微软AR/VR专利通过搜索2D图像与3D点云的对应关系实现直接定位
通过搜索2D图像与3D点云之间的对应关系来实现直接定位
(映维网Nweon 2024年08月29日)在定位过程中,传感器数据用于找到环境中实体相对于环境的3D地图的3D姿态。传统的方法主要是从参考图像创建的3D地图,但这存在数个局限性。首先,需要可视图像作为映射和查询步骤的输入。然而,使用环境的可视化图像通常会带来安全风险,因为获得对可视化图像的访问权限的恶意方会获得有关环境的信息。
另一个限制是准确性,因为从参考图像创建的3D地图不如从主动3D扫描创建的3D地图准确。另外,视觉外观随着光照或时间的变化而急剧变化,这给查询和地图之间的匹配带来了重大挑战。
在名为“Matching between 2d and 3d for direct localization”的专利申请中,微软认为提出可以通过搜索2D图像与3D点云之间的对应关系来实现直接定位,从而改善以上限制,因为构建3D地图不需要视觉数据作为输入。
在一个实施例中,确定实体的位置包括:接收包括描绘实体的环境的2D图像的查询;搜索所述查询与所述环境的3D地图之间的匹配。3D地图包括3D点云,而匹配指示实体在环境中的位置。
搜索匹配包括:从2D图像中提取称为图像描述符的描述,;从所述3D点云提取称为点云描述符的描述符;将所述图像描述符与所述点云描述符相关联以产生对应关系;使用所述对应关系来估计所述实体的位置。
微软指出,利用主动深度扫描仪进行测绘同时提供了更高的定位精度的机会,因为3D地图表示对光照变化的鲁棒性增加。另外,这项技术提供了更多的安全性,因为视觉图像不作为3D地图的一部分存储。
