微软专利为AR/VR远程会议提供“讲话人”视觉指示器自动化系统
视觉指示器自动化系统
(映维网Nweon 2023年12月15日)远程会议的发展正在促进元宇宙的普及。然而,当前在线会议应用使用元环境的其中一个主要问题是,会议参与者可能难以识别相关的用户活动,例如正在讲话的人员。当用户界面安排包括2D和3D渲染的组合时,这个问题可能会加剧。
所述问题可能会导致效率低下,并导致计算设备和用户之间的无效交互,特别是在通信会话期间。所以在名为“Automation of visual indicators for distinguishing active speakers of users displayed as three-dimensional representations”的专利申请中,微软介绍了一种用于区分活跃说话者或显示为三维表示用户的视觉指示器自动化系统。

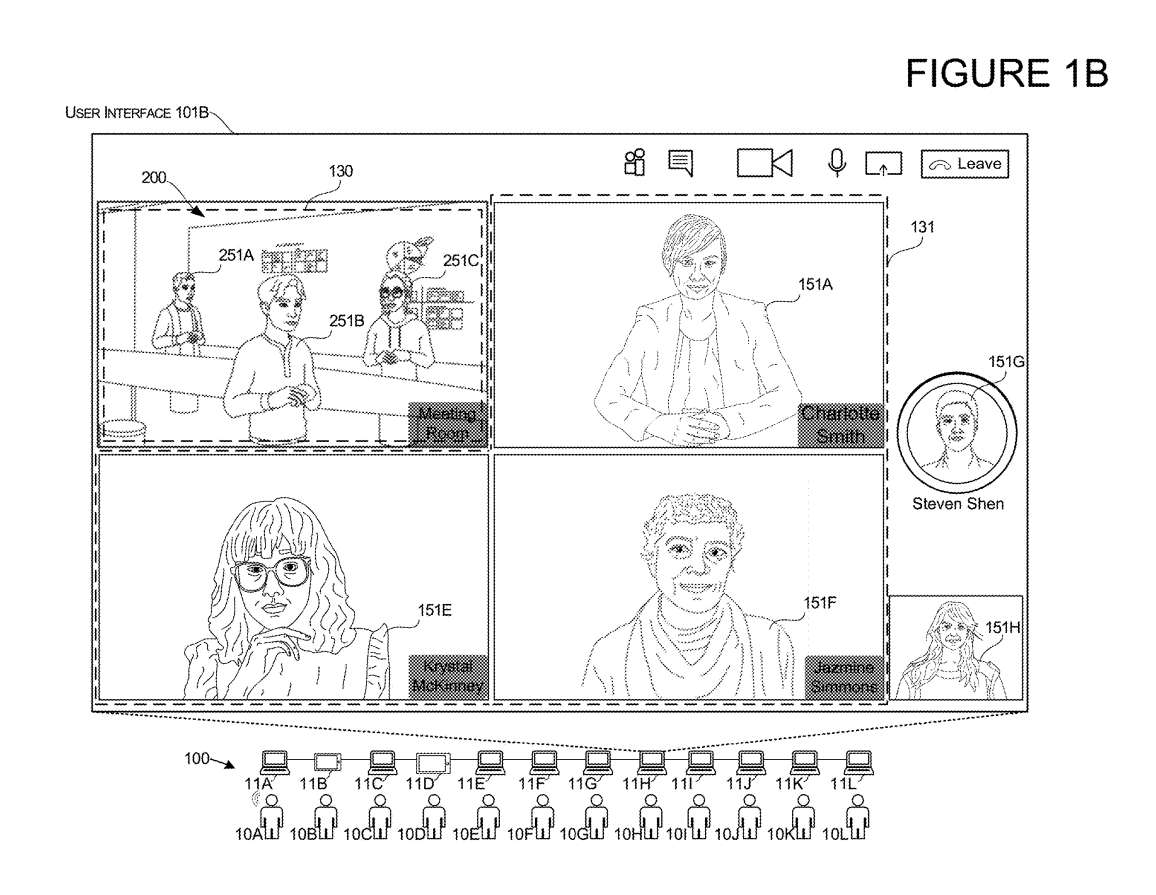
图1A和1B举例说明了一个UI转换的例子。通信会话可由由若干台计算机11组成的系统100来管理,每台计算机11对应于若干用户。每个用户可以在用户界面中显示为2D图像151,或者每个用户可以在用户界面中显示为3D表示251。所述2D图像151可以是由指向用户的摄像头生成的静态图像或视频流。所述3D表示251可以是静态模型或动态模型,并具有响应用户输入的实时运动。
