微软专利提出将用户的2D表示呈现为3D空间中的Avatar化身
将用户的2D表示呈现为3D空间中的Avatar化身
(映维网Nweon 2024年01月22日)视频会议可用于允许一个或多个会议参与者远程加入会议。混合会议可以包括通过多种不同媒介加入会议的多个参与者,例如亲自或远程。在这方面,混合会议允许参与者使用大量的XR技术加入会议。
微软认为,远程办公的兴起促进了视频会议技术的发展。但传统的视频会议目前只能为远程参与者融入混合会议环境提供有限的选择。另外,特定的远程工作技术可能需要大量的计算。
所以在名为“Representing two dimensional representations as three-dimensional avatars”的专利申请中,微软提出可以将用户的2D表示呈现为3D空间中的Avatar化身,从而改善用户参与度,同时提供其他好处,例如减少计算量。
具体而言,发明描述的机制通过基于从一个或多个输入视频流接收的一个或多个2D视图创建用户的透视图来提供改进的用户参与度,其计算成本比可将2D表示转换为3D化身的传统系统相对较低。
另外,平面对象可以使用多种技术进行渲染,例如通过神经辐射场NeRF。它可以将多视图图像组合到一个体积表示中,以生成比原始视图更好的视图。通过渲染光线将输出颜色和密度投射到图像中,体积表示可以在没有参考几何的情况下生成对象的新视图。
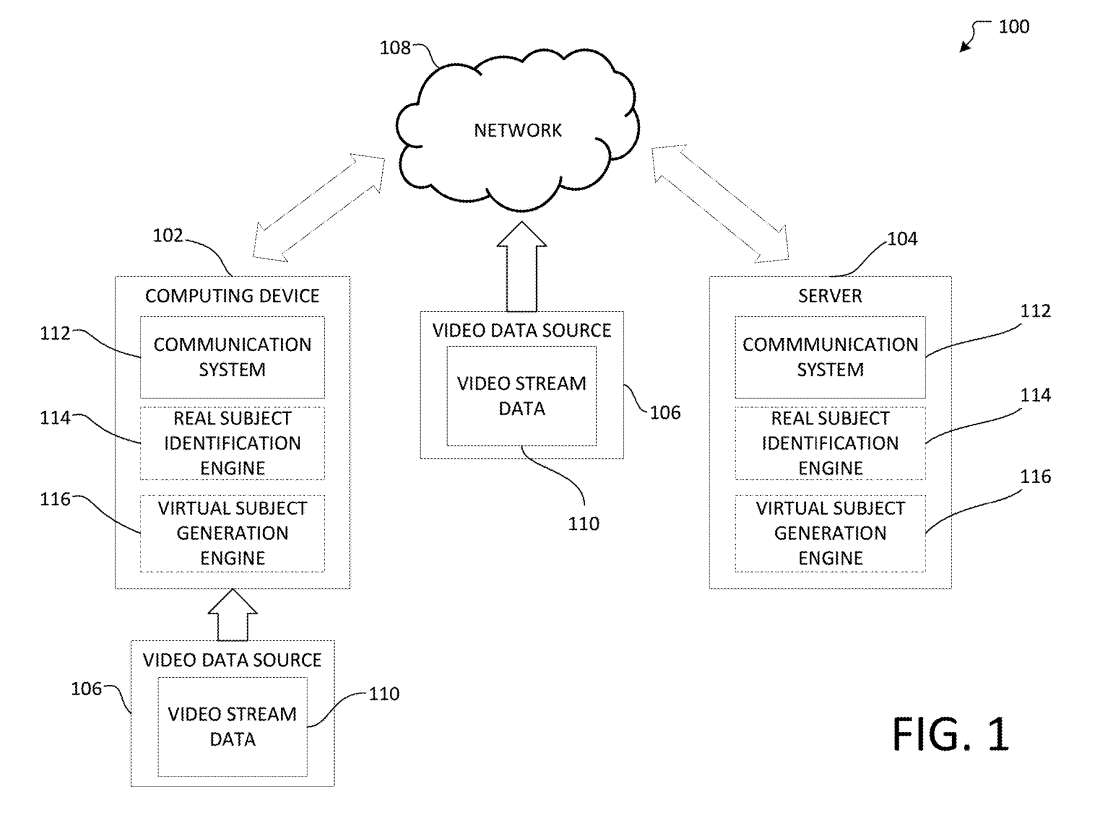
图1显示了系统100。示例系统100可以用于将2D图像表示为3D空间中的化身,例如混合会议空间。如图1所示,所述系统100包括计算设备102、服务器104、视频数据源106和通信网络或网络108。所述计算设备102可以从所述视频数据源106接收视频流数据110,所述视频数据源106可以是例如网络摄像头、摄像头、视频文件等。
计算设备102可以包括通信系统112、真实主体识别引擎或组件114、虚拟主体生成引擎或组件116。
计算设备102可以执行真实主体识别组件114的至少一部分,以从视频流数据110中识别、定位和/或追踪主体,例如,人、动物或物体。另外,在计算设备102可以执行虚拟主体生成组件116的至少一部分,以确定视频流数据110中主体的视图、平面对象分割或平面对象配置。
主体的视图可以基于一组视频流数据110和/或多个视频流数据集110确定。另外,可以基于所述主体的一个或多个枢轴点对所述平面对象进行分割。可选地,平面对象可以基于训练的机器学习模型生成或以其他方式配置。
