微软专利探索眼球跳动误差,实现更精确HoloLens注视点交互
避免错误地将命令与目标对象以外的非目标对象关联
(映维网Nweon 2022年05月27日)随着眼动追踪技术的普及,眼动已经成为了AR/VR头显的一种重要用户输入机制。例如,眼动追踪传感器可用于确定用户眼睛的注视方向。然后,计算系统可以使用得到的注视方向来识别每条注视线相交的任何显示的虚拟对象。确定的注视方向随后可用于识别用户注视的对象。
通过这种方式,眼动追踪传感器可用于将由语音、手势、按钮或其他输入机制发出的用户命令与真实对象或虚拟对象相关联。
但是,使用眼睛注视来将命令与预期的真实对象或虚拟对象相关联可能存在困难。这在一定程度上是由于人眼自然进行的眼跳运动,亦即用户倾向于快速移动眼睛。例如,用户可能主要盯着一个感兴趣的对象,然后由于眼跳运动而短暂地瞥向场景中的其他对象/位置。如果仅根据检测到命令的时间将命令与对象关联,则可能出现错误地将命令与目标对象以外的非目标对象关联。
例如,HoloLens用户可能正在注视第一物理对象,并通过语音发出“放在那里”命令,从而将特定虚拟对象放置在所述第一物理对象。但由于眼跳运动,用户可能会在发出命令时短暂地注视第二物理对象。结果,计算设备或会错误理解用户意图,并将命令与第二物理对象相关联,从而无法将虚拟对象正确地放置在第一物理对象。
针对这个问题,微软在名为“Location-based entity selection using gaze tracking”的专利申请中提出了自己的解决方案:使用空间意图模型将用户输入与注视方向相关联。
简言之,计算设备在不同位置为不同的识别实体维护与时间相关的注意值。对于每个已识别的实体,根据眼睛注视采样计算注意力值,并随时间更新。
当接收到包括位置相关动作的用户输入时,计算设备利用空间意图模型将用户输入与选定的识别实体相关联。然后,可以基于用户输入和所选实体执行位置相关操作。所以当用户将目光从实体移开而不是立即移开时,实体与时间相关的注意值会在一段时间内衰减。
因此,即便用户由于眼跳运动而注视其他实体,空间意图模型都可以为正确选择的实体保持相对较高的注意值。
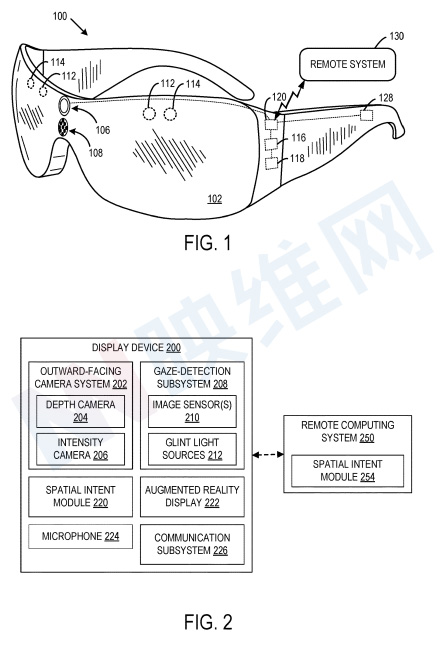
图2示出了示例头戴式显示设备200的框图。显示设备200包括前置摄像头系统202,摄像头系统202包括深度摄像头204和/或强度摄像头206。
显示设备200同时包括注视检测子系统208。注视检测子系统208包括一个或多个闪烁光源212和一个或多个图像传感器210。图像传感器210配置为捕捉用户每只眼睛的图像。显示设备200同时包括空间意图模块220,以帮助消除潜在的模糊注视信号。
如上所述,对于将用户输入与预期实体相关联,眼跳引起的模糊凝视信号造成了挑战。为了帮助消除与命令相关联的预期实体的歧义,空间意图模块220基于来自眼动追踪系统的注视采样,确定使用环境中每个识别实体的时间相关注意值。
