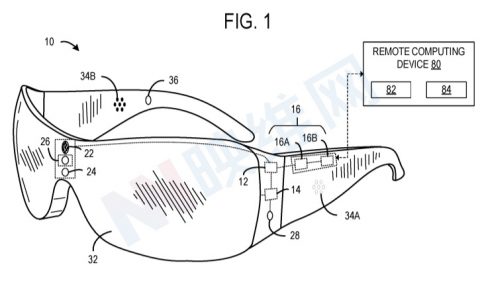
微软专利提出可扩展动态合成声音技术,通过多层优化实现高效HRTF效果
通过多层优化实现高效的HRTF近似
(映维网Nweon 2023年09月27日)头相关传递函数HRTF如何得到适当的实现,诸如HoloLens这样的系统可以产生来自特定位置的逼真虚拟音效。然而,HRTF的计算量十分高昂,所以现有系统会尝试近似HRTF。
不过,尽管现有的系统可以尝试近似HRTF,但微软认为有必要改进声音的合成方式,并降低合成所需的计算水平。这家公司指出,随着越来越多的设备用于合成声音,对如何合成声音的需求会越来越大。但特定设备的计算能力有限,甚至电量有限。
所以在名为“Efficient hrtf approximation via multi-layer optimization”的专利申请中,微软提出了一种可扩展的动态合成声音技术,通过多层优化实现高效的HRTF近似。
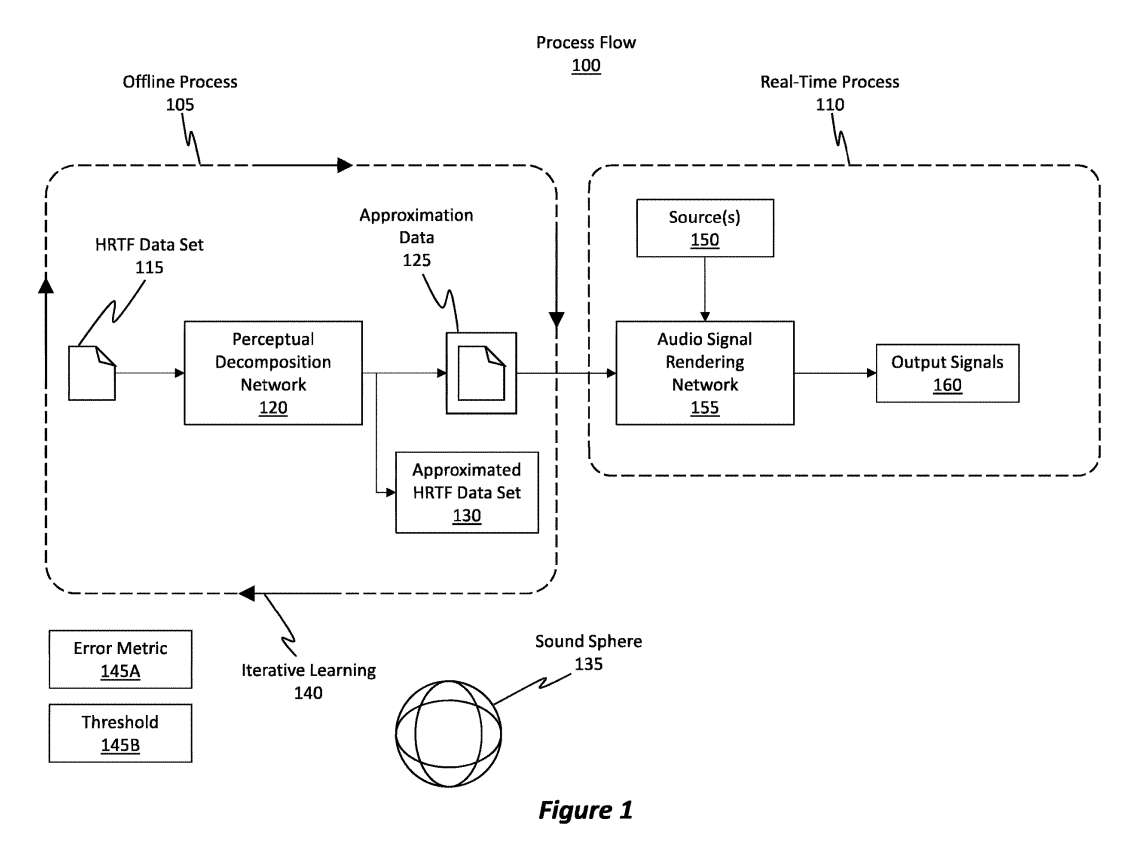
图1说明了相关的流程100。所述进程100一般包括两个进程,如离线进程105和实时进程110。
离线过程105是指感知分解过程,其中网络使用HRTF数据集来导出近似数据。通过离线方式,意味着可以在呈现音频信号之前的任何时间执行离线进程。
网络对近似数据进行迭代微调,直到网络的输出与输入HRTF数据集充分匹配。两个数据集之间的匹配可以设置为在特定频率上发生,或者可以设置为在一个频率范围内发生。
换句话说,实施例尝试最小化特定损失函数。当误差度量收敛到某个值时,迭代停止,这意味着再调优所述值将导致网络给出更差的近似值。