在一个实施例中,可以使用训练好的分类器来检测基于2D视频的人,以及每个人的骨骼姿势。2D视频可以从RGBD视频源接收。RGBD视频可以从一系列运动传感输入设备。
骨架可以作为简单几何代理的指南。一般人类模型可用于将来自一个或多个视频源的像素投影到新视图。另外,从视频流数据110获得的深度数据可用于从视频中分割人,生成比平面对象更好的代理几何,或构造体积表示。
服务器104可以包括通信系统112、真实主体识别引擎或组件114、虚拟主体生成引擎或组件116。在一个实施例中,服务器104可以执行真实主体识别组件114的至少一部分,以从视频流数据110中识别、定位和/或追踪主体,例如,人、动物或物体。
另外,服务器104可以执行虚拟主体生成组件116的至少一部分,以确定视频流数据110中主体的视图、平面对象分割或平面对象配置,例如由真实主体识别组件114识别的主体。
主体的视图可以基于一组视频流数据110和/或多个视频流数据集110确定。另外,可以基于所述主体的一个或多个枢轴点对所述平面对象进行分割。可选地,平面对象可以基于训练的机器学习模型生成或以其他方式配置。
在一个实施例中,计算设备102可以通过通信网络108将从视频数据源106接收到的数据通信到服务器104,通信网络108可以执行真实主体识别组件114和/或虚拟主体生成组件116的至少一部分。
在一个实施例中,视频数据源106可以位于计算设备102的本地。例如,视频数据源106可以是耦合到计算设备102的摄像头。另外,视频数据源106可以远离计算设备102,并且可以通过通信网络将视频流数据110通信到计算设备102。
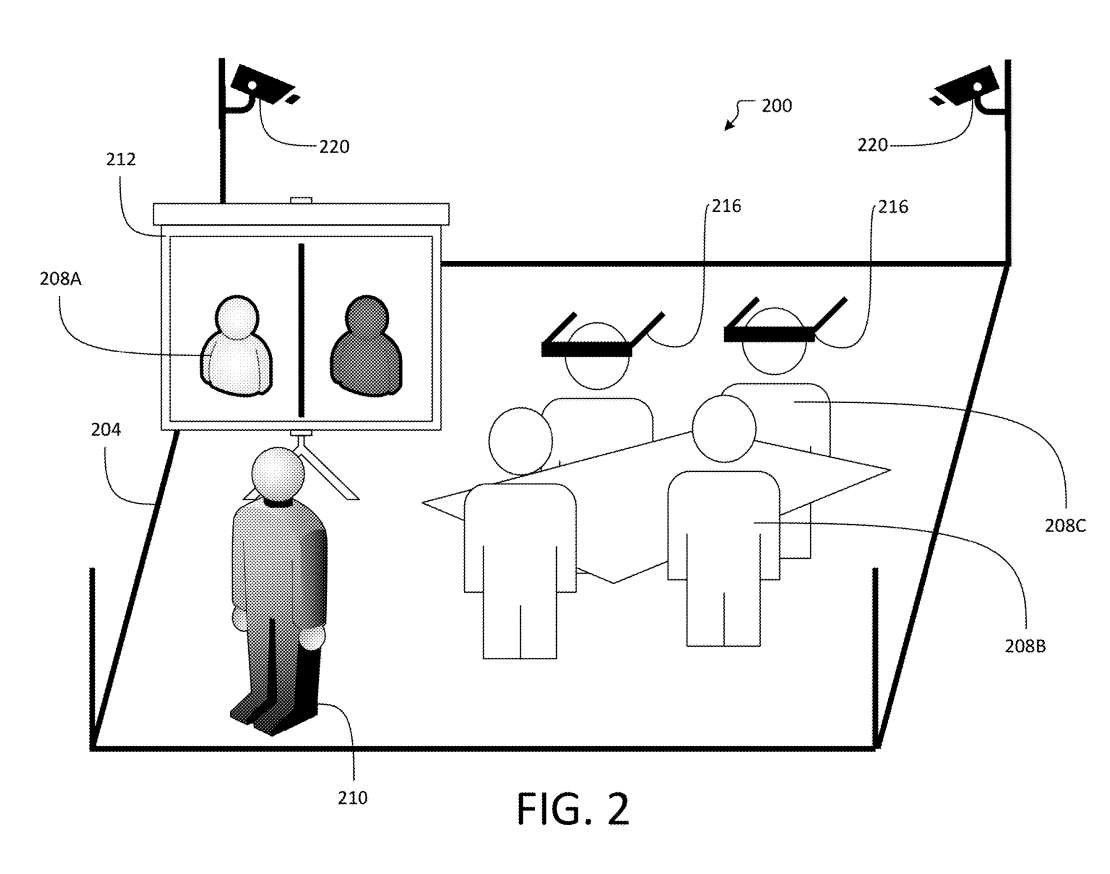
图2描述的混合会议200可以在房间204内举行。在一个例子中,房间204可能是一个物理房间。或者,房间204可以是虚拟房间。多个参与者208可以参加混合会议200。
多个参与者208的第一子集208A可以通过视频会议参加混合会议200。多个参与者208的第二子集208B可以实际出席混合会议200。多个参与者208中的第三子集208C可以佩戴头戴式显示器216以查看与远程参与者对应的一个或多个生成化身210。
多个参与者208的第一子集208A每个都可以远离房间204。第一子集208A可各自具有计算设备和/或视频数据源,其对于第一子集208A中的每个参与者是本地的,并且允许第一子集208A中的每个参与者参加混合会议200。
多个参与者208的第二子集208B每个可物理地位于房间204内。第三子集208C可以物理地位于与第二子集208B相同的房间中或位于远程位置。房间204可以包括设置在其中的一个或多个摄像头220,以从第二子集208B向一个或多个远程用户生成一个或多个参与者的视频流。