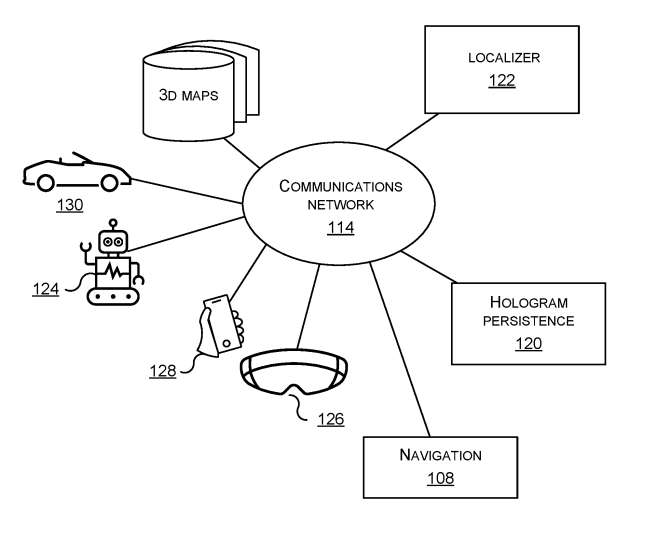
图1是用于计算实体相对于3D地图的3D位置和方向的定位器122的示意图。图1显示了各种实体的例子,包括自头戴式计算机。
每个实体具有捕获装置,以捕获实体的环境的2D图像。2D图像之一通过通信网络114发送到定位器122。定位器接收作为查询3D地图的查询的2D图像。定位器通过通信网络114访问一个或多个3D地图106。3D地图是描绘实体环境的3D点云。
定位器使用所述2D图像查询一个或多个3D地图,以相对于所述3D地图直接定位所述实体。直接定位是指通过搜索2D图像与3D点云之间的对应关系来实现定位。定位器122产生发送查询图像的实体的姿态作为输出。
在一个实施例,定位器将姿势返回给发送查询图像的实体。定位器将姿态发送到诸如全息图持久性应用程序120、导航应用程序108或其他应用程序之类的应用程序。在全息图持久化应用的情况下,姿态可以是佩戴头戴式计算机126的人的姿态,并且用于持久化描绘用户的全息图。
在图1的示例中,定位器122部署在云中或部署在远离所述实体的计算实体上。然而,定位器122的功能可以部署在实体之上。
在一个实施例中,定位器122接收来自实体的查询,其中所述查询是3D点云而不是2D图像。当实体124、126、128、130没有用于捕获2D图像的捕获装置,但具有用于捕获3D点云的捕获装置时,这是有用的。
定位器122接收为3D点云的查询,并搜索查询与实体环境的3D地图之间的匹配。本例中的3D地图包含2D图像。
定位器能够在查询和环境的3D地图之间进行匹配,这使得定位器能够以一种非常规的方式进行操作,从而实现更准确、更安全的实体定位。