一旦逼近数据得到充分调优,它就可以在实时过程中使用流程110。通过“充分调优”,意味着两个数据集之间的误差度量低于阈值水平。
即在实时过程110中,使用近似数据来驱动网络,以使网络能够呈现输入音频信号,而不必使用实际的HRTF滤波器来呈现信号。因此,离线过程105是在要呈现音频信号之前及时执行的准备步骤。另一方面,实时处理110实时执行,并且使用先前为呈现音频信号而生成的近似数据。
离线过程105包括访问HRTF数据集115并提供该HRTF数据集115作为输入到感知分解网络120。网络对HRTF数据集115进行操作,生成一组近似数据125。所述近似数据125包括用于控制进入所述网络的一组混合通道的输入的某些混合通道增益。近似数据125进一步包括用于控制网络的有限输入响应FIR滤波器的系数。
当将HRTF数据集115作为输入馈送到感知分解网络120时,网络不仅生成近似数据125,同时生成输出近似HRTF数据集130。感知分解网络120配置为迭代地修改近似数据125,直到输出近似HRTF数据集130充分匹配HRTF数据集115。
有了这样的理解,就有必要对HRTF进行额外的解释。考虑一个声球。声球135代表了一个可以位于人类用户头部周围的球体。HRTF旨在描绘或渲染声音,就好像声音实际上是从声球上的特定来源发出的一样。根据发明描述的原理,实施例能够为声球135的每个点、源、位置生成一组特定的近似数据。
值得注意的是,正如代表迭代学习140的箭头所示,离线过程105是一个迭代过程,因为它执行任意次数,直到达到期望的结果。
在这种情况下,期望的结果是输出近似HRTF数据集130和HRTF数据集115之间的误差度量145A小于错误阈值145B。