与第三子集208C中的一个或多个参与者相对应的生成的化身210可以对远离混合会议200的至少部分参与者208可见。另外,多个参与者208中的至少一些可以通过佩戴头戴式显示器216来查看生成的一个或多个化身210。
在一个实施例中,头显216可以是一款虚拟现实头显,或者头显216可以是增强现实头显。
就图1而言,一个或多个摄像头220可以类似于前描的视频数据源106。所述一个或多个摄像头220可收集以连续时间间隔拍摄的一批静止图像。另外,一个或多个摄像头220可以收集在某一时刻拍摄的静止图像的单个实例。
可选地,一个或多个摄像头220可以收集视频数据的实时馈送。可以根据用户偏好在房间204内的特定位置配置一个或多个摄像头220。另外,可以根据不同优点或缺点在房间204内可以有任意数量的摄像头220。
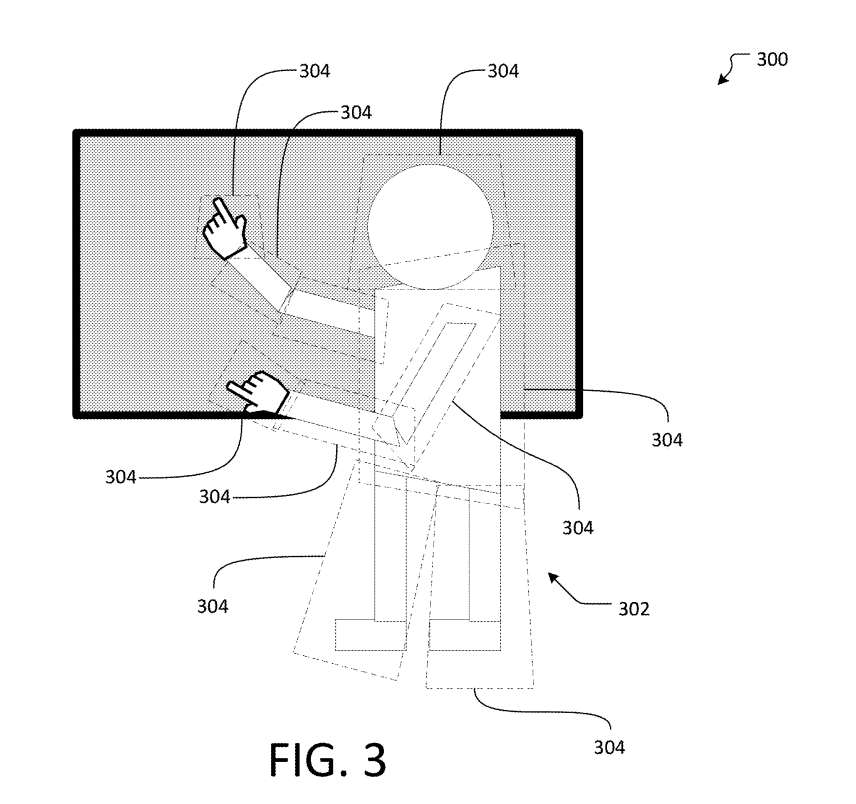
图3示出生成主体302的一个或多个视图。主体302可以是基于视频流数据生成的人、动物和/或对象。另外,主体302可以基于一个或多个静止图像和/或与主体302的物理版本相对应的一个或多个动画生成。在实施例300中所示的主体302是虚拟主体,其可以类似于图2的生成化身210。
主体302可以位于混合会议空间内。另外,主体302可以对应于远离混合会议空间的物理主体。所述主体302可以分割成多个平面对象304。所述多个平面对象304可以是多个billboard。多个billboard304可以是相对于彼此变换的平面。平面可以是2D平面和/或曲面。另外,平面可以相对于彼此以角度旋转,亦即不共面。
所述主体302可包括一个或多个枢轴点,所述主体302的两个或多个部分配置为围绕其旋转。例如,主体302是一个人,其中一个或多个枢轴点是配置为围绕其旋转的身体部位的关节。一个或多个billboard可以在支点处分割。一个或多个billboard可以通过虚拟关节连接,虚拟关节可以是旋转的关节点。
一个或多个billboard304可以彼此弯曲,拉伸以相互重叠或相交,彼此模糊,彼此混合,彼此离散地相邻,或以其他方式在视觉上处理以形成对应于物理主体的虚拟主体。
一个或多个billboard304中的每一个都可以在3D空间内平移和/或旋转,以形成被平移和/或旋转的billboard304中包含的主体302的一部分的透视图。
在实施例300中,与所述主体302的主体相对应的billboard304中的一个或多个可以有意地旋转,使得所述主体302的几何形状对观看者可见。