定位器通过将图像描述符与点云描述符相关联,使底层计算设备的功能受益。
图2是3D地图200的示意图,地图200是三维点云。图2中的3D地图是一个由建筑物、街道和大教堂组成的城市。图2中的3D地图是通过使用一个或多个3D扫描仪构建,3D扫描仪直接产生场景的3D点云,但不包含环境的视觉图像。3D点云可以通过环境图像进行着色。
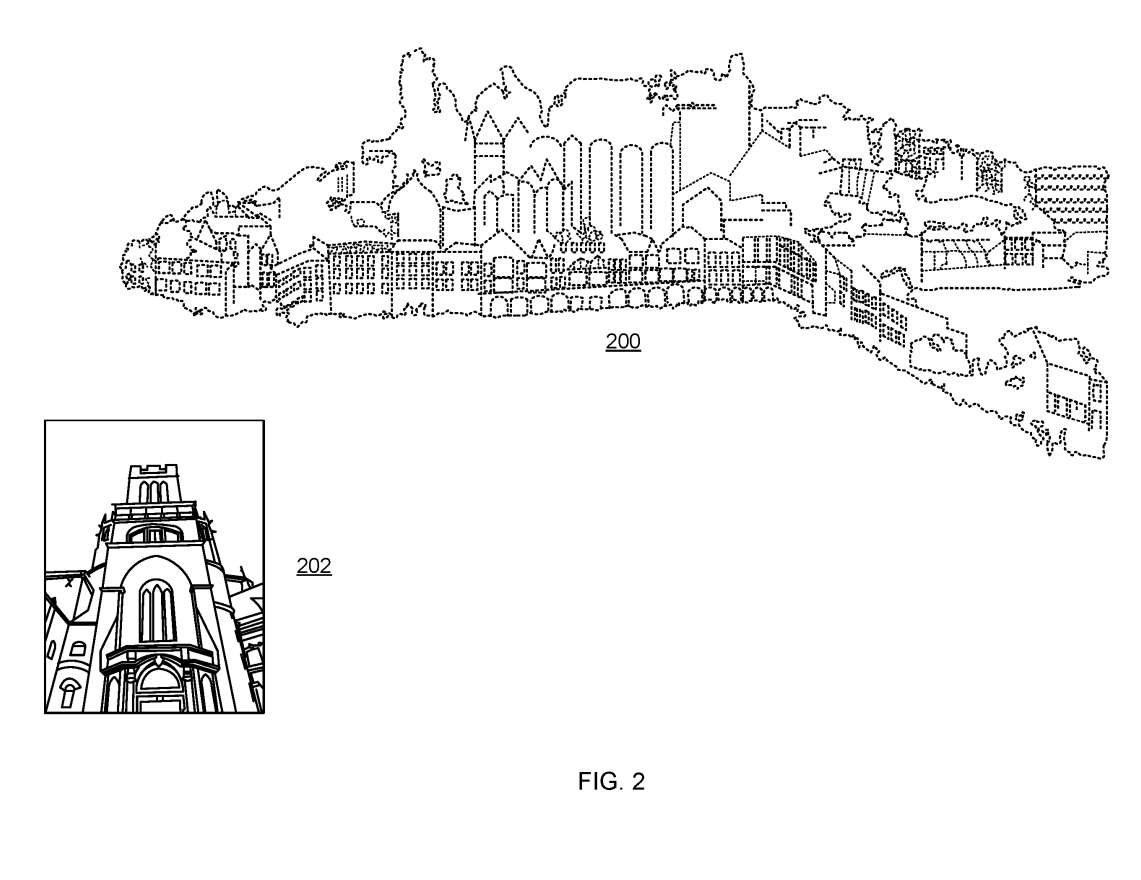
图2示出由环境中的实体捕获的查询图像202,并由定位器122用于计算实体相对于3D地图的3D位置和方向。
图3是更详细的定位器122示例。定位器122包括用于从3D点云300提取描述符的第一提取器304。所提取的描述符在这里称为点云描述符308。3D点云300是3D地图106、200或3D地图的一部分。
提取器304是用于从点云提取描述符的任何功能,例如特征检测器。在一个实施例中,提取器304将点云与核进行卷积,以检测描述符,如斑点、边缘、表面或其他特征。提取器304使用模板匹配来检测点云中的描述符。提取器304是经过训练的机器学习模型。
所述定位器122包括用于从图像302提取描述符的第二提取器306。所提取的描述符在这里称为图像描述符316。所述图像302是由捕获装置捕获的2D图像。第二提取器306是用于从图像提取描述符的任何功能,例如特征检测器。
第二提取器306将图像302与核进行卷积,以检测诸如斑点、边缘、不连续或其他特征的描述符。第二提取器306使用模板匹配来检测图像302中的描述符。第二提取器306是一个经过训练的机器学习模型。
