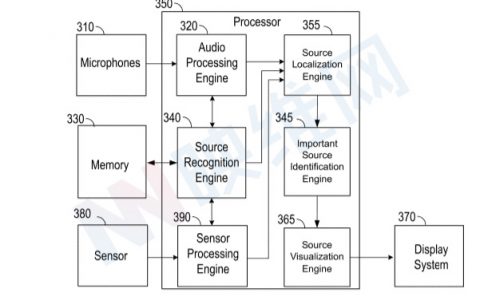
微软专利探索基于AR眼镜+智能手机的虚拟化身生成渲染
生成逼真的Avatar
(映维网Nweon 2022年05月28日)微软于2021年发布了Mesh for Teams,正式开启MR全息办公,从而提升远程协作体验。其中,用户可以通过Avatar的方式参加视像会议。在名为“Multiple device sensor input based avatar”的发明中,这家公司介绍了一种根据多传感器设备来渲染生成Avatar的方式。
简单来说,可以用两台设备来分别捕获用户的不同部位,然后整合出完整的Avatar。例如,AR眼镜可以捕获用户身体的双手,而智能手机可以捕获用户的面部表情。
来自与用户相关联,且在物理空间中具有不同视角的多个设备的传感器输入可共同提供关于用户的信息。由于所述信息具有足够的特异性水平,所以可用于生成逼真的Avatar。
另外,由于Avatar是通过将用户面部的三维表示纹理映射到三维身体模拟来生成,所以它可以准确地捕捉细微差别的人类行为,例如用户的面部表情和手势。这种在Avatar视频流中生成,从而能够并入虚拟现实或混合现实体验中,例如多个用户之间的虚拟现实或混合现实电话会议。
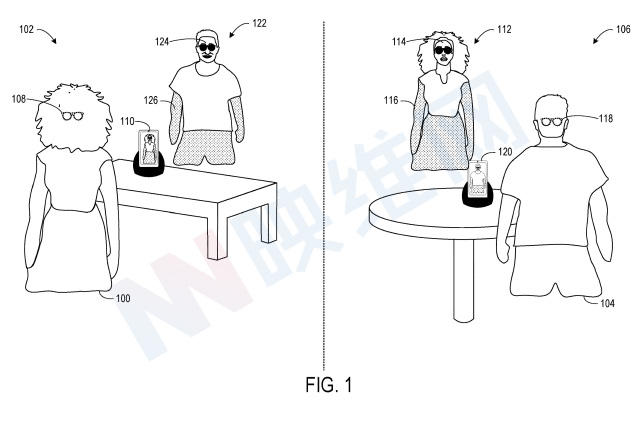
图1示出了一场远程混合现实会议场景,包括位于第一物理空间102中的第一用户100,以及位于远离第一物理空间102的第二物理空间106中的第二用户104。第一用户100穿戴第一头戴式显示设备108,头戴式显示设备108包括前置图像传感器,前置图像传感器从第一用户100的角度对第一物理场景102进行成像。
利用前置图像传感器,第一头戴式显示设备108可以对进入头显摄像头视场的第一用户100的各种身体部位进行成像,例如手部。物理空间102同时存在与第一头戴式显示设备108分离的第一成像设备110,第一生成设备110从与第一头戴式显示设备108不同的视角成像第一用户100的面部。
来自第一头戴式显示设备108和第一成像设备110的图像数据发送到远程计算系统(图1中未示出),并由后者生成包括第一用户100的第一Avatar112的音频/视频流。第一Avatar112是通过将第一用户面部114至少一部分的三维表示纹理映射到跟随第一用户100的实际物理运动的三维身体模拟116而形成。
远程计算系统将包括第一Avatar112的音频/视频流发送到第二用户佩戴的第二头戴式显示设备118。第二头戴式显示设备118呈现音频/视频流,使得第一Avatar112以全息方式投影到第二物理空间106中。
远程计算系统可以向第一成像设备110发送包括第一Avatar112的音频/视频流,并且第一成像设备向第一用户100显示第一Avatar。这样,向第一用户100提供第一Avatar112的虚拟反馈。在其他示例中,第一成像设备110可以通过视觉呈现由第一成像设备110捕获的第一用户100的图像来充当取景器。
从第二用户104的角度来看,混合现实电话会议以相同或类似的方式发生。图像数据由第二头戴式显示设备118的朝外图像传感器生成。另外,第二成像设备120对第二用户的面部进行成像。来自第二头戴式显示设备118和第二成像设备120的图像数据发送到远程计算系统。
远程计算系统向第一用户100佩戴的第一头戴式显示设备108发送包括第二Avatar122的音频/视频流。第二Avatar122是通过将第二用户面部124的三维表示纹理映射到跟随实际运动的三维身体模拟126而形成。第二头戴式显示设备118呈现音频/视频流,使得第二Avatar122以全息方式投影到第一物理空间102中。
需要注意的时,所示场景是非限制性。任何适当数量的两个或更多设备可以捕获关于用户的图像数据。
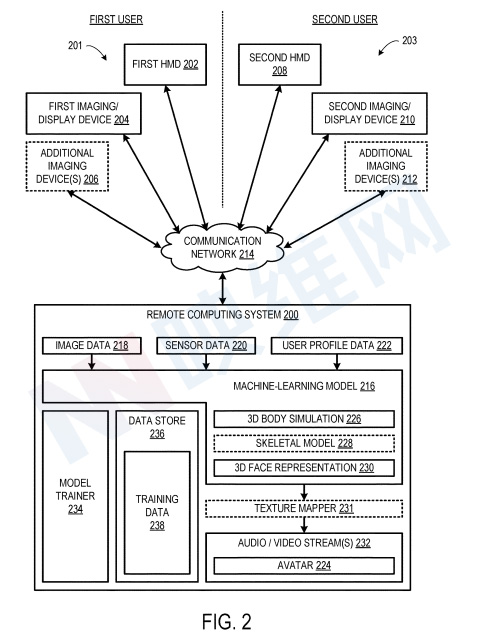
图2示出了配置为促进远程用户之间的虚拟现实或混合现实视频电话会议的示例计算系统200。在所示的示例中,第一用户与包括第一头戴式显示设备202、第一成像/显示设备204,以及可选的一个或多个附加成像设备206的第一多个设备201相关联。
