微软提出FLAG:从稀疏头显信号生成AR/VR化身全身姿势
生成逼真的人体表现
(映维网Nweon 2022年05月10日)混合现实技术提供了全新的人机交互方式,而人是所有应用的核心。所以,生成逼真的、高保真的人类表示是用户体验的关键。尽管外部传感器和摄像头可以提供相当出色的效果,但仅通过头显来生成逼真的人体表现依然是一个具有挑战性的问题。从HoloLens和Quest等头显获取的相关数据仅限于头部的位置和方向,以及手的位置和方向。对于整体人身姿势和运动来说,这是一个非常不完整的信号。
在《FLAG: Flow-based 3D Avatar Generation from Sparse Observations》的论文中,微软提出了一种基于稀疏输入的conditional normalizing flows的新方法。具体来说,团队通过Flow-based模型学习给定头部和手部数据的全身姿势条件分布,而所述模型能够在3D姿势分布和基础分布之间实现可逆映射。然后,模型的可逆性允进一步学习从条件到相同基础分布中的高likelihood区域的概率映射。研究人员将这种方法命名为Flow-based 3D Avatar Generation(FLAG)。
这种设计的优点主要包括:
- 首先,与基于VAE的姿势先验中的近似likelihood相比,使用Flow-based生成模型可以实现精确的姿势likelihood计算;
- 其次,生成模型的可逆性允许计算oracle latent code。在训练过程中,oracle latent code将充当映射函数的ground truth。这使得能够学习从观察到的头部和手到latent空间的代表性映射,从而令所述方法成为一个强大的预测模型;
- 最后,当在posed空间或latent空间中进行优化时,使用所述模型作为姿势先验,可以在latent空间提供优越的初始化,使得优化非常有效。
将Normalizing Flows作为likelihood-based生成模型,这为数据的表达概率分布提供了一条途径。与VAEs不同,VAEs的主要挑战是找到合适的近似后验分布, Normalizing Flows只需要定义简单的基础分布(先验分布)和一系列双射变换。
对于微软提出的方法,团队的任务是在给定稀疏观测xH和形状参数β的情况下生成全身姿势xθ。xθ∈ R3×J表示关节旋转,作为J身体关节的轴角向量,而xH∈ R9×K代表全局6D关节旋转。所述信息可以从人体的参数模型中获得,例如SMPL。
从xH生成xθ的一种有效方法是,通过Flow-based模型fθ,了解给定观测xH和β的身体姿势的分布。尽管这种方法可以有效地提供给定姿势的likelihood,但生成过程依然不完整。为了生成给定xH和β的新姿势,需要对latent变量进行采样。然而,取样过程完全独立于观察结果。尽管依赖latent空间z=0(全零向量)的平均值作为latent code来生成完整姿势,但研究人员认为存在一个比z=0更好地表示xθ的latent code。
为了获得这样一个latent code,团队提出的模型估计了normalizing flow based分布中的一个子区域N(µH,∑H),给定xH和β,从中可以对latent变量进行采样以生成全身姿势。在测试时,为了生成给定xH和β的全身姿势,研究人员从zH中抽取一个latent code∼ N(µH,∑H),并将其用作zθ的近似值。zθ是生成全身姿势的latent code。