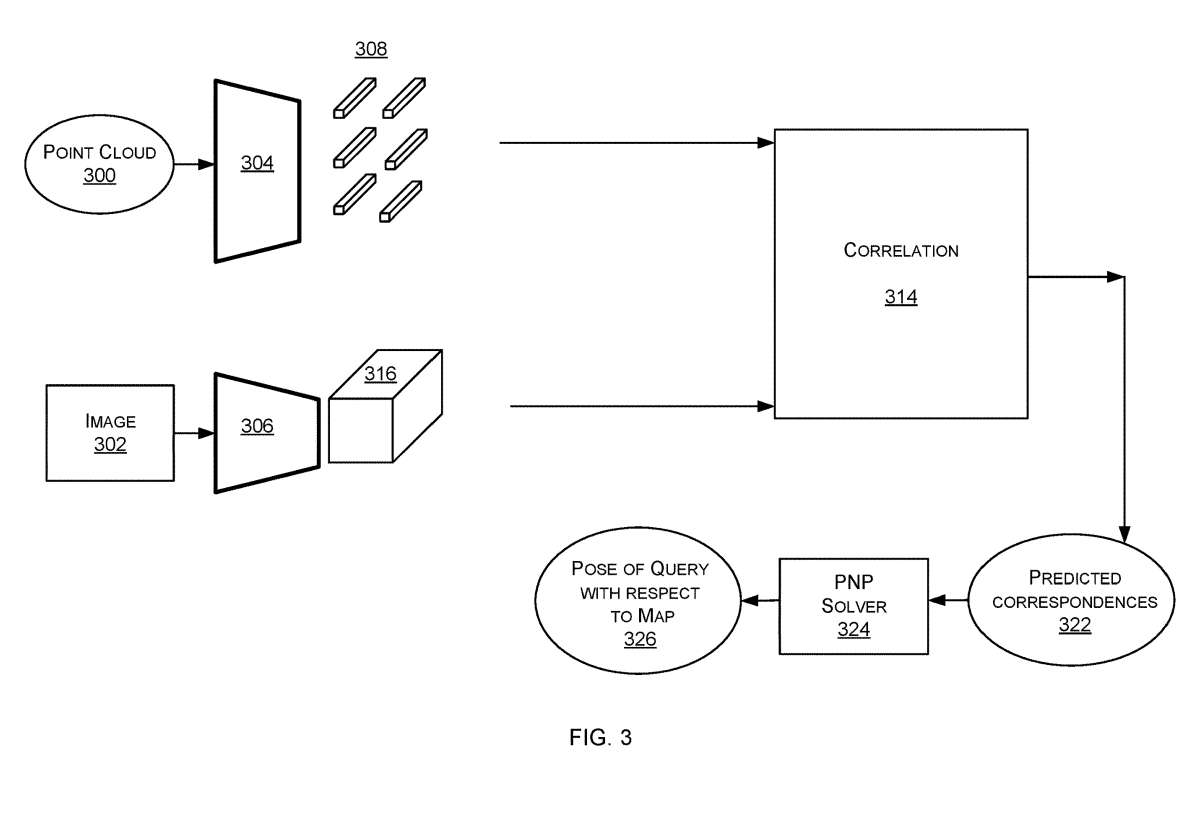
如图3所示,第一和第二提取器304、306可以并行操作以提高效率。
将点云描述符308和图像描述符302输入到相关处理314。相关过程计算点云描述符308和图像描述符316之间的相似性。对于每个图像描述符,计算与每个点云描述符308的相似性。使用任何相似度度量来计算相似度。
因此,对于包含图像描述符和点云描述符的一对,计算数值相似值。选取相似性值大于阈值的图像描述符-点云描述符对。每一对都称为对应关系,因为很可能两个描述符都描述了环境中的相同元素。
所选择的对是由相关过程预测的对应322,并输入到PnP求解器324。PnP求解器使用预测的对应关系来计算实体相对于地图的姿态。
利用子提取器和关联过程,这可以给出一种有效、准确的3D地图实体定位方法。3D地图不需要有相关的2D图像,即不需要将查询图像与3D地图的参考图像相匹配。由于3D地图本身可以由3D扫描数据而不是参考图像形成,所以精度得到了提高。
另一种方法寻求检测和描述点云和图像中的特征。然而,在两种不同的模态中检测可重复点极具挑战性,严重影响匹配性能。相比之下,目前的技术不依赖于任何检测步骤,所以更广泛地适用于具有挑战性的场景。
与替代方法相比,图3的定位器无需实体的初始姿态即可操作。
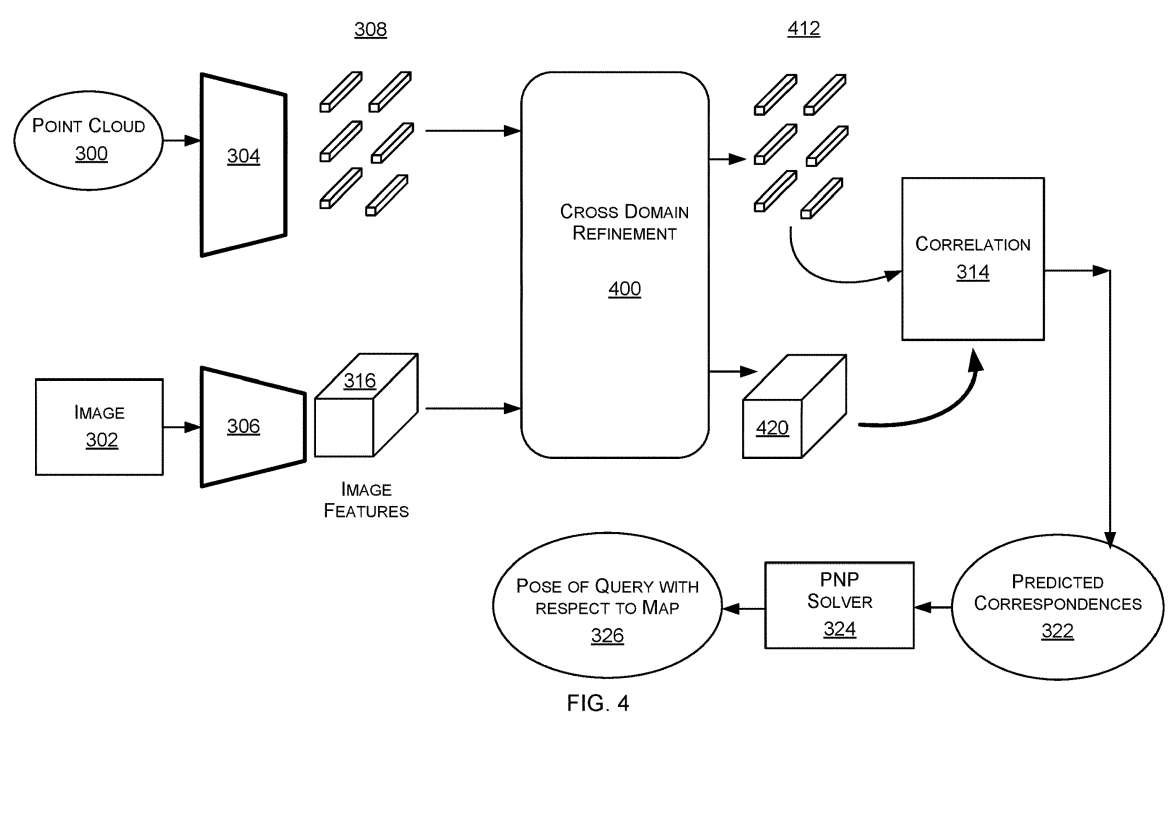
图4是定位器122的另一个示例。在这里,定位器具有跨域细化模块400,其作用是使用来自图像描述符的信息来细化点云描述符,并利用点云描述符的信息对图像描述符进行细化。