系统可以为在通信会话中主动发言的第二区域131选择用户的个人效果图。所述系统可以使用一个或多个阈值或标准来选择要在指定给主动说话人的第二区域131内显示的单个用户。例如,当检测到用户从麦克风产生音频信号时,系统可以在所述第二区域131内显示用户的呈现。
系统同时可以分析音频信号以确定语音速率,或确定用户是否在语音输入中提供了阈值单词数。如果用户所说的语速或字数满足一个或多个标准或超过一个或多个阈值,则系统可以在第二区域131内显示用户的Avatar呈现。对于具有不符合一个或多个标准或不超过一个或多个阈值的语音活动的用户,系统不在第二区域中显示其图像131。
第二区域131同时可以具有可显示的预定用户限制。在实施例中,根据其活动对从事语音活动的用户进行排名。例如,在通信会话中说话的用户可以根据语音速率、音量、所选单词或术语的使用等在说话者队列中排名。可在第二区域131内显示最高等级的说话者,直至预定的限制。一旦显示的说话者的输入不符合标准,则可以删除活动说话者的图像。
系统可以将监视活动限制为在3D环境中显示为3D表示251的用户的音频流。这允许系统只对特定用户的流运行语音分析。在图1A的示例中,这包括第一用户、第二用户和第三用户的音频流。系统可以确定其中一个音频流是否符合标准。