确定主体302的哪些方面在视觉上优于面向观察者可以由用户可配置。另外,确定主体302的哪些方面在视觉上优于面向观察者可以通过机器学习模型来学习。例如,混合会议的参与者可以更频繁地与具有以特定方式布置的billboard的主体接触。
这样的示例可以包括面向观察者的脸、面向用户的手掌、面向用户的胸部等。
在一个实施例中,可以基于视频流数据生成或检测主体302的骨架。骨架可以呈现到一个新的视图,其中主体302的每个肢体沿着其各自的轴对齐并面对与新视图对应的参考点。所述参考点可以是计算设备的摄像头。骨架可以保持与原始视频相同的排列,并且可以为主体302的整个身体生成单个billboard。
或者,如果主体的302手触摸白板,则可以为主体302手的每个骨骼生成一个单独的billboard,以满足新视图的约束。
billboard304可用于产生额外的环境效果,从而增强混合场景的真实感,例如将主体302的反射渲染到会议桌上,将主体302的手和身体的阴影渲染到桌子和/或墙壁上,甚至将阴影投射到物理房间的物理会议桌,以更好地表示远程参与者。
可选地,可以使用机器学习模型将主体302分割成多个billboard304。可以训练机器学习模型以基于多个约束或因素生成分段billboard304。
例如,多个约束可以包括生成分段billboard304的计算成本、一个或多个输入视频流、由分段billboard304形成的物理主体和生成化身之间的错误。所生成的化身所对应的物理主体可以在一个或多个输入视频流中找到。
另外,尽管生成相对大量的billboard可以减少主体302与相应物理主体之间的误差,但生成相对大量的billboard可能增加计算开销。因此,机器学习模型的训练可以进一步依赖于基于用户偏好和/或经济因素对多个变量进行加权的因素。
应该认识到,billboard本身可能不是真实。每当将一个billboard分割成多个billboard时,可能会产生令人恼火的伪影。因此,使用尽可能少的billboard是有益的,例如当通过单个billboard对主体的映射未达到特定所需的约束时。
多个billboard304可以在输出视频流中输出。例如,多个billboard304可构成主体302,主体302可在输出视频流中输出。所述输出视频流可以输出到计算设备。因此,在生成主体302后,用户可以通过输出视频流中的多个billboard304与主体302进行交互。
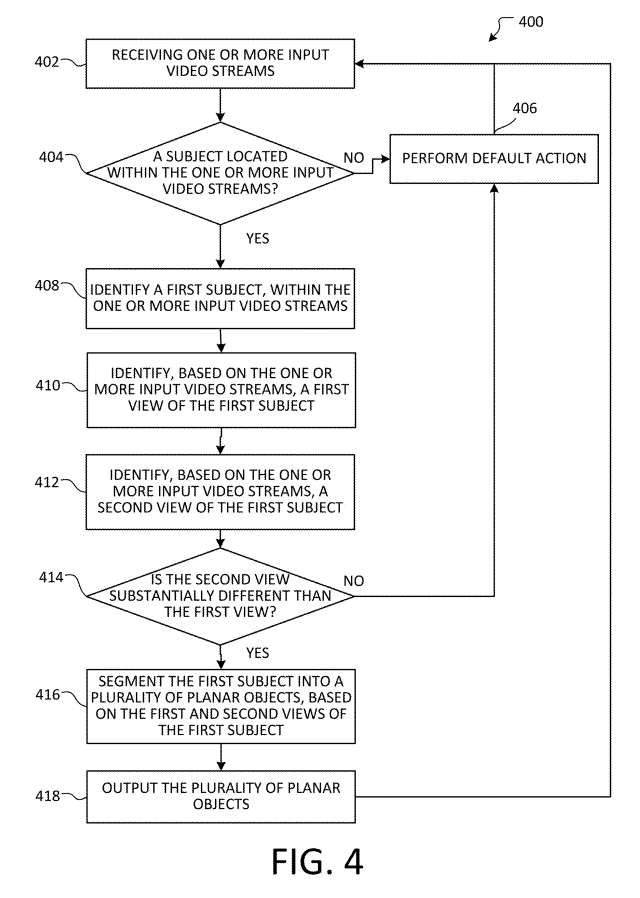
图4示出了实施例方法400。方法400可以是将用户的2D图像表示为3D空间中的化身的方法。
