微软AR/VR专利分享用辐射场+体三维计算动态场景合成图像
使动态场景的合成图像能够以可控的方式生成
(映维网Nweon 2024年02月07日)在传统的计算机图形学中,计算动态场景的合成图像是一项复杂的任务,因为需要对场景及其动态进行三维建模。
在名为“Computing images of controllable dynamic scenes”的专利申请中,微软介绍了一种使用辐射场和体三维绘制的方法。
辐射场参数化表示一个辐射场,它是从5D空间到4D空间的函数,其中辐射值是场中每对3D点和2D视图方向的已知值。亮度值由颜色值和不透明度值组成。亮度场参数化可以是一个训练有素的机器学习模型,其学习亮度值与对3D点和视图方向之间的关联。
体三维绘制方法通过检查沿形成图像的射线的点的亮度值,从特定camera视点的亮度场计算图像。
发明描述的技术提供了一种精确的方法来控制动态场景的图像如何动画。用户或自动化过程能够指定参数值。通过这种方式,用户或自动化过程能够精确地控制要在合成图像中描绘的3D对象的变形。在其他示例中,自动化过程的用户能够使用来自物理引擎的动画数据来精确控制要在合成图像中描述的3D对象的变形。
简单来说,发明描述了一种以可控方式计算动态场景图像的方法,以便用户或自动化过程能够轻松地控制动态场景的动画。
在一个实施例中,所述方法包括接收对3D对象的变形的描述,其中描述包括来自物理引擎或铰接对象模型的原始3D元素的cage和相关动画数据。对于图像的像素,计算从虚拟camera通过所述像素进入根据动画数据动画的cage的光线,并在所述光线计算多个样本。每个样本都是其中一个3D元素中的3D位置和视图方向。
然后,所述方法计算样本到cage的规范版本的转换,以产生转换的样本。对于每个变换后的样本,查询一个学习到的3D场景的亮度场参数化,以获得一个颜色值和一个不透明度值。接下来,将体三维绘制方法应用于颜色和不透明度值以产生图像的像素值。
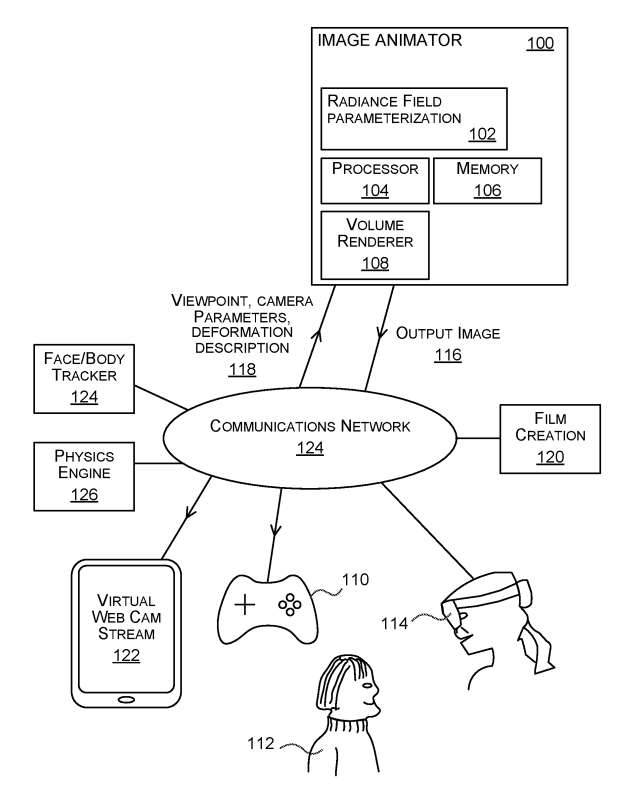