换句话说,迭代学习140过程可以执行1、2、3、4、5或任意次数,直到达到所需的误差度量145A。阈值145B可以针对两个数据集相匹配的特定频率触发或评估,或者,阈值145B可以针对两个数据集相匹配的频率范围触发或评估。
在一个实施例中,在优化之前,可能无法事先知道误差度量的值,从而无法确定数据集何时已经充分收敛,例如何时尽可能地优化网络。
因此,可能不使用阈值来控制迭代学习过程的终止。如果网络配置为相对较小,则产生的误差可能会相对较高,因为网络可能无法准确地近似整个HRTF数据集。
针对这种情况,在不使用阈值的情况下,当观察到误差不再改善时,当学习过程试图继续调整它时,网络停止,从而表明已经达到收敛。
在一个实施例中,可以迭代地修改这些不同的近似数据,直到得到的误差度量145A满足阈值145B要求。
在对HRTF数据集115进行分解并生成近似数据125之后,近似数据125就可以在实时过程110中使用。感知分解网络120专门配置为执行迭代学习过程,而音频信号呈现网络155专门配置为执行实时呈现。在每个网络中提供各种配置优化,以确保每个网络执行其预期的职责。
音频信号呈现网络155然后处理输入并产生输出信号160,包括左耳输出信号和右耳输出信号。左耳输出信号可以在左扬声器中播放,右耳输出信号可以在右扬声器中播放。
值得注意的是,音频信号呈现网络155使用近似数据125来生成输出信号,而输出信号有效地模拟使用HRTF滤波器产生的输出信号。
然而,近似数据125相对于HRTF数据集115要稀疏得多,因此,与使用实际HRTF滤波器来呈现相同音频信号的场景相比,音频信号呈现网络155使用近似数据125来呈现音频信号消耗相对较少的计算量。