当接收到指示执行位置相关动作的意图的用户输入时,空间意图模块220基于时间相关注意值确定要与输入关联的选定实体。通过在接收到眼动追踪采样数据时更新与时间相关的注意值,空间意图模块可以提供对作为用户注意力当前焦点的实体洞察。
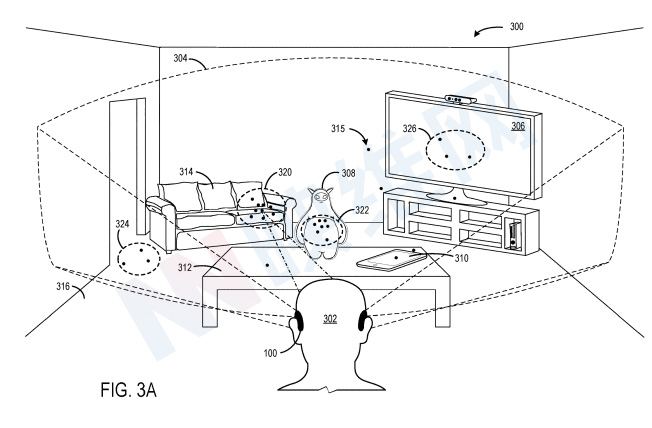
图3A-3C显示由佩戴显示设备100的用户302查看的场景300。场景300包括在视场304中可见的多个实体,例如房间中的对象、结构和表面。点代表眼睛注视位置,其由眼动追踪系统获取的眼睛注视采样确定。图3A中的示例实体包括平板电脑计算设备310、桌子312、沙发314和地板316等等。
包含每个虚拟和真实实体的位置和身份的实体数据可以存储在显示设备100的存储器中。可以使用任何合适的数据模型来维护实体信息。例如,实体的位置可以存储为真实世界空间模型的坐标系内的绝对位置、相对于显示设备100的位置或其他合适的数据模型。当显示的虚拟对象移动或物理对象移动时,可以更新位置信息。
眼动追踪传感器112检测用户眼睛的注视方向。显示设备100的控制器120可以将实体位置信息与注视方向进行比较,以确定注视方向是否与场景中的任何已识别实体相交。在图3A中,用户302正注视沙发314。
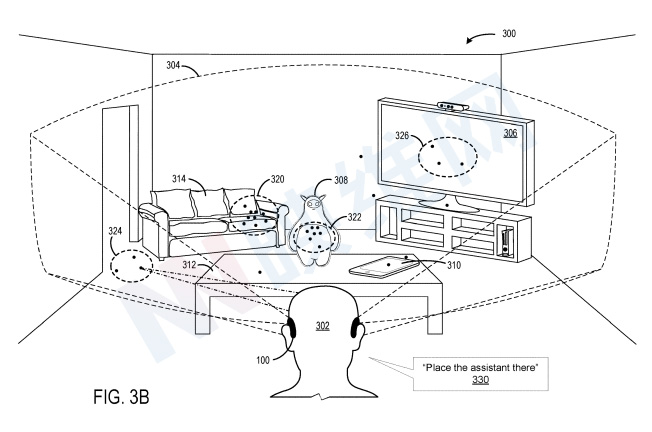
参考图3B,用户302进行语音输入以“放在那里”。鉴于指向沙发314的最近注视采样的数量,用户可能希望所述命令与沙发314相关联。但由于眼跳运动,眼动追踪传感器112记录在语音输入时或前后朝向地板316的眼睛注视采样。
在没有空间意图模型的情况下,用户输入可能与楼层316错误关联。然而,利用微软提出的技术,示例性空间意图模型包括场景中每个已识别实体的注意值,其中实体的注意值至少基于与实体相对应的所获取的注视采样数量,以及获取注视采样的时间。
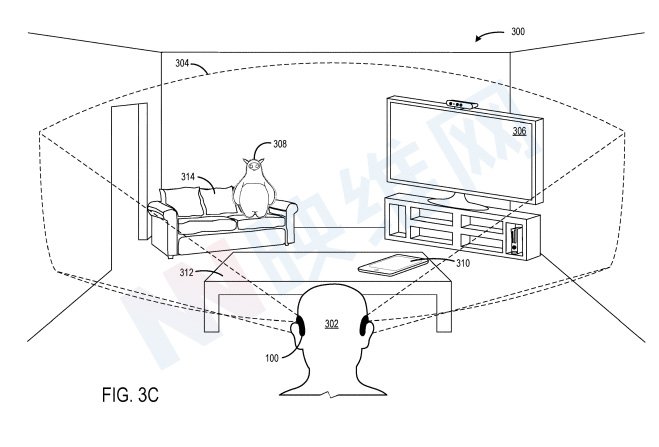
这里,作为与沙发314相对应的多个眼睛注视采样320,空间意图模型正确地确定所选实体是沙发314。如图3C所示,作为确定的结果,显示设备100通过将虚拟化身308放置在沙发314并执行位置相关动作。
空间意图模型可通过诸如泄漏积分器之类的数学模型来确定代表用户对不同实体的注意力的时间相关注意值。图4示出了与用户对图4的实体的注视相对应的示例时间相关注意值的图。
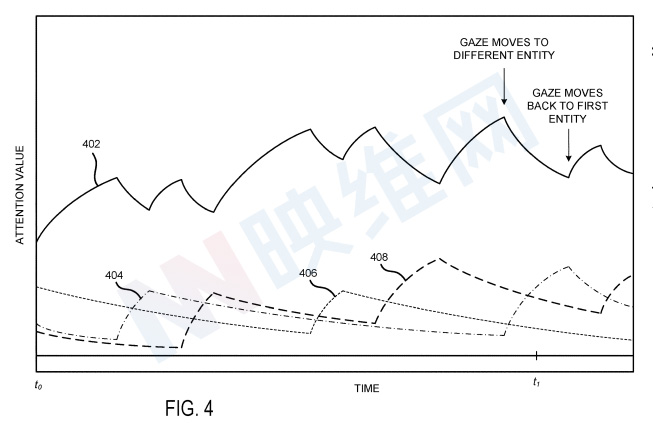
依赖时间的注意力值402模拟用户对沙发314的注意力。类似地,与时间相关的注意值404、406和408分别对地板316、显示器306和虚拟化身308的注意进行建模。
当用户注视沙发314时,注意力值402正在增加。随着注意力值的增加,增加的速度可能会减慢。稍后,用户看着不同的对象,注意值402则开始减少(泄漏),而不同实体的注意值开始增加。当用户再次注视沙发314时,注意力值402再次增加。
在这个示例中,在时间t.sub.1接收语音命令。在时间t.sub.1及其前后接收到的眼动注视采样与地板316相关,因此注意值404增加。然而,沙发314的注意值402保持相对大于其他注意值404、406、408,因为为注意值402结合衰减率而积分的采样数保持注意值402高于其他值。