图1是用于计算动态场景合成图像的图像动画器100的示意图。在一个实施例中,图像动画器100部署在与诸如头戴式显示设备的头戴式计算机114通信的个人计算机或其他计算设备。在其他实施例中,图像动画器100部署在头戴式计算机114的配套计算设备中。
图像动画器100包括亮度场参数化102、至少一个处理器104、存储器106和体三维渲染器108。辐射场参数化102是一个神经网络,或随机决策森林,或支持向量机或其他类型的机器学习模型。它训练来预测一个动态场景的规范空间中的三维点和视图方向的颜色和不透明度值对。亮度场参数化102是一个缓存,用于存储规范空间中三维点与颜色和不透明度值之间的关联。
体三维渲染器108是一种计算机图形体积渲染器,它沿光线获取三维点的颜色和不透明度值对并计算输出图像116。
所述图像动画器100配置为接收来自诸如头戴式计算机114或其他客户端设备的查询。查询通过通信网络124从客户端设备发送到图像动画器100。
来自客户端设备的查询包括虚拟camera的指定视点、虚拟camera固有参数的指定值和变形描述118。图像动画器100接收查询并作为响应生成合成输出图像116,它将其发送到客户端设备。
客户端设备将输出图像116用于各种目的,例如生成用于由混合现实头戴式计算设备显示的全息图。图像动画器100能够根据需要计算动态3D场景的合成图像,用于特定指定所需的动态内容和特定指定的视点。
在一个示例中,动态场景是一个说话人脸。图像动画器100能够从多个视点并具有任何指定的动态内容计算人脸的合成图像。指定视点和动态内容的非限制性示例有。通过使用变形描述,可以控制在生成的合成图像中描绘的动态场景内容。
图像动画器以一种非常规的方式操作,使动态场景的合成图像能够以可控的方式生成。
图像动画器100通过使以动态场景的内容和视点可控的方式计算动态场景的合成图像来改进底层计算设备的功能。
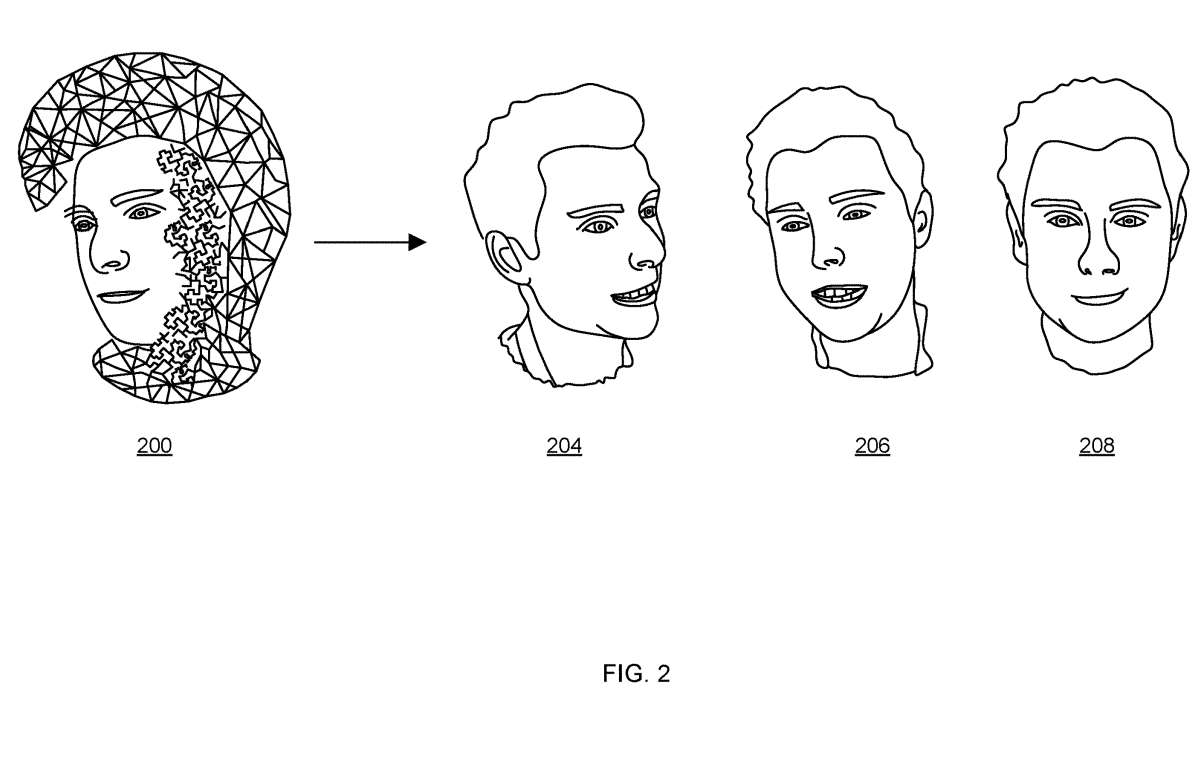
图2显示了使用图1的图像动画器100计算的人的头部的变形描述200和三个图像204、206、208,每个图像显示了以不同方式动画的人头,例如张嘴或闭口。
