得的传感器数据。来自第一个头戴式设备106的面部追踪传感器的信号在运行时解释,并将信号映射到代表Avatar面部表情的混合形状。
混合形状映射用于获取表情数据,然后将其提供给一个或显示设备。显示设备可以使用表情数据来显示Avatar的面部表情,包括动画。
第一头戴式设备106包括多个面部追踪传感器,其中每个面部追踪传感器被配置为检测第一用户102面部的位置与传感器的接近程度。面部追踪传感器可以定位于接近第一用户102面部的各种位置,例如左右眉毛、左右脸颊和鼻梁。
在一个实施例中,可以使用多个传感器来感知眉毛上的不同位置,脸颊上的不同位置等,从而获得更详细的数据。来自多个面部追踪传感器的数据共同表示第一用户102的面部表面配置,以提供有关第一用户102的表情的信息。
在一个实施例中,第一头戴式设备106可以包括其他传感器,例如眼动追踪摄像头和/或惯性测量单元,并可分别用于确定眼睛凝视方向和/或头部姿势,以分别控制Avatar的眼睛和/或头部。
所确定的表情数据提供给第二头戴式设备110,以控制Avatar114的面部动画。因此,在图1A中,Avatar114具有与第一用户102的第一面部表情相对应的第一面部表情。参照图1B,在稍后的时间,Avatar114具有与第一用户102的第二相应面部表情相对应的第二面部表情。
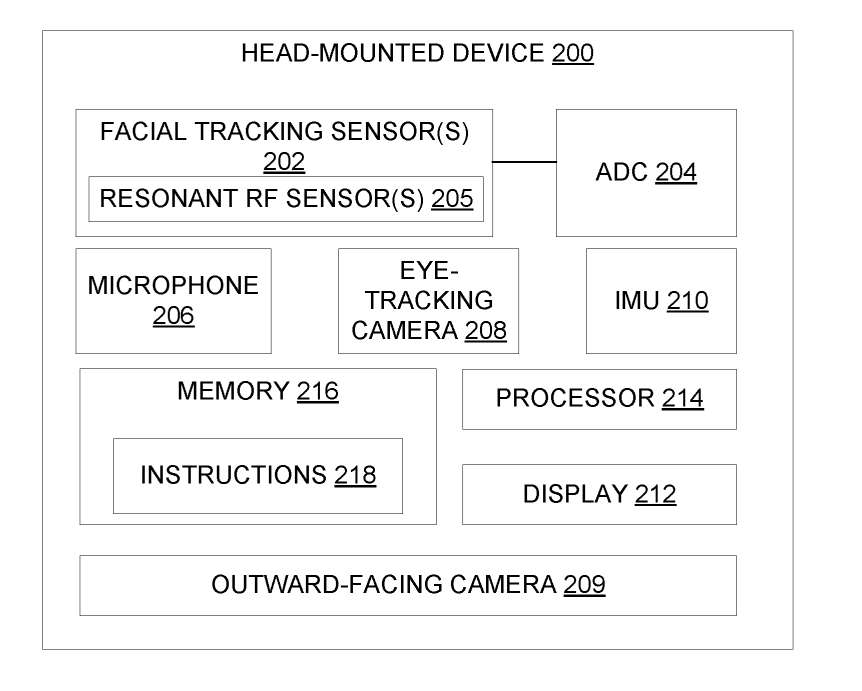
图2示出示例头戴式设备200的框图。第一和第二头戴式设备106和110是头戴式设备200的实例。头戴式设备200包括一个或多个面部追踪传感器202和模数转换器ADC 204,配置为将模拟传感器值从面部追踪传感器202转换为数字传感器值。
传感器值表示从中获得该值的面部追踪传感器与面部表面的接近程度。在一个实施例中,一个或多个面部追踪传感器202可包括谐振射频传感器205。在其它示例中,面部追踪传感器202可包含另一合适的非摄像头传感器。例如雷达传感器和超声波传感器。