跨域细化模块是在关联之前,使用点云描述符对图像描述符进行细化,并使用图像描述符对点云描述符进行细化的任何过程。使用跨域细化模块400促进了相关过程314,因为点云描述符308在性质上与图像描述符316相似。跨域细化模块400通过在关联之前添加信息交换,帮助弥合2D和3D领域之间的差距,从2D和3D领域中提取不同的描述符。
跨域细化模块400的输出是细化的点云描述符412和细化的图像描述符420。将细化的描述符以与上述图3相同的方式输入到相关过程314中。对于图3,相关过程314输出预测对应322,PnP求解器324使用相关对应326计算查询图像相对于地图的姿态。
图4所示的定位器可以从实体捕获的3D点云估计实体的3D位置和方向。在这些实施例中,点云300已由实体捕获,并且图像302是来自3D地图的图像。即,实施例中的3D地图包括多个2D图像。对于每个2D图像,已计算用于捕获所述2D图像的捕获设备的3D位置和方向。定位器输出查询相对于3D地图的姿态。
图5是包含具有至少一个交叉注意层504的训练过的机器学习模型的跨域细化模块。交叉关注层是处理点云数据的节点与处理图像数据的节点之间存在连接的层。通过使用经过训练的机器学习模型而不是基于规则的过程来提高定位精度。
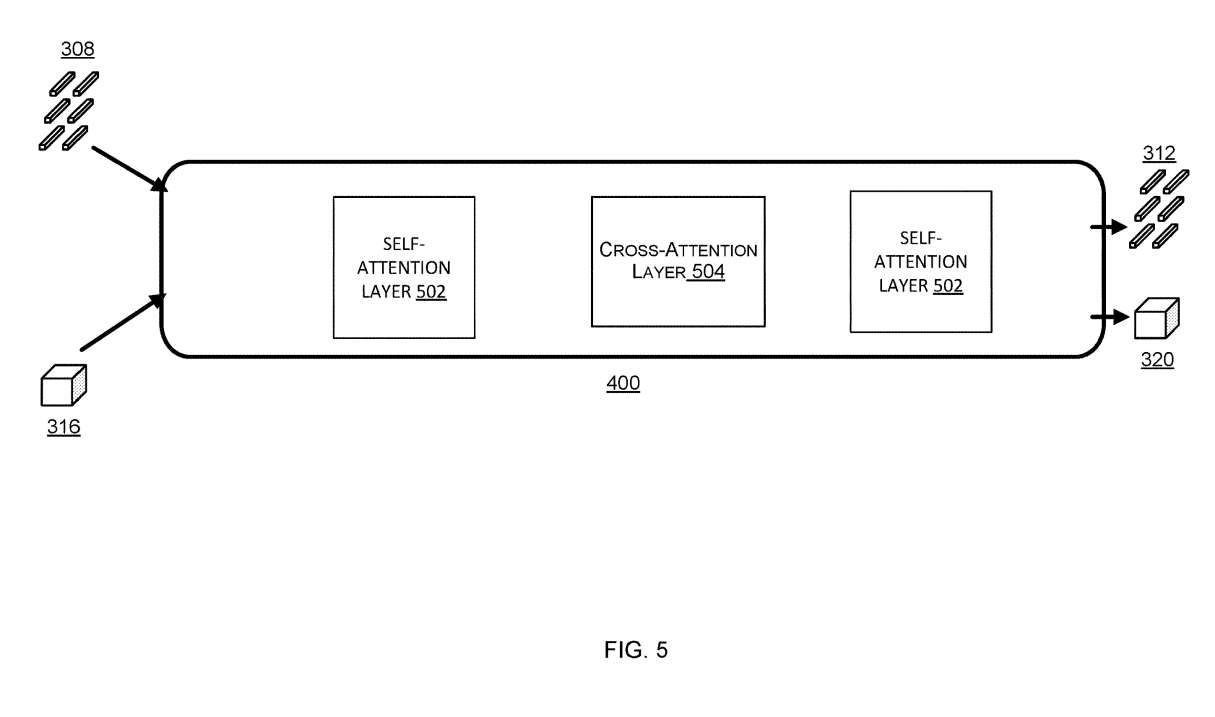
在图5的示例中,跨域细化模块400包括使用训练过的机器学习模型,模型具有至少一个用于图像描述符的自注意层502和至少一个用于点云描述符的其他自注意层。
自注意层只在处理一个领域数据的节点之间建立连接。在一个示例中,跨域细化模块400包括夹在两个自注意层502之间的交叉注意层504。采用这种三明治结构可以获得精确的定位性能。