他们使用这个latent估计通过xˆθ=fθ(zH,[xH,β])生成全身姿势。接下来,定义fθ,并描述如何建模N(µH,∑H)。
团队用normalizing flow模型来模拟xθ的分布。模型fθ是以xH和β为条件的conditional RealNVP。这可以通过简单可逆变换的组合将xθ从姿势分布映射到基本分布(反之亦然)来实现,每个变换都可以拉伸或收缩其输入分布。
尽管研究每个可逆变换在从基本分布中采样的zθ生成人体姿势时的贡献并不直接,但研究人员希望每个连续变换都能为其作用的人体姿势的传入分布增加表现力。为了直观地理解每个变换的作用,他们将人类姿势如何通过模型中的所有变换形成可视化。
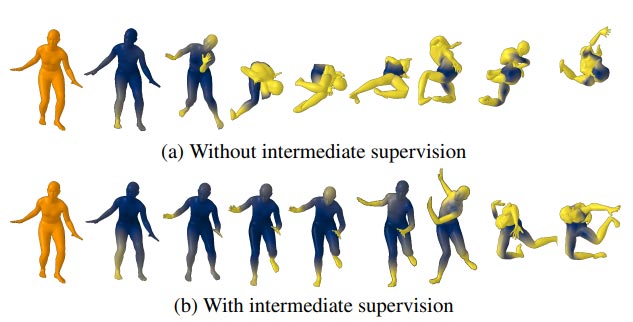
如图3a所示,对中间分布的大多数可观察到的修改都发生在后面的阶段,其中,可以观察到一个类似人类的姿势正在形成。研究人员认为,这是因为监督的唯一来源是明确指导最后一个转换块的GT姿势。为了简化训练并充分利用fθ中的每个变换块,他们建议在fθ中引入中间监督。
除了将GT姿势作为最后一个变换块的输入,团队同时将GT姿势作为中间变换块的输入,就好像它们是子网络的最后一个块一样。这是可能的,因为fθ中的变换不会修改数据维度。因此,鼓励中间转换块产生合理的人体姿势,并充分发挥其能力。图3b通过有中间监督和无中间监督的变换来说明姿势演变。图2同时表明了中间监督会提高生成姿势的合理性。
为了生成一个新的姿势,给定xH和β,需要从基本分布中采样一个latent变量z,并使用它生成一个姿势xˆθ=fθ(z,[xH,β])。在标准的flow-based模型中,尽管可以产生有效的解决方案,但微软认为所述方法并不构成最佳解决方案,证据是normalizing flow的可逆性。
由于oracle latent code在训练期间已知,所以模型能够将条件(xH和β)映射到基本分布中的一个区域。利用z∗,当通过fθ从基本分布转换到posed空间时,可以考虑基本分布volume的变化,以及latent code周围概率质量的变化。团队用高斯函数对感兴趣区域建模,并学习其参数µH和∑H=diag(σH)2。
给予稀疏的观察。当只观察头和手时,存在多个看似合理的全身姿势。对于每个看似合理的姿势,需要知道基本分布中相应的子区域。考虑到所述关键性质,团队设计了一个基于transformer的映射函数。
团队提出了一个基于transformer的模型来建模映射函数,并利用了在训练期间学习身体不同关节之间关系的self-attentino机制。简而言之,transformer编码器接收xH和β作为输入,并估计N(µH,∑H),其中µH训练为oracle latent code z的良好近似值。
为了使这种分布能够代表整个身体,团队做出了几种设计选择,并得出出图4所示的模型。首先,使用稀疏输入直接训练这样的模型具有挑战性。为了简化模型,研究人员定义了一个辅助任务,从transformer编码器的输出生成xθ。最初的目标是从全身关节重建xθ,并逐渐降低编码中的关节可见性(通过掩码),直到只提供头部和手。
为了进一步帮助transformer学习身体的表现,团队引入了另一个辅助任务,即根据观察到的关节预测latent关节。这种渐进掩码和预测(MaskedJointPredictor)让模型通过对输入中可用关节的attention(层)来推断全身表征。为了从transformer编码器中获得紧凑的表示,他们在输出关节上应用池(PoolH),并且只取头部和手部表示。