与第一用户相关联的第一多个设备201可以定位在第一用户所在的第一物理空间内,使得第一多个设备201可以从第一物理空间中的不同视角成像或以其他方式感知第一用户。
如上所述,第一头戴式显示设备202包括至少一个前置摄像头,并配置为对第一物理空间成像以生成图像数据。另外,前置摄像头可以成像进入摄像头视场的第一用户身体部分,例如第一用户的手部。
摄像头可以采用任何合适的形式,例如单色摄像头或彩色(例如RGB)摄像头。第一头戴式显示设备202同时可以包括一个或多个附加摄像头,包括但不限于深度摄像头和红外摄像头。
第一成像/显示设备204可以采用与第一头戴式显示设备202分离的任何适当形式的设备,并且包括可用于从与第一头戴式显示设备202不同的视角对第一用户成像的摄像头。第一成像/显示设备可以是智能手机和平板电脑等设备。
远程计算系统200配置为经由诸如因特网的通信网络214与第一多个设备201和第二多个设备203通信。远程计算系统200包括机器学习模型216,机器学习模型216配置为有助于在多个用户(例如第一用户和第二用户)之间进行虚拟现实或混合现实体验。
在一个示例中,远程计算系统200配置为经由通信网络214从第一多个设备201接收图像数据218。图像数据218可以包括原始图像帧。
在其他示例中,图像数据218可以包括处理后的图像数据,例如来自深度摄像头的深度数据。
在一个示例中,在处理后的图像数据发送到远程计算系统200之前,可以在摄像头或其他设备本地执行其他图像处理操作。例如,可以在本地执行特征识别、骨架建模、空间映射和/或其他图像处理操作,并且可以将这种处理后的图像数据发送到远程计算系统200。
可选地,在一些实现中,远程计算系统200可以配置为经由通信网络214从第一多个设备201接收传感器数据220。在一个示例中,所述传感器数据220可包括非图像数据,例如音频数据、运动数据、空间映射数据和/或其他类型的传感器数据。
另外,远程计算系统200可以配置为经由通信网络214接收对应于第一用户的用户简档数据222。用户简档数据222可以包括用于在虚拟现实或混合现实电话会议中代表第一用户的个人偏好信息。例如,用户简档数据222可以指定Avatar224的物理特征,包括但不限于肤色、头发颜色、眼睛颜色、体型、衣服和其他物理特征。
如上所述,机器学习模型216配置为基于从第一多个设备201接收的图像数据生成第一用户身体的三维身体模拟226。
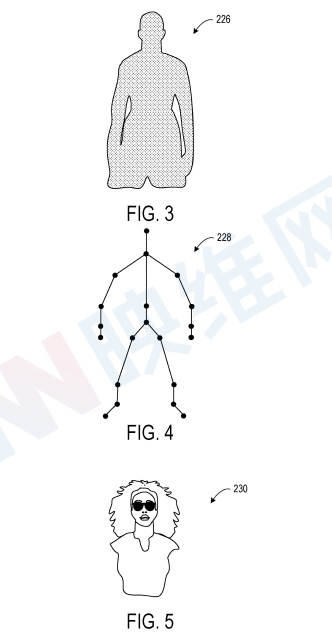
图3示出了三维身体模拟226的示例表示。第一用户身体的三维身体模拟226遵循第一用户身体的实际物理运动。在一个示例中,机器学习模型216配置为基于至少从第一头戴式显示设备202接收的图像传感器数据生成三维身体模拟226。根据所述数据,可以推断出第一用户身体的三维姿势。
在另一示例中,机器学习模型216配置为基于从第一头戴式显示设备202接收的图像传感器数据和从第一成像/显示设备204接收的图像数据来生成三维身体模拟226。例如,机器学习模型216可以配置为在空间上注册来自两个设备(和可选的附加成像设备)的图像数据,以确定第一用户身体在第一物理空间中的三维位置。
当机器学习模型216从第一成像/显示设备204的深度摄像头接收深度数据时,机器学习模型216可选地可以配置为基于深度数据生成第一用户身体的骨架模型228。
图4示出了骨骼模型228的示例表示。另外,机器学习模型216可以配置为基于骨骼模型228生成三维身体模拟226。
机器学习模型216进一步配置为基于从第一成像/显示设备204接收的图像数据生成第一用户面部的三维表示230。三维表示230包括三维点云。图5示出了三维点云230的示例表示。三维点云提供第一用户面部的体积表示。
可选地,Avatar224可以增强或修改以包括任何合适的虚拟内容。例如,可以基于用户简档数据222任选地由第一用户的个人偏好设置虚拟内容,比如说帽子等配饰。
相关专利:Microsoft Patent | Multiple device sensor input based avatar
名为“Multiple device sensor input based avatar”的微软专利申请最初在2020年11月提交,并在日前由美国专利商标局公布。