在图5的示例中,为了增强每个域中的情景信息,对描述符应用并行的自注意层。接下来是跨注意层504,其中来自一个领域的每个描述符都使用来自另一个领域的描述符进行细化。通过堆叠这样的自我或交叉注意层504的几个块,可以学习更多的代表性描述符,从而显著提高相关性能。
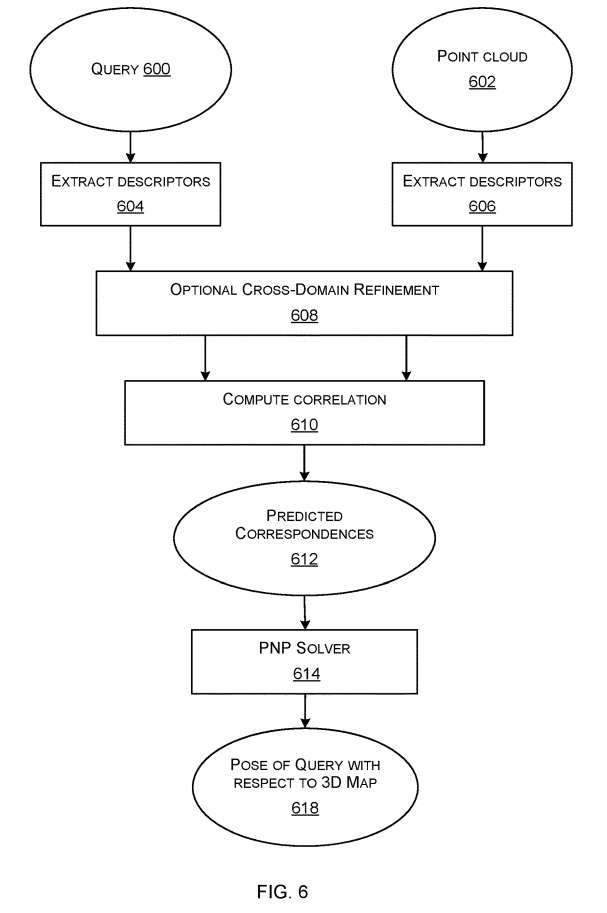
图6是由诸如图1的定位器122的定位器执行的方法的流程图。定位接收由环境中的实体捕获的查询600。
定位器从查询图像600中提取604个描述符以生成图像描述符。定位器从点云602中提取606个描述符以产生点云描述符。
查询600是3D点云,例如由实体捕获的3D扫描。定位器同时接收环境的3D地图602,在这种情况下包括2D图像,每个2D图像具有用于捕获2D图像的捕获设备的3D位置和方向。
定位器从查询600中提取604个描述符以生成点云描述符。定位器从形成3D地图602的2D图像中提取606描述符以产生图像描述符。
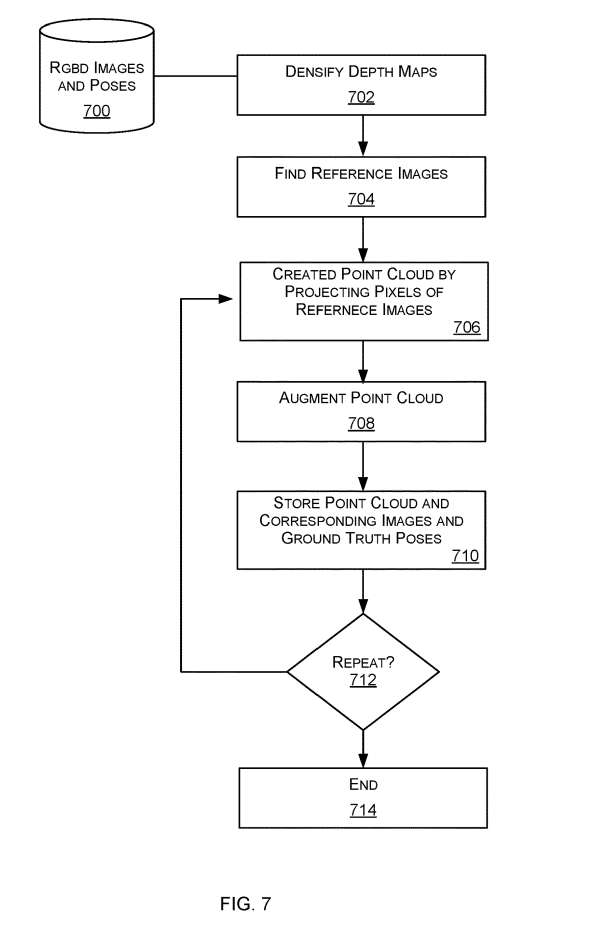
图7是创建训练数据的方法的流程图,所述方法用于训练诸如图1中的定位器122的定位器。对于查询是2D图像的情况和查询是3D点云的情况,训练数据适用于训练定位器122。
所述方法访问的数据集700是红绿蓝深度RGB-D图像和相关姿势的存储。RGB- D图像是RGB图像和深度图像,它们通常在同一时间从相同的视点捕获。使用任何深度摄像头捕获深度图像。与RGB- D图像相关联的姿态是用于捕获RGB- D图像的RGB摄像头和深度摄像头的位置和方向。