transformer编码器的输出是确定性的,不会给出预测姿势的不确定性估计。因此,微软建议根据transformer编码器的输出(通过ToLatentSpace),对人体姿势上的分类latent空间进行建模。团队可以从这个分布中采样一个离散的latent变量(通过Gumbel Softmax获得可微性),用定义的辅助任务生成xθ,或者使用整个latent表示来估计N(µH,∑H)(通过LatenregionApproximator)。
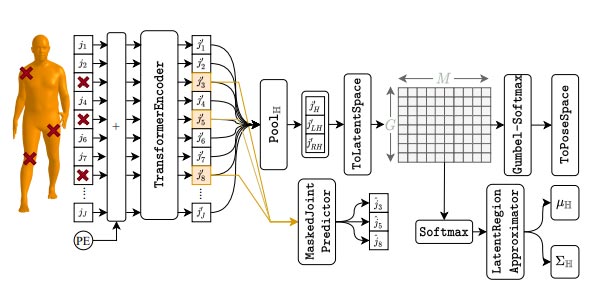
为了有效地模拟人体运动的复杂分布,研究人员需要一个相对较大的latent空间,从而产生大量的latent类别。为了解决这个问题,他们使用2D分类latent空间,如图4所示。团队建立了一个G维latent变量模型,每个latent变量负责M modes,使得能够使用MG one-hot latent code。
对于学习,团队使用了各种3D人体模型的数据集。尽管整个模型可以以端到端的方式进行训练,但他们观察到先训练fθ,然后再训练latent区域近似器非常有效,因为从一开始就可以获得有效的z∗。第二个训练阶段非常快速,4个GPU时间。
接下来,可以通过首先计算给定观测值的µH,生成给定xH和β的全身姿势,然后使用µH作为zθ的近似值,生成姿势xˆθ=fθ(µH,[xH,β])。为了进一步提高生成姿势的质量,可以同时使用flow based模型作为优化中的姿势先验,以最小化先验和数据的代价函数。优化既可以在posed空间中进行,又可以在latent空间中进行。值得一提的是,团队自始至终都使用LBFGS优化器。
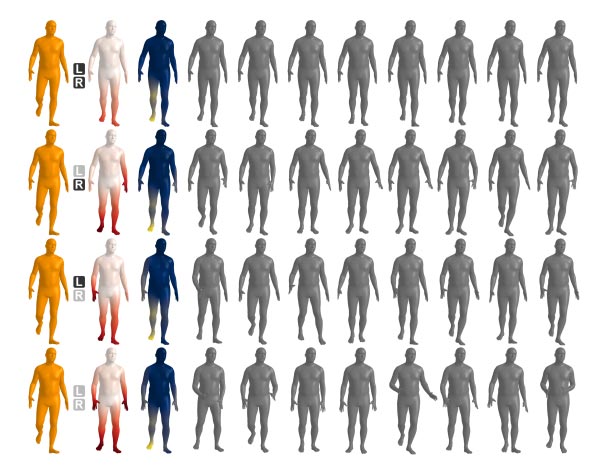
在实验中,团队首先在没有任何条件的情况下对VAE编码器-解码器进行全身训练。在下一步中,训练另一个VAE。由于研究人员提出的方法是一个条件姿势先验,他们将其与现有的条件姿势先验进行比较,然后根据问题设置进行调整。在图8中,微软证明了在部分或无手观察的情况下,FLAG可以生成高度合理的姿势。
尽管在大多数情况下,如果观察非常稀疏,FLAG都能够生成高度合理的姿势,但团队坦诚它可能无法生成复杂、不太常见的下半身姿势。另外,FLAG只使用静态姿势信息,所以扩展FLAG来使用时态数据是一个自然的研究方向。同时,团队只使用头显信号作为模型的输入,而在其他AR/VR场景中,可以使用其他模式,例如音频或环境扫描。
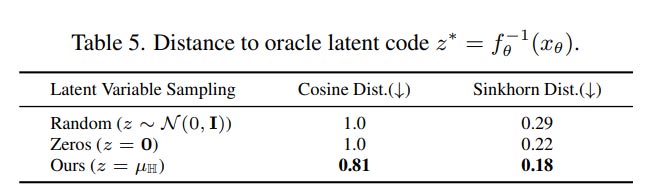
尽管FLAG的目标是找到更好的latent code来生成一个合理的姿势,但团队估计的latent code与oracle latent code之间可能依然存在相当大的差距(见表5)。不过,微软指出在这一领域的进一步探索可能会带来更忠实和准确的化身姿势。
相关论文:FLAG: Flow-based 3D Avatar Generation from Sparse Observations
总的来说,FLAG是一种从稀疏头显信号生成合理全身人体姿势的新方法。FLAG是一种条件flow-based三维人体生成模型。团队证明,由于latent变量采样机制,所述方法是一个强大的预测模型,并且在不同的优化设置下是一个有效的姿势先验。实验评估和消融研究表明,在具有挑战性的AMASS数据集上,所述的方法优于最先进的方法,同时需要更少的优化迭代,而且误差非常小。