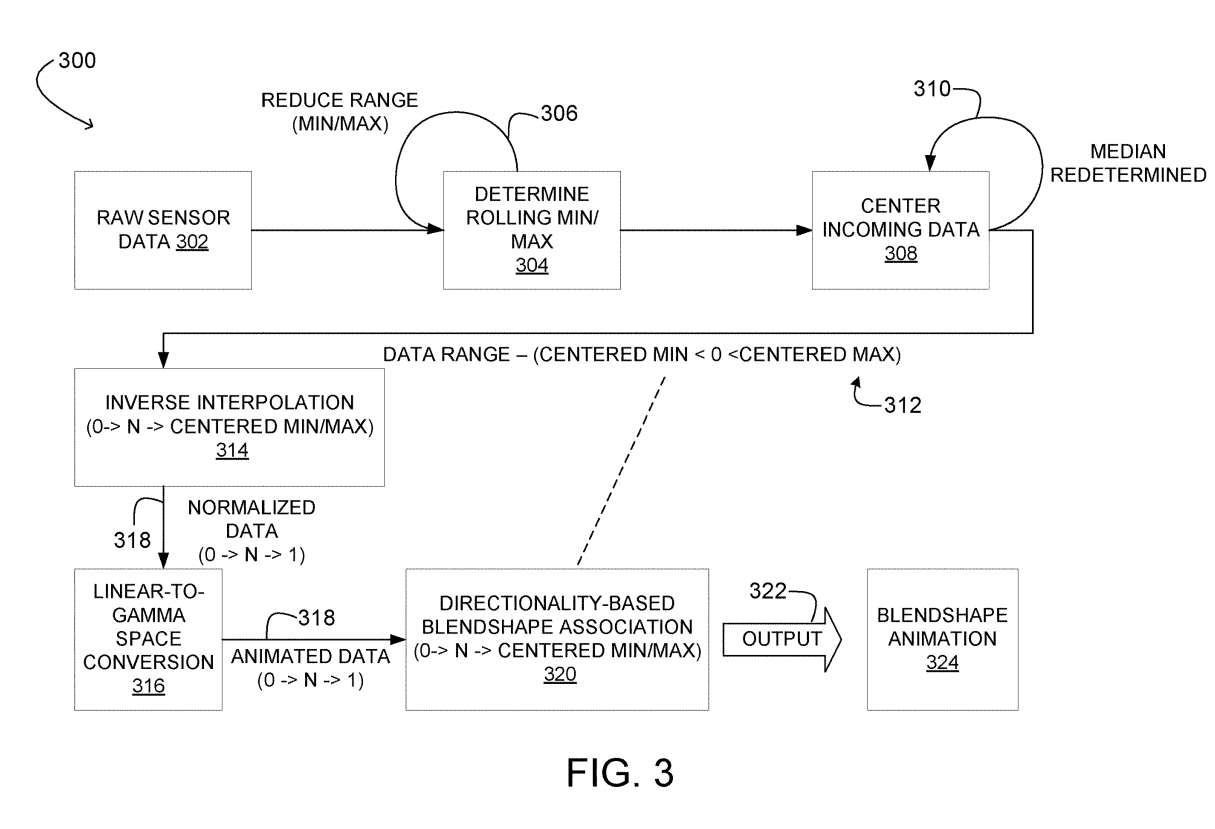
图3示出用于控制计算机生成面部表情的示例管道300。管道300配置为估计与人脸的运动范围相对应的传感器值范围,然后根据确定的范围解释传感器值以将传感器值映射到混合形状。
管道300接收由面部追踪传感器获得的原始传感器数据,如302所示。在所描述的示例中,原始传感器数据表示从ADC接收的数字传感器值。为简单起见,管道300用于描述从单个面部追踪传感器接收的数据。可以理解的是,管道300可以全部或部分复制通过每个额外的面部追踪传感器获取的传感器数据。
管道300决定304处的滚动最小值和滚动最大值传感器值。在一个实施例中,为了帮助排除外围信号,管道300周期性地减小滚动最小值和滚动最大值之间的范围,如306所示。
作为一个例子,滚动最小值和滚动最大值可以通过取中值和分别加/减最小/最大值的¼来重新评估。作为另一个例子,最小/最大窗口的中间80%可以用于下一个时间窗口。范围缩小可以在任何合适的频率进行。
在一个例子中,范围以每5到15秒一次的频率缩小。在其他示例中,校准步骤可以建立最小/最大值。在另外的例子中,范围可以以任何合适的方式和/或在任何合适的频率进行调整。
继续,管道300将传入数据集中在308。所述数据可包括在310处确定一个滚动中值传感器值,以及定心滚动最小值和定心滚动最大值。滚动中值可以定期更新,如310所示。在一个示例中,滚动中值可能以每1到5秒的频率更新一次。在其他示例中,可以使用任何其他合适的更新频率。
如312所示,所得到的数据包括值在居中最小值和居中最大值之间的数据,其中居中最小值小于零,居中最大值大于零。
中心传感器值评估面部运动的方向性,例如扬起或放下眉毛。方向性可以根据中心传感器值是低于零还是高于零来确定。这样,管道300可以确定传感器值与混合形状映射之间的方向关系。