进程选择一个RGB-D映像作为查询映像。对于每个查询图像,过程查找多个共视图像。共视图像是描述相同环境或至少部分相同环境的图像。因此,共视图像很可能是从具有与查询图像相似姿态的捕获设备捕获。
为了创建点云,将具有有效深度的参考图像的像素点投影到3D并将其转换为世界坐标系。为了评估像素点是否具有有效的深度,从RGB-D图像的深度图像中获取深度值,并将其与至少一个经验定义或由算子设置的阈值进行比较。原始RGB-D数据集提供的真地位姿也被转换为世界坐标系。从数据集中检索世界坐标系与查询坐标系之间的真值转换。
使用图7所示的训练数据集生成管道,可以生成两个查询图像和一个点云,以及它们的ground-truth姿态。这允许联合监督相同点云和两个不同图像之间的网络预测。这是有益的,因为它使学习到的点云特征同时对不同的摄像头视点具有鲁棒性。
在一个示例中,从RGB-D图像中计算训练数据的方法是:选择两个RGB-D图像作为查询图像,找到多个与任意一个查询图像共可见的RGB-D图像中的其他图像作为参考图像,将参考图像的像素投影到3D中形成单个点云,并将查询图像和点云存储为训练数据项。
另外,在这种设置中,可以与标准2D-2D匹配网络一起联合训练定位器122。通过在定位器122和2D-2D匹配网络之间共享图像描述符的提取器,从而显著提高定位器122的性能。
相关专利:Microsoft Patent | Matching between 2d and 3d for direct localization
名为“Matching between 2d and 3d for direct localization”的微软专利申请最初在2022年11月提交,并在日前由美国专利商标局公布。