例如,如果由3D表示物251A表示的第一用户10A开始以阈值速率和或阈值音量说话,则系统可以确定第一用户是在3D环境中显示具有3D表示物的用户的主动说话者。
为了确定具有显示在3D环境中的3D表示的用户具有满足一个或多个标准的语音输入,系统执行从图1A的第一用户界面安排101A到图1B的第二用户界面安排101B的转换。如图所示,在过渡中,系统在第二用户界面安排101B中添加了主动说话人的图像或表示的第二呈现。
在一个实施例中,在为主动说话者保留的第二区域131内显示主动说话者的第二图像。继续上述示例,当显示为第一3D表示251A的第一用户10A提供满足一个或多个标准的语音输入时,如图1B所示,系统显示第一用户10A的2D图像151A的第二呈现。
在本例中,第一用户的2D图像包括由与第一用户10A相关联的第一计算设备的摄像头生成的视频流。第一用户10A的2D图像151A位于为有源说话者保留的第二区域131内。在所述实施例中,为主动说话者保留的第二区域131采用网格格式,其中网格的每个部分显示参与者的视频效果图。
所述第二用户界面布置101B还配置有所述第一用户10A的2D图像151A,使得其与所述第一用户10A的3D表示251A的呈现同时显示。在一个实施例中,可以维持第一用户10A的3D表示251A的呈现,使得第一显示区域130在整个过渡过程中显示3D环境200的相同视角。