在一个实施例中,可以执行校准步骤以确定传感器的方向性,例如眉毛、上脸颊或其他合适的面部组,因为面部追踪传感器的方向性数据对于不同的用户不同。在这样的示例中,校准步骤可以包括引导体验,其中可以引导用户执行表情,以便可以为一个或多个面部追踪传感器获得方向性关联。
在其他示例中,图像传感器可以配置为识别用户何时抬起眉毛,并在发生这种情况时关联传感器的方向性。这样的校准步骤可能有助于使管道300更容易地实现不同形状的面部。
继续,管道300为每个位于314的中心数据值确定一个插值值。在所描述的示例中,对中心传感器值执行逆线性插值。
管道300接下来可以对插值值执行线性到伽马空间的转换,以在316形成转换后的值。在所描述的示例中,转换后的值包括0到1之间的范围。所述范围与从线性插值获得的归一化数据的范围相同。然而,与314处插值的归一化数据相比,线性到伽马空间的转换可能会强调更微妙的面部运动。
一个线性到伽马空间转换图的例子如图4所示。(0,0)和(1,1)之间的直线对应于伽马空间转换之前的插值值,而曲线对应于图4右下角图例中给出的伽马值。线性到伽马空间的转换有助于从计算机生成面部表情中获得更有意义和更自然的动作。
回到图3,在可选地执行线性到伽马空间转换后,管道300根据320处的转换值确定基于方向性的混合形状映射。在一个实施例中,转换后的值与混合形状映射相关联,并乘以混合形状节点的相应混合形状权重。
在特定面部表情中,在第一位置的面部运动可以反映面部的其他位置。因此,链接的混合形状节点列表可用于将一个面部位置的感知运动链接到与第一个位置链接的其他位置。
例如,感知到的脸颊的运动可能与嘴角的运动相对应。这样,用于脸颊的混合形状节点可以链接到用于嘴角的混合形状节点,从而允许脸颊的感知运动影响所显示Avatar中的嘴的形状。
以这种方式,可以执行每个传感器的一对多混合形状关联和/或跨传感器分析,以确定人脸姿态。在省略线性到伽马空间转换的示例中,可以直接基于插值值进行混合形状映射。