对于一般的物体,如椅子,cage里的对象周围的体积是有用的,因为用体三维渲染方法建模会产生更逼真的图像,cage只需要近似网格。这减少了具有许多部分的对象的cage的复杂性,并且允许对具有相似形状的相同类型的物体使用相同的cage。cage可以直观地变形,并由用户控制。
人脸是一个特别困难的情况,但一旦使用发明所述的技术训练了辐射场,就有可能泛化到任何几何变形。微软表示,这为在增强现实/虚拟现实环境中使用体三维模型提供了新的可能性。
在一个例子中,变形描述200被称为体三维变形模型Vol3DMM,这是一个参数化的3D面部模型,它使用骨架和混合形状来动画人的头部表面网格和网格周围的体积。
用户或自动化过程能够指定Vol3DMM模型的参数值,并用于使Vol3DMM模型动画化,以便创建图像204到208。使用Vol3DMM模型的不同参数值分别生成3幅图像204 ~ 208。Vol3DMM用一系列的体积混合形状和骨架来动画一个体积网格。
通过扩展参数化3DMM面部模型的骨架和混合形状,可以定义Vol3DMM的骨架和混合形状。骨架有四块骨头:控制旋转的根骨、颈骨、左眼骨和右眼骨。要在Vol3DMM中使用这个骨架,可以通过最近顶点查找,将线性混合蒙皮权重从3DMM网格的顶点扩展到四面体的顶点,即每个四面体顶点具有3DMM网格中最近顶点的蒙皮权重。
通过将3DMM模型的224个表情混合形状和256个单位混合形状扩展到其模板网格周围的体积来创建体积混合形状。要创建四面体嵌入,从通用网格创建一个单一的体三维结构,并创建一个精确的嵌入。
在一个示例中,骨骼或混合形状的确切数量继承自所选择的3DMM模型的特定实例,但发明描述的技术可以应用于使用混合形状和或骨骼来建模面部、身体或其他对象的不同3DMM模型。
通过这种构建,Vol3DMM可以实现控制并摆姿具有与3DMM人脸模型相同的身份、表情和姿态参数α、β、θ。这意味着可以通过改变α, β, θ来使用建立在3DMM面部模型的面部追踪器来动画它。