从402开始,接收一个或多个输入视频流。例如,可以从视频数据源接收输入视频流。输入视频流可以包括3D场景。系统可以识别输入视频流的3D子场景,并在3D子场景中划分或分割主体。
在404,确定输入视频流是否包含主体。可以使用发明所述的机制处理视觉数据,以识别存在一个或多个人、一个或多个动物和/或一个或多个感兴趣的对象。
另外在404,可以通过使用特定软件(来识别一个或多个主体。例如,可以通过登录到特定的应用程序识别一个人。因此,当登录到特定的应用程序时,就可以识别所述人员。
如果确定输入视频流中不包含主体,则转到操作406。例如,输入视频流可以具有关联的预配置动作。在其他示例中,方法400可以包括确定输入视频流是否具有关联的默认动作,作为接收到的输入视频流的结果,可以不执行任何动作。方法400可以在操作406时终止。或者,方法400可以返回到操作402以提供连续视频流反馈回路。
然而,如果确定输入视频流包含主体,则转到操作408,其中在一个或多个输入视频流中识别第一主体。第一个主语可以是人、动物或物体。另外,在存在多个输入视频流的情况下,可以在多个输入视频流中的每一个中识别第一主体,例如通过对对应于第一主体的每个输入视频流中的共同特征的视觉识别。
流程推进到操作410,其中基于一个或多个输入视频流,识别第一主体的第一视图。第一视图可以是前视图、侧视图、后视图、顶视图、透视视图或任何类型的视图。第一视图可以相对于第一主体所在的房间内的参考点或形状来识别。第一视图可以根据房间的几何形状来确定。另外,第一视图可以基于第一主体在一个或多个输入视频流中的相对旋转来识别。
流程推进到操作412,其中基于一个或多个输入视频流,识别第一主体的第二视图。第二视图可以是前视图、侧视图、后视图、顶视图、透视视图或任何类型的视图。第二视图可以相对于第一主体所在的房间内的参考点或形状来识别。
在414,确定操作412的第二视图是否与操作410的第一视图本质不同。例如,如果第二视图基本上与第一视图相同,则从一个或多个输入视频流输出第一视图或第二视图中的一个在计算上可能是有利的,因为无需基于第一视图和第二视图执行进一步的处理。
另外,确定第二视图是否与第一视图有本质差异可包括计算第一视图的视觉组件与第二视图的视觉组件之间的误差。用户可以配置一个预定的阈值,以在阈值处确定第二视图与第一视图本质不同。
如果确定第二个视图与第一个视图没有本质上的不同,则转到操作406,其中执行默认操作。例如,可以输出来自一个或多个输入视频流的第一视图或第二视图中的一个,无需进一步处理,以减少计算工作量。