可以基于一个或多个因素去除图像或主动说话者的表示形式的第二呈现。在一个实施例中,所述补充图像可以显示预定的时间段。在预定的时间段之后,可以移除所述补充图像,例如所述第一用户10A的2D图像151A,并将其替换为说话者队列中的另一活动说话者。
在一个实施例中,可以显示补充图像,直到不再满足语音输入的一个或多个标准。例如,如果语音输入的一个或多个标准包括语音速率,并且作为对满足或超过该语音速率的语音输入的响应,在第二区域131内显示提该语音输入的用户的第二图像,则一旦用户停止说话一段预定的时间,系统可以删除用户的第二图像。
在另一示例中,如果在第二区域131内显示提供语音输入的用户的第二图像,例如图1B中的图像151A,则一旦用户停止说话或其语音输入不再满足一个或多个标准,则系统可以删除用户的第二图像。
系统可以根据其他因素删除用户的第二图像。例如,如果其他用户说话的音量比显示在第二个区域的用户大,则其他用户的图像可以取代该用户的第二个图像。

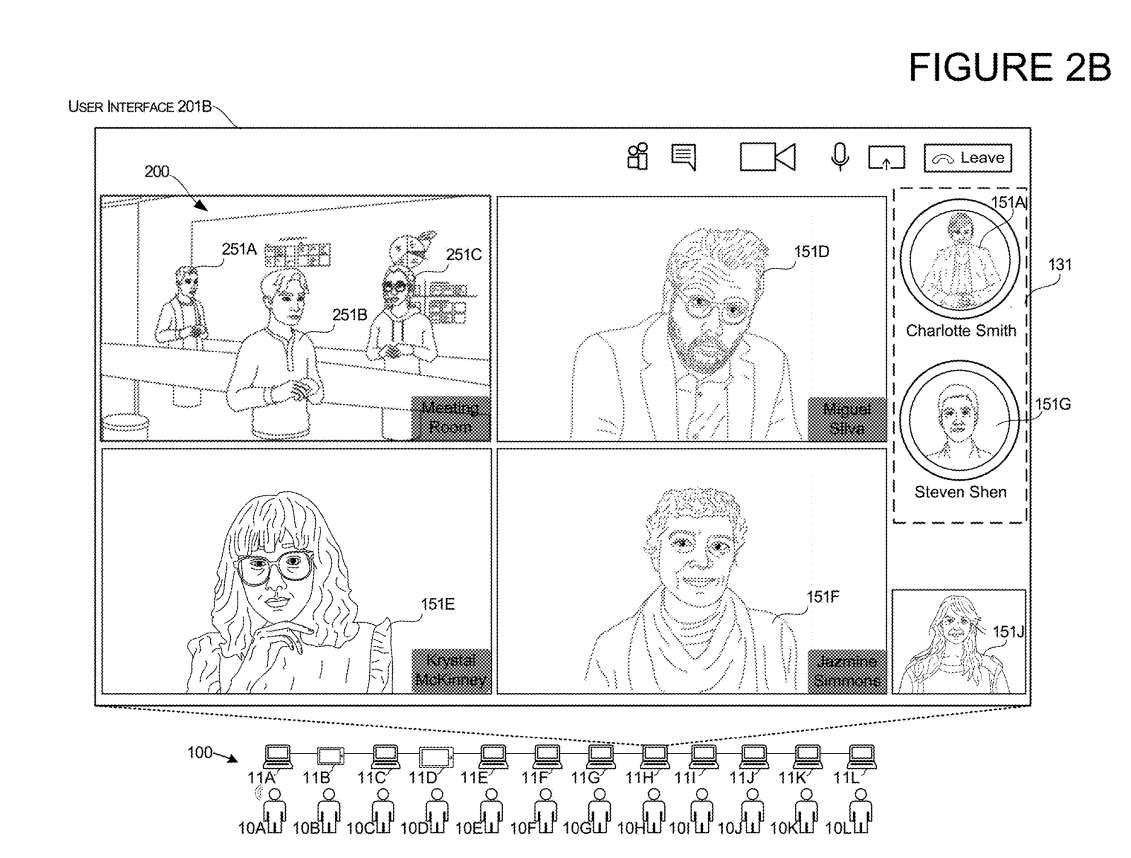
图2A-2B说明了在接收到触发输入时发生的另一用户界面转换示例。触发输入可以包括满足本文所述的一个或多个标准的任何类型的语音输入。触发输入可以包括任何类型的用户输入,例如手势。