更重要的是,只要面部模型与训练框架很好地拟合,它就可以泛化到3DMM面部模型可表示的任何表情。在训练过程中,使用参数α, β, θ对Vol3DMM的四面体网格进行摆位来定义物理空间,而通过对身份参数α的Vol3DMM进行摆位,并将β, θ设置为零作为中立姿态。
在一个示例中,从所选择的3DMM模型的具体实例继承了对身份、表情和姿态的分解。然而,训练和/或动画技术通过为所选的特定3DMM模型构建相应的Vol3DMM模型来适应不同的分解。
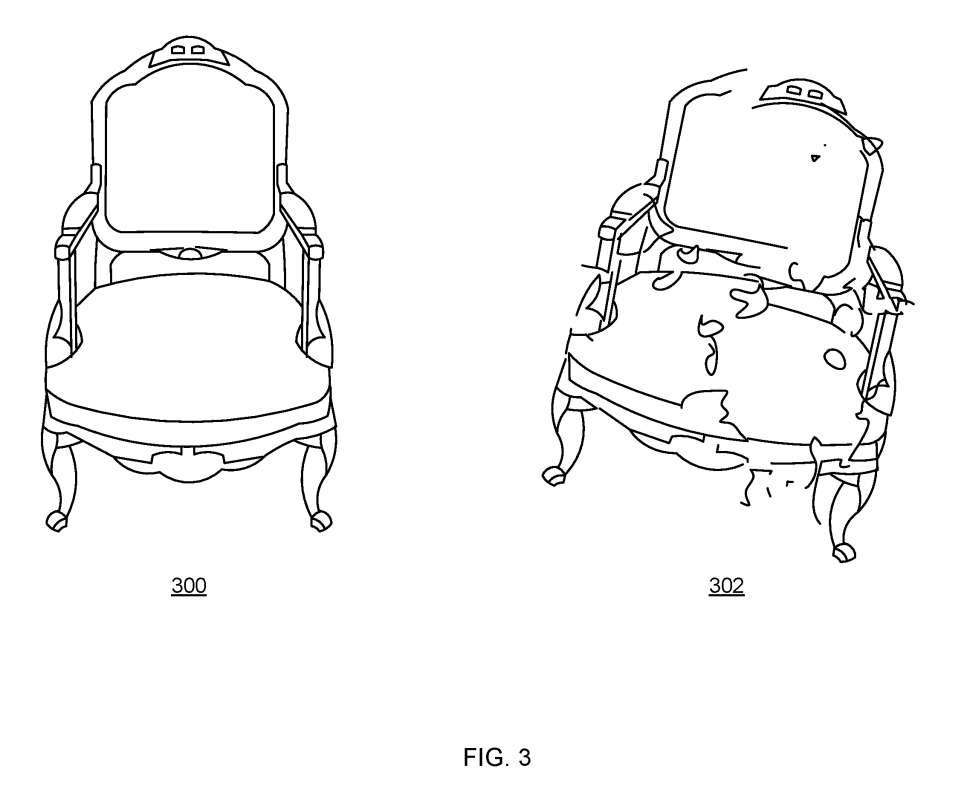
图3示出使用图1的图像动画器计算的椅子300和椅子破碎的合成图像302。在这种情况下,变形描述包括围绕椅子300的cage,其中cage由诸如四面体、球体或长方体的原始3D元素形成。变形描述同时包括来自物理引擎的关于对象在破碎时如何表现的规则等信息。
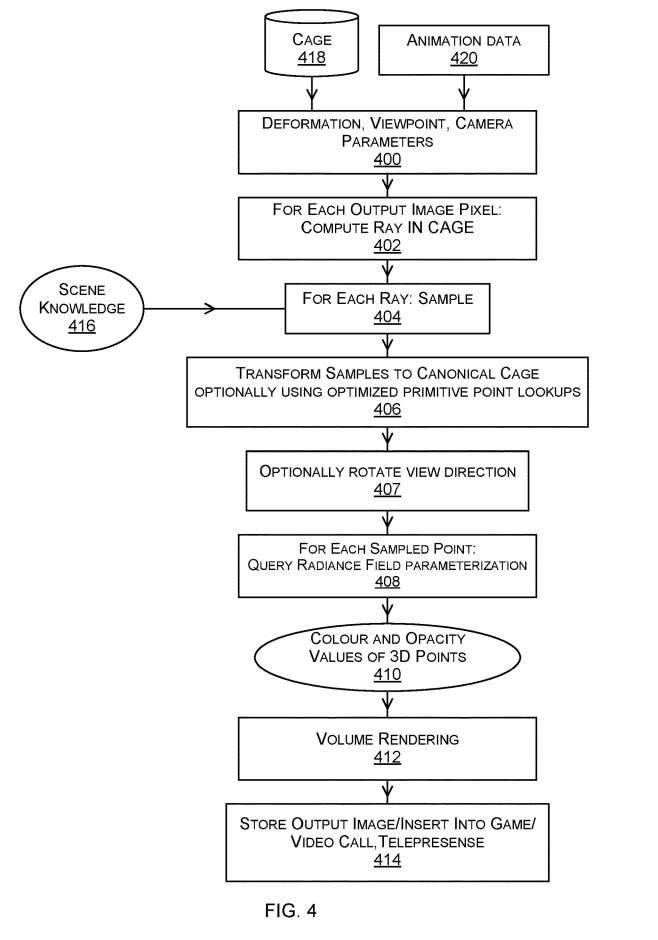
图4是由图1的图像动画器执行的示例方法的流程图。
输入400包含一些或所有变形描述、视点、固有camera参数的默认值。输入400来自用户或来自设备或其他自动化过程。在一个示例中,根据从混合现实计算设备接收的状态进行输入400。
变形描述包括原始三维元素的笼418。原始3D元素的cage表示在图像中描绘的3D对象和从所述3D对象延伸的体三维。当3D对象是人的头部或身体时,所述cage包括具有多个体积混合形状的体积网格和骨架。当3D对象是椅子或其他3D对象时,则通过使用Marching Cubes从学习到的辐射场体积密度计算网格并计算网格的四面体嵌入,从学习到的辐射场参数化中计算cage。
使用cage来控制和参数化体三维变形,使变形能够实时表示并应用于场景,并允许通过改变cage的几何形状来直观地进行控制
在操作402,动态场景图像生成器计算多个光线,每个光线与将由图像动画器生成的输出图像116的一个像素相关联。对于给定的像素,图像动画器计算一条从虚拟摄像机穿过像素进入包含cage的变形描述的光线。为了计算光线,图像动画器使用几何图形和相机固有参数的选定值以及相机的视点。光线在可能的情况下并行计算,以便提高效率,因为每个像素有一条光线要计算。