在其他示例中,方法400可包括确定第一视图或第二视图是否具有关联的默认操作,以便在作为第一主体的识别的第一视图和/或第二视图的结果,不执行任何操作。方法400可以在操作406时终止。或者,方法400可以返回到操作402以提供连续视频流反馈回路。
然而,如果确定第二视图与第一视图实质上不同,则转到操作416,其中根据第一主体的第一和第二视图将第一主体分割成多个平面对象。所述多个平面对象可以是多个billboard。如本文前面就图3所述,billboard的多个可以是相对于彼此平移的平面。
通过合并多个视图以在其折叠构型中生成第一主体的3D化身,以向一个或多个观察者提供第一主体的视角。因此,多个billboard中的每个billboard都可以面对摄像头,使得用户可以看到多个billboard中的每个billboard的内容。
所述第一主体可包括一个或多个枢轴点,所述第一主体的两个或多个部分配置为围绕其旋转。例如,如果第一个对象是人或动物,则一个或多个枢轴点可以是关节,身体部位可以围绕关节进行旋转。可以在枢轴点处分割一个或多个平面对象。另外,可以通过虚拟关节连接一个或多个平面对象。虚拟关节可以是对应于第一主体的物理关节的旋转关节点。
一个或多个平面对象可以彼此弯曲,拉伸以相互重叠或相交,彼此模糊,彼此混合,彼此离散地相邻,或以其他方式在视觉上处理以形成对应于物理主体的主体。
另外,或者可选地,可以使用机器学习模型将第一主体分割成多个平面对象。可以训练机器学习模型以基于多个变量生成分段的平面对象。
操作418,可以输出多个平面对象。多个平面对象可以在输出视频流中输出。例如,多个平面对象可以形成生成的3D化身。所述输出视频流可以输出到计算设备,例如头显216。
微软表示,这种方法可以通过相对较少的计算成本来改进现有的3D化身生成方法,同时依然向观看者提供视角信息,从而改善用户的体验。
相关专利:Microsoft Patent | Representing two dimensional representations as three-dimensional avatars
名为“Representing two dimensional representations as three-dimensional avatars”的微软专利申请最初在2022年6月提交,并在日前由美国专利商标局公布。
需要注意的是,一般来说,美国专利申请接收审查后,自申请日或优先权日起18个月自动公布或根据申请人要求在申请日起18个月内进行公开。注意,专利申请公开不代表专利获批。在专利申请后,美国专利商标局需要进行实际审查,时间可能在1年至3年不等。
另外,这只是一份专利申请,不代表一定通过,同时不确定是否会实际商用及实际的应用效果。