本实施例与上述实施例类似,第一用户10A提供语音输入或另一限定输入,并且作为对输入的响应,在为主动说话者保留的第二区域131内显示用户的第二图像。在图2A的示例中,为主动说话者保留的第二区域131与溢出队列关联定位。溢出队列是UI的一个区域,并用于显示不合格用户的渲染图。
当网格渲染的说话者队列达到最大用户限制时,可以生成溢出队列/补充队列。例如,如果UI的网格部分的说话者队列限制为3个用户,并且有4个活动说话者,则系统将在图像网格中显示排名前三的用户,并在溢出队列中显示排名第四的说话者。
如图2A所示,第一用户界面布置201A显示了在3D环境的呈现中显示的第一用户10A的3D表示的呈现。当第一用户10A开始提供语音输入或任何其他合格输入,例如,控制3D表示以提供用户正在说话的外观的输入时,系统随后在第二区域131内显示该用户的补充图像151A,如图2B所示。
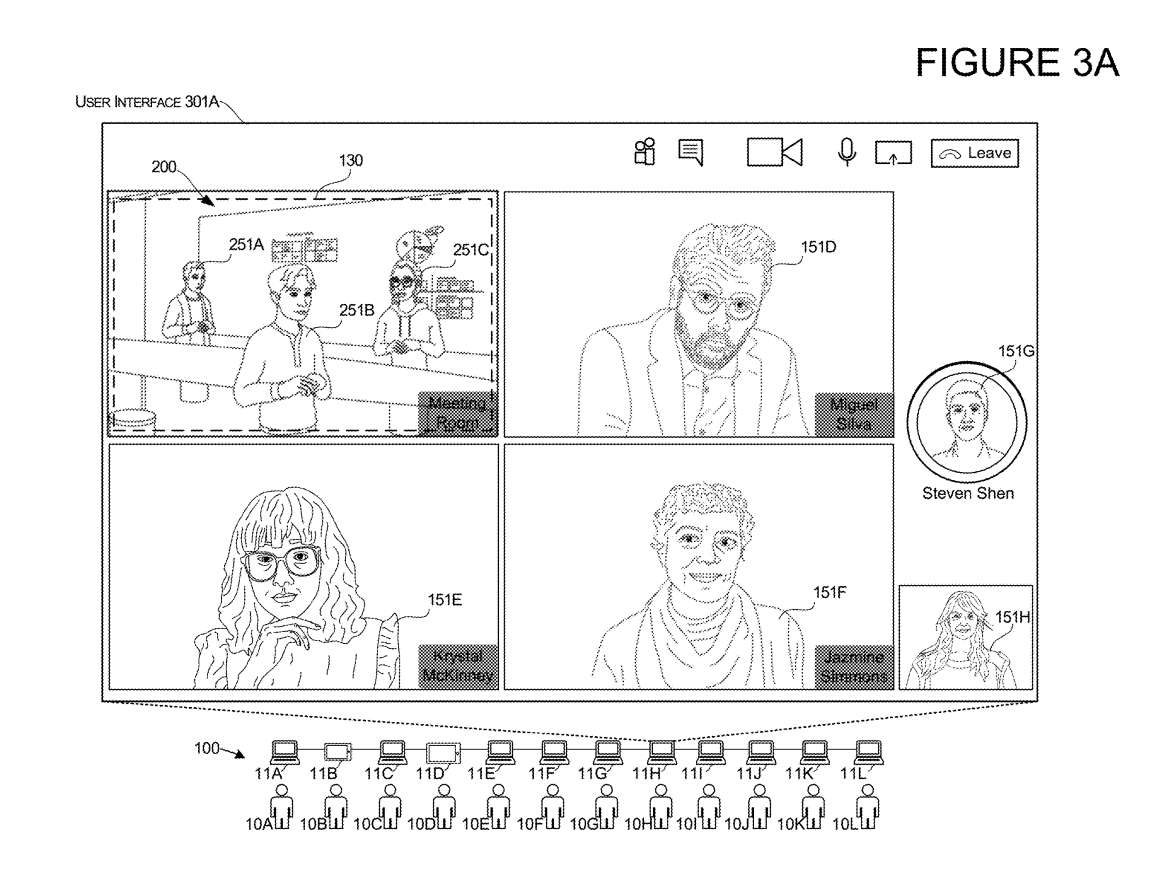
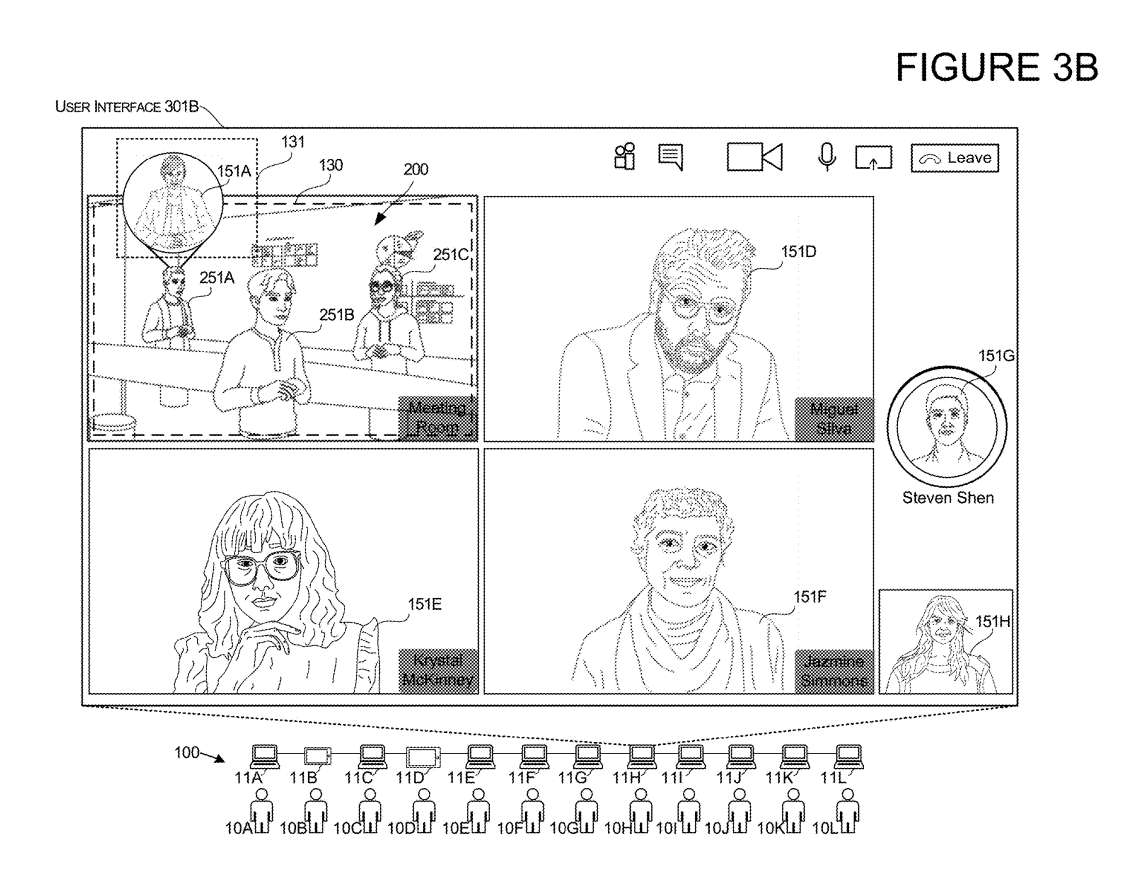
图3A-3B说明了当接收到触发输入时发生的另一用户界面转换示例。本实施例与上述实施例类似,第一用户10A提供触发输入,并且作为对触发输入的响应,在为主动说话者保留的第二区域131内显示该用户的第二图像。