继续图3,管道300至少基于混合形状映射确定表情数据并输出表情数据,如322所示。例如,表情数据可以采用混合形状动画的形式,如324所示。混合形状动画可用于动画的面部表情的Avatar。管道300中使用的插值方法和/或线性到伽马空间转换可能影响表情数据动画化的方式。
如上所述,可以为链接的混合形状节点列表中的每个混合形状节点确定插值值或转换值的混合形状映射。图5显示了链接的混合形状节点500的示例列表。
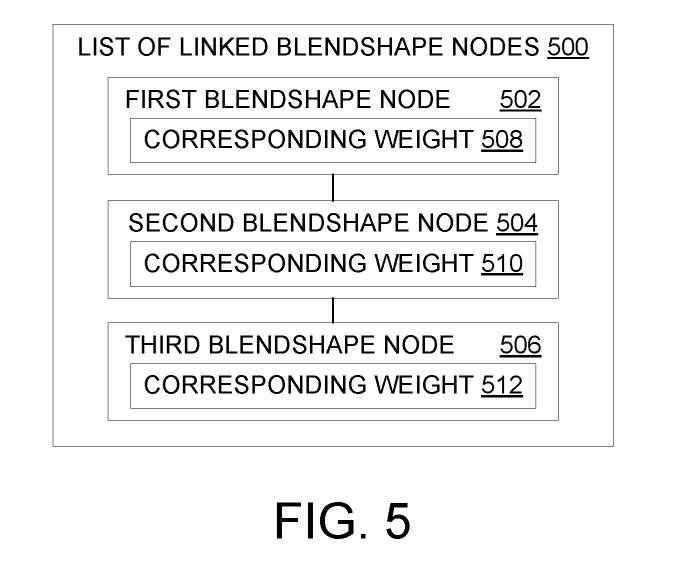
在所描述的示例中,链接的混合形状节点500的列表包括第一混合形状节点502、第二混合形状节点504和第三混合形状节点506。如上所述,这种配置可以在通过面部追踪传感器获取的传感器值与传感器值可能影响的混合形状之间建立一对多关联。
作为示例,指向用户的眉毛的面部追踪传感器可以影响眉毛混合形状和眼睑混合形状。在其他示例中,链接的混合形状节点列表500可以包含任意数量的混合形状节点。
在一个实施例中,可以存储链接的混合形状节点500的多个列表,其中多个列表中的每个列表可以与不同的面部追踪传感器相关联。
这样的配置可以帮助确定来自指向面部的多个区域的每个多个面部追踪传感器的混合形状映射。另外,每个混合形状节点502、504、506分别包含相应的权值508、510和512。对应的权重508表示传感器值对第一个混合形状节点502的混合形状映射的影响程度。
类似地,相应的权重510和512可以分别表示传感器值对第二和第三混合形状节点504和506的混合形状映射的影响程度。在一个示例中,每个混合形状节点502、504、506可以进一步包含一个用于指示方向性的阈值。
例如,当通过眉毛传感器获得的传感器值上升时,动画眉毛会上升,当传感器值下降时,动画眉毛会下降。这样的配置可以帮助确定具有不同面部landmark位置的多个用户的表情数据。