这表明地板注视采样324可能是由于眼跳运动引起。因此,通过使用空间注意模型,用户输入与沙发314正确关联。
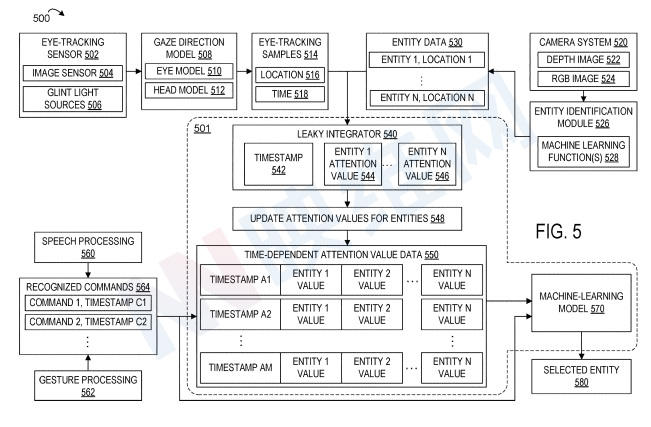
图5示出了利用示例空间意图模型501将用户输入与注视位置500关联的系统。处理管道可以在任何合适的计算系统上实现。
系统500包括注视管道和一个或多个用户输入管道。在注视管道中,眼动追踪传感器502向注视方向模型508输出眼动追踪信号。眼动追踪传感器502包括图像传感器504和闪烁光源506。基于眼动追踪信号,注视方向模型508确定用户的注视方向。
注视方向模型508可以使用眼睛模型510和/或头部模型512来确定注视方向。利用所述信息,计算系统可以检测眼动追踪采样的注视方向是否与任何识别实体相交。在注视线确实与实体相交的地方,相应的眼动追踪采样514输入到泄漏积分器540中。
系统500同时包括与用户可查看的场景中的实体相关的实体信息。在所描绘的示例中,摄像头系统520经由深度摄像头522和/或RGB摄像头524对场景成像。实体识别模块526处理包括深度图像和/或RGB图像的图像数据,实体识别模块526识别场景中的一个或多个实体。实体识别模块526可包括一个或多个经过训练的机器学习功能528。
可以使用任何合适的机器学习函数,包括一个或多个神经网络(卷积神经网络)。实体识别模块526输出场景中实体和相应实体位置的实体列表530。另外,可以从远程计算系统获得先前在使用环境中识别的实体列表。
基于眼动追踪采样514和实体列表530中实体位置的比较,泄漏积分器540将眼动追踪采样分配给相应实体,并更新每个实体的时间相关注意值。更新后的每个实体的注意值存储为与最近的眼动追踪采样相对应的时间戳。
在确定更新的注意值之后,更新的注意值和相应的时间戳存储在时间相关注意值数据550的数据结构中。存储的时间相关注意值数据550随后可用于基于用户输入的时间戳将用户输入与时间相关注意值匹配。
作为示例,系统500的用户输入可包括用户语音输入和/或用户手势输入。因此,语音处理系统560可以从麦克风接收的语音输入输出识别的命令,而手势处理系统562可以输出识别的手势命令。如上所述,可识别的命令564可包括位置相关命令。
选择时间相关注意值后,选择与已识别命令相对应的实体。在一个示例中,可以选择具有最高注意值的实体作为要与命令关联的实体。
在其他示例中,识别的命令、注意值数据550和实体数据530输入到机器学习模型570中,机器学习模型570输出每个实体作为预期实体的可能性。机器学习模型570可以使用例如包括多个数据采样的标记训练数据进行训练。每个采样包括命令、注意值数据、实体数据和对应于正确实体选择的标记实体。
名为“Location-based entity selection using gaze tracking”的微软专利申请最初在2020年11月提交,并在日前由美国专利商标局公布。