在所述实施例中,为主动说话者保留的第二区域131定位并布置为至少部分地与所述3D环境200的3D渲染重叠。换句话说,在本实施例中,保留用于呈现位于3D环境200内的用户的3D表示的第一区域130和第二区域131至少部分重叠。
如图3A所示,第一用户界面布置301A显示了在3D环境的渲染中显示的第一用户10A的3D表示的渲染。当第一用户10A开始提供语音输入或控制3D表示以呈现用户正在说话的外观的任何其他输入时,如图3B所示,系统随后在第二UI布置301B中显示该用户在第二区域131内的补充图像151A。
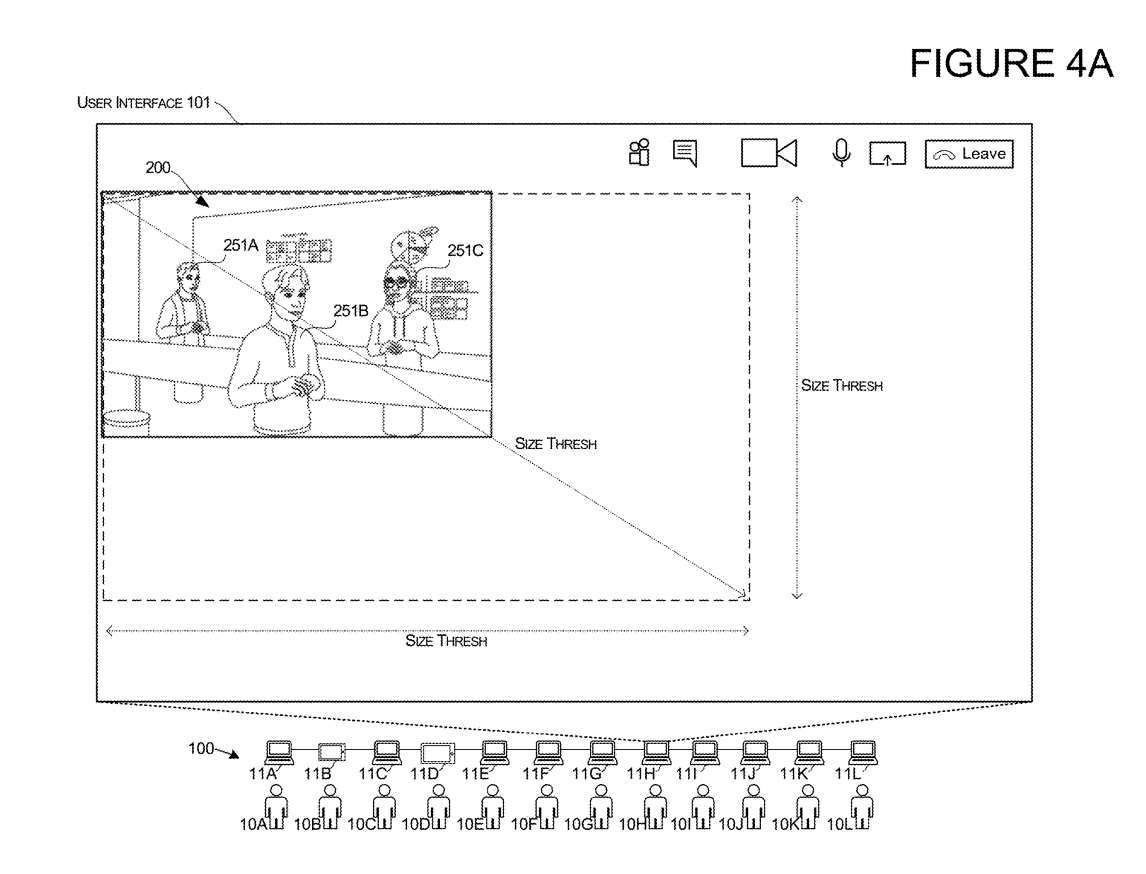
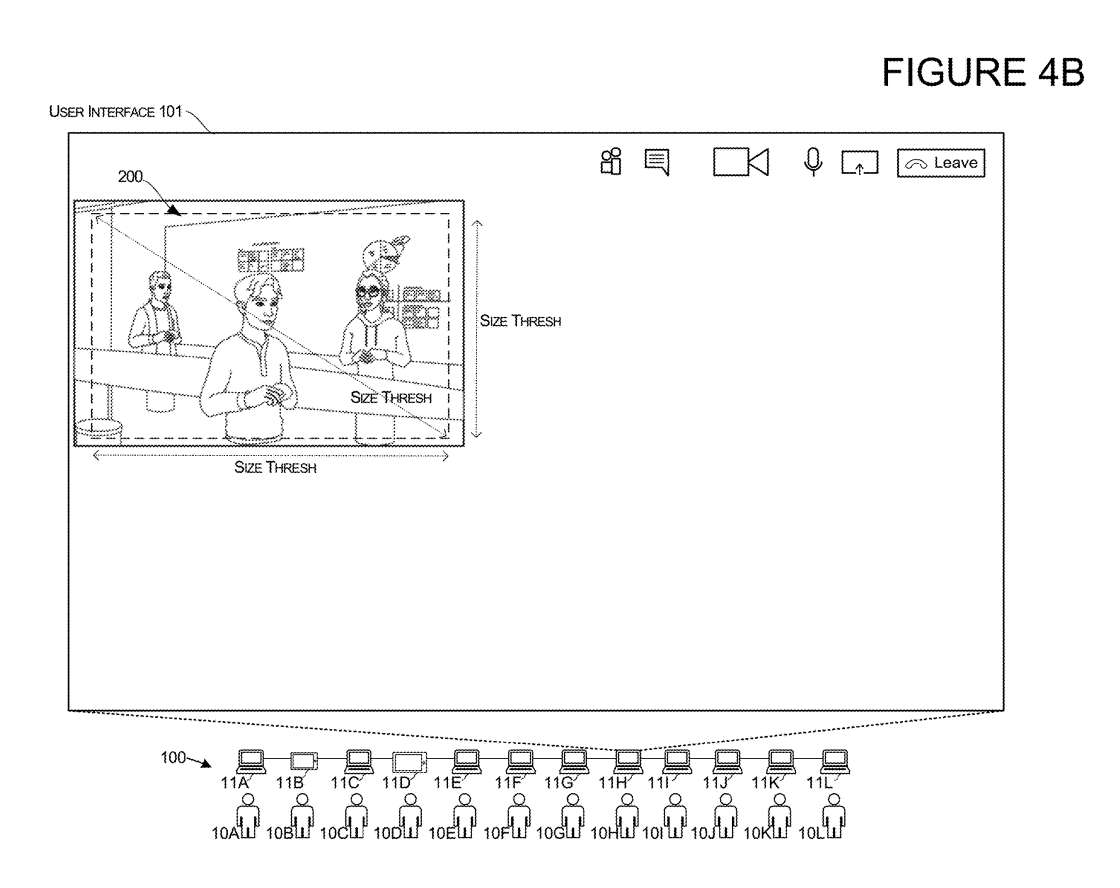
图4A和4B说明了可以控制用户界面转换的系统。用户界面转换可以由一个因素控制,例如3D环境的3D渲染的大小200。在更可能需要转换的情况下,可以利用这个控制来保存计算资源。例如,如果3D环境200的3D呈现在用户界面内相对较小,则系统可以引起本文所述的过渡,以帮助用户识别3D环境中的活动说话者。在3D环境的呈现相对较小并且用户难以看到3D Avatar 251的实际运动的场景中,可能需要显示活动说话者的通知。