在一个实施例中,可以使用来自多个不同类型传感器的数据来确定表情数据。图6示出用于利用传感器数据的多种模式控制计算机生成的面部表情的示例计算系统600。
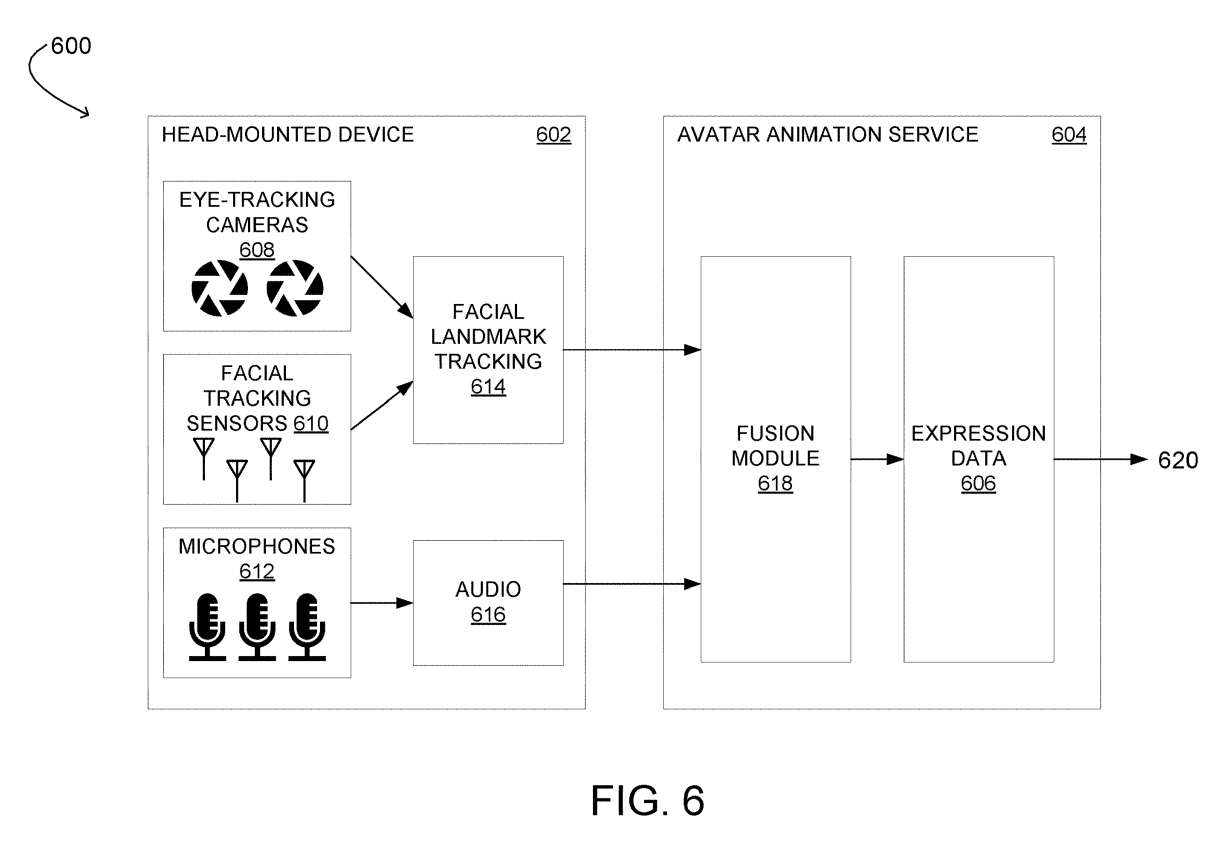
计算系统600包括配置为获取指示面部表情的传感器数据的头戴式设备602。计算系统600同时包括Avatar动画服务604,服务604配置为基于来自头戴式设备602的传感器数据确定表情数据606。
头戴式设备602包括一个或多个眼动追踪摄像头608、一个或多个面部追踪传感器610和一个或多个麦克风612。头戴式设备602配置为基于通过面部追踪传感器610和眼动追踪摄像头608获取的数据确定面部landmark追踪数据614。这样的配置有助于追踪面部landmark运动。
Avatar动画服务604包括融合模块618,其配置为从面部landmark追踪数据614和音频数据616确定表情数据606。在一个示例中,融合模块618可以利用管道300来处理来自面部追踪传感器610的数据。
Avatar动画服务604进一步配置为向设备提供表情数据606,如620所示。所述设备可以是头戴式设备602、不同的头戴式设备或任何其他合适的显示设备。
以这种方式,计算系统600可以将面部追踪传感器与眼动追踪摄像头和麦克风相结合,以基于合成为最终输出指示表情数据的这些传感器的输入读数来创建用户面部表情的模拟。
相关专利:Microsoft Patent | Controlling computer-generated facial expressions
相关专利:Microsoft Patent | Controlling computer-generated facial expressions
名为“Controlling computer-generated facial expressions”的微软专利申请最初在2022年5月提交,并在日前由美国专利商标局公布。