在404,对每条光线采样。
在操作406中,图像动画器将样本从变形描述cage转换为规范cage。规范cage表示处于休息状态或其他指定的原始状态的3D对象,例如参数值为零的状态。
操作407可选,并且包括旋转至少一个射线的视图方向。在这种情况下,对于其中一个转换的样本,在查询学习到的亮度场之前,旋转样本光线的视图方向。在实际应用中,计算一小部分原始三维元素的视向旋转R,并通过最近邻插值将R的值传播到剩余的四面体,可以获得较好的效果。
在一个示例中,所学习的亮度场参数化102是cage的规范版本中的3D点和视图方向以及颜色和不透明度值之间关联的缓存,通过查询使用包含来自多个视点的动态场景图像的训练数据训练的机器学习模型获得。通过使用值的缓存而不是直接查询机器学习模型,可以实现显着的速度提升。
对于每条光线,体三维渲染412方法应用于沿着该光线计算的颜色和不透明度值,以产生输出图像的像素值。
在408,对于每个采样点,动态场景图像生成器查询亮度场参数化102。亮度场参数化已经被训练来产生颜色和密度值,给定一个点在规范cage和一个相关的观察方向。
作为对每个查询的响应,辐亮度场参数化产生一对值,包括规范cage中采样点的颜色和不透明度。以这种方式,在应用变形描述的情况下计算规范cage中3D点和视图方向的多个颜色和不透明度值410。
相关专利:Microsoft Patent | Computing images of controllable dynamic scenes
名为“Computing images of controllable dynamic scenes”的微软专利申请最初在2022年9月提交,并在日前由美国专利商标局公布。
需要注意的是,一般来说,美国专利申请接收审查后,自申请日或优先权日起18个月自动公布或根据申请人要求在申请日起18个月内进行公开。注意,专利申请公开不代表专利获批。在专利申请后,美国专利商标局需要进行实际审查,时间可能在1年至3年不等。
另外,这只是一份专利申请,不代表一定通过,同时不确定是否会实际商用及实际的应用效果。