在一个实施例中,如果3D环境200的呈现具有小于阈值维度的一个或多个维度,则系统可以设置许可以允许本文所述的转换。示例如图4A所示,其中所述3D环境200的渲染至少有一个维度小于阈值大小或阈值维度。
但如图4B的示例所示,所述3D环境200的渲染至少有一个维度大于阈值大小或阈值维度。当检测到这个条件时,系统可以设置权限以拒绝本文所述的UI转换,例如,系统可以限制位于3D环境中具有3D表示的活动说话者的图形通知的显示。这允许系统通过限制用户界面转换来保存资源。
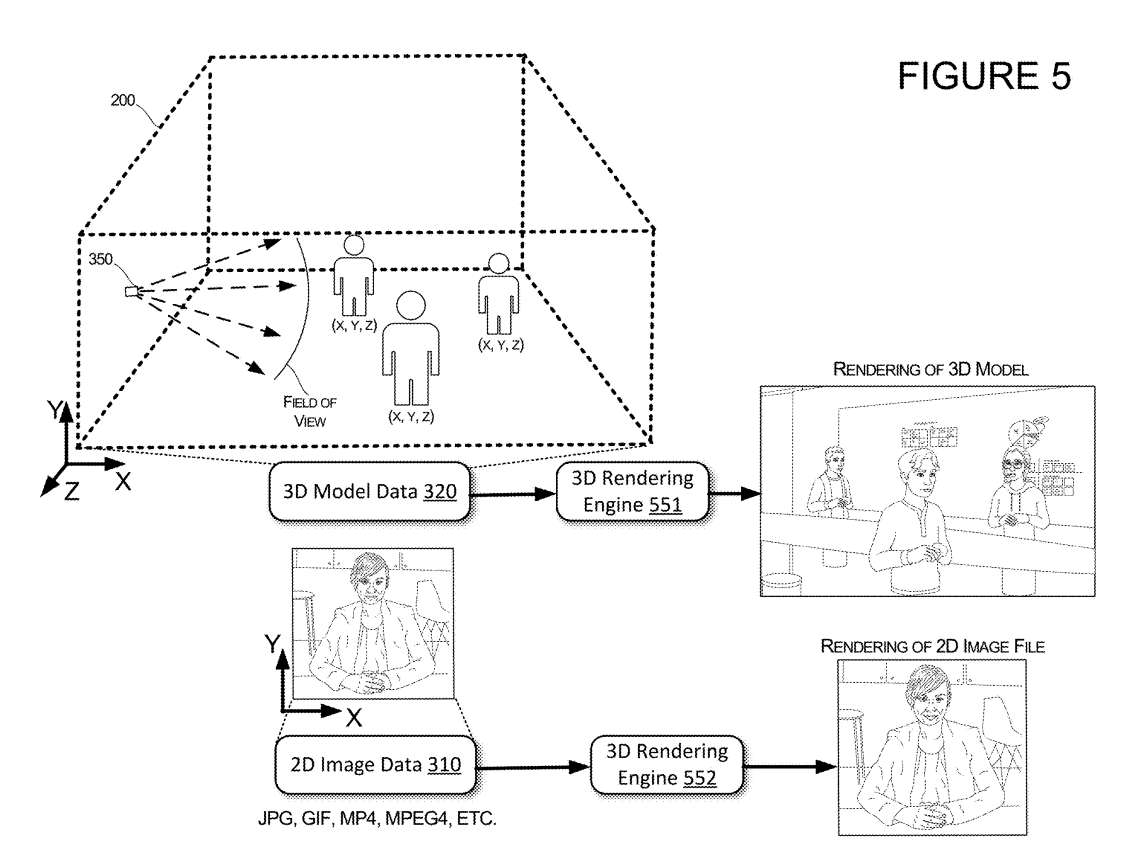
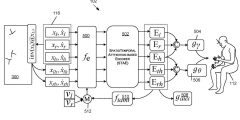
图5示出UI效果图的附加技术细节。当接收用于引起本文所述的UI过渡的输入时,系统可以确定用于控制用于主动说话者的3D表示的观看视角的虚拟摄像头350的位置和方向。例如,在图1A所示的示例中,当作为3D环境中的3D表现形式显示的第一用户10提供触发输入,例如满足一个或多个标准的语音输入时,系统可以修改虚拟摄像头350的位置或方向,以便3D环境的呈现提供更直接的用户3D表现形式的面部视图。
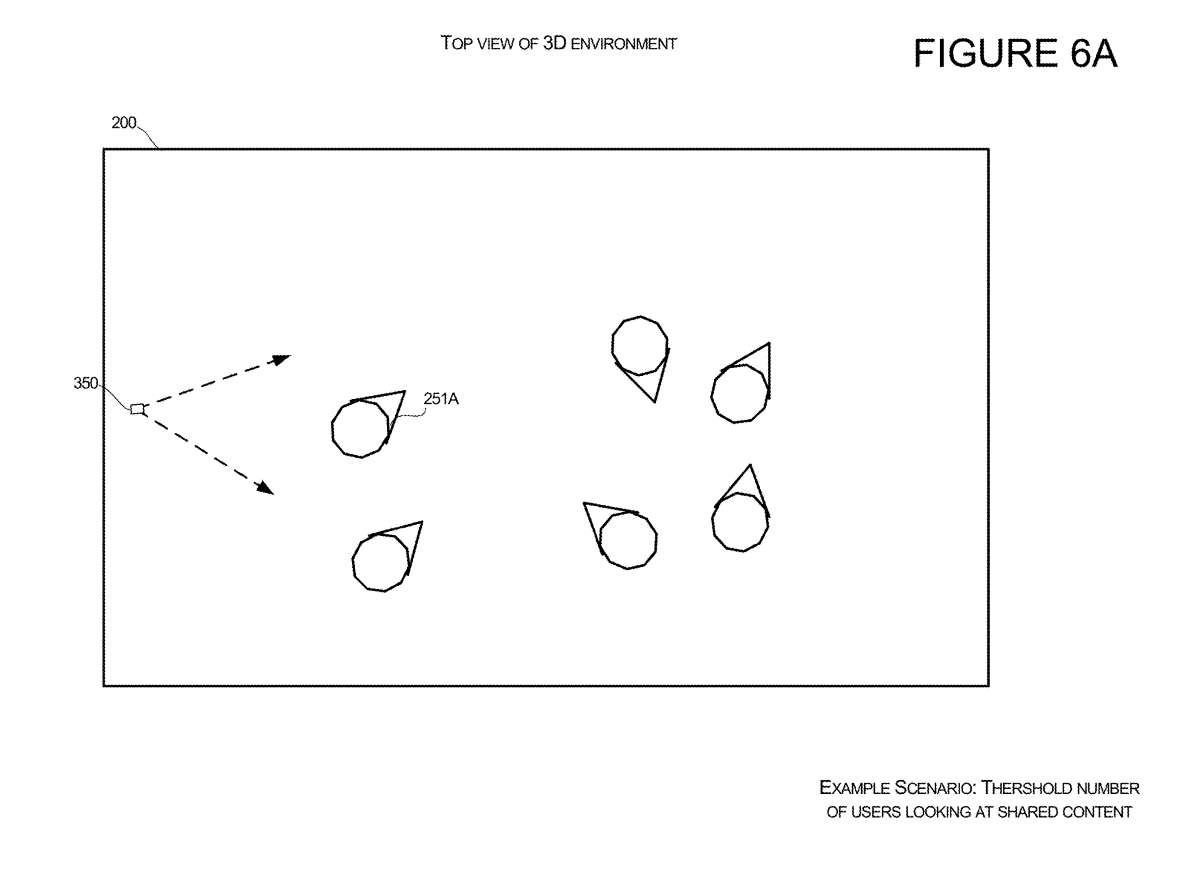
如图6A所示,在触发输入之前,考虑这样一种场景,其中虚拟摄像头350的位置和方向配置为使得用于第一用户10A的3D表示251A远离虚拟摄像头。在这种情况下,第一个用户10A的3D表示251A的观看者可能无法看到用户何时说话,因为他们无法看到基于摄像头角度的面部姿态。
因此,作为对触发输入的响应,除了提供补充图像151A外,所述系统同时可以修改所述虚拟摄像头的位置和方向,使得所述3D环境的渲染为所述第一用户显示所述3D表示的面部。
这样3D环境200的观看者将能够看到主动说话者的Avatar的脸。这种虚拟摄像头的修改可以向观众提供进一步的通知。另外,虚拟摄像头的方向或位置的移动可以响应于本文所述的任何触发输入而启动。
名为“Automation of visual indicators for distinguishing active speakers of users displayed as three-dimensional representations”的微软专利申请最初在2022年5月提交,并在日前由美国专利商标局公布。
需要注意的是,一般来说,美国专利申请接收审查后,自申请日或优先权日起18个月自动公布或根据申请人要求在申请日起18个月内进行公开。注意,专利申请公开不代表专利获批。在专利申请后,美国专利商标局需要进行实际审查,时间可能在1年至3年不等。