图2A-2E说明了可以用作图1中的感知分解网络120的示例网络的补充信息以及各种视图。回想一下,感知分解网络120可以用作音频信号渲染网络155。因此,2A-2E既可以作为感知分解网络120,又可以作为音频信号呈现网络155。
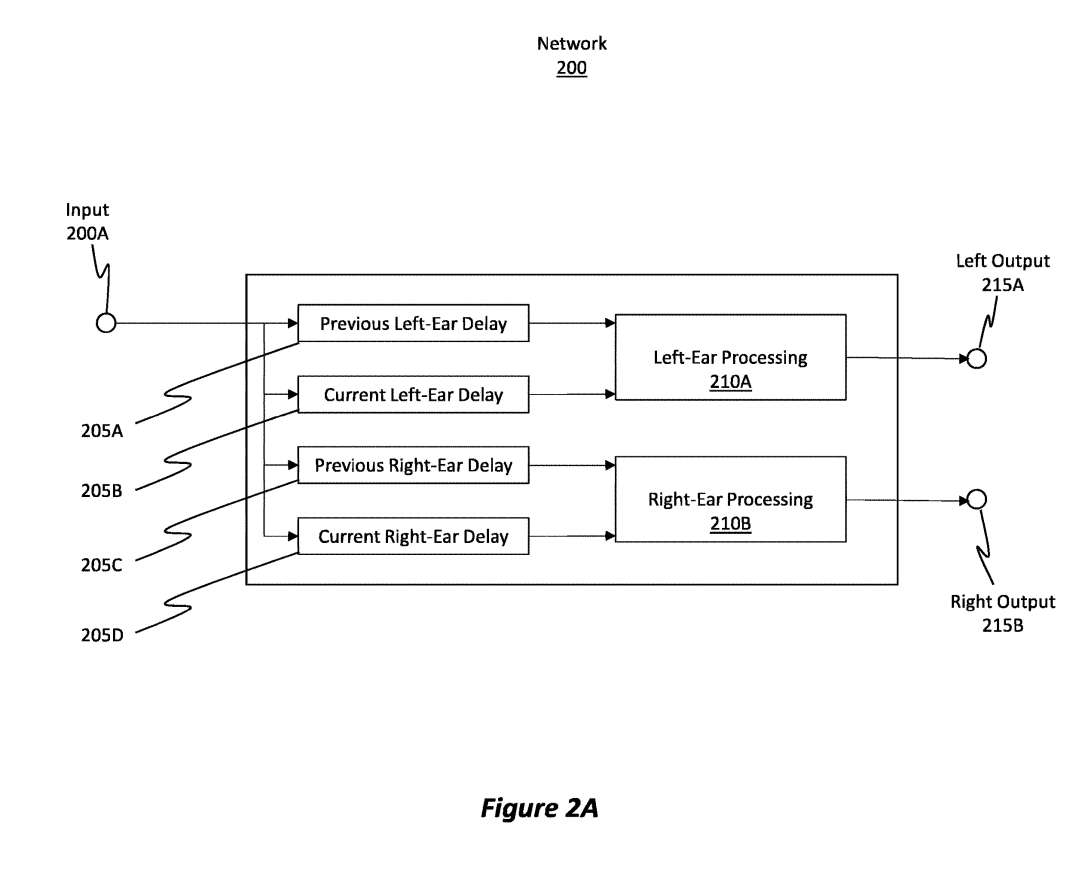
图2A示出示例性网络200,其代表图1中的音频信号呈现网络155。
网络200包含一组延迟,如前一个左耳延迟205A,当前左耳延迟205B,前一个右耳延迟205C,当前右耳延迟205D。声音传播的路径长度对于不同的耳朵而言是不同的,所以提供延迟来适应相关路径长度。
所述网络200同时包括左耳处理210A节点和右耳处理210B节点。网络200的输出为左输出215A,右输出215B。当输入HRTF数据集作为输入200A提供时,则网络200的输出将是一个模拟输入HRTF数据集的输出近似HRTF数据集。
有益的是,网络200设计成最小化存在于输出近似HRTF数据集和输入HRTF数据集之间的误差度量。网络200通过迭代学习过程最小化这个误差度量,而在迭代学习过程中,近似数据随着时间的推移迭代修改,以减少实际输入HRTF数据集和输出近似HRTF数据集之间的误差量。
随后,当将实际音频信号作为输入馈送到网络200时,则左输出215A和右输出215B将是音频信号,可以在一对扬声器中播放以产生声音。但在分解过程中,使用网络200生成一个输出近似HRTF数据集,数据集反复处理或由网络生成,直到输出近似HRTF数据集与输入HRTF数据集充分匹配。
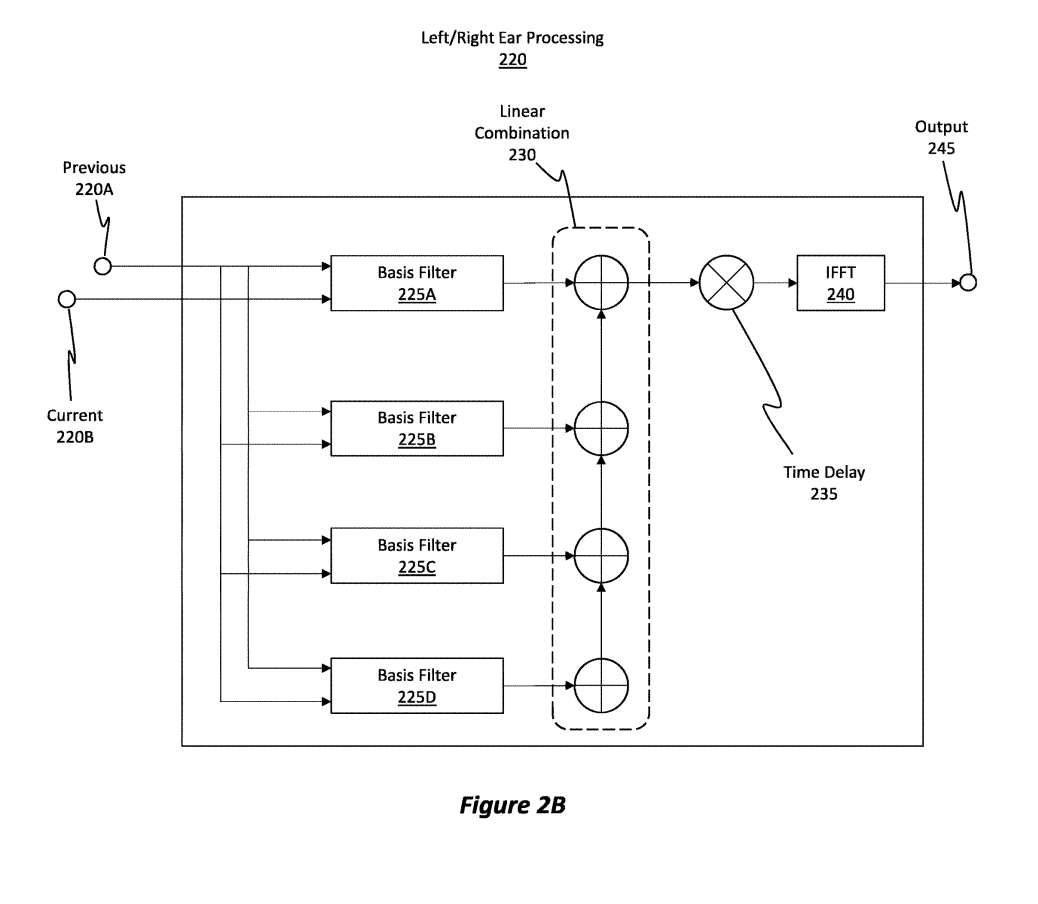
图2B示出了左耳/右耳处理220节点,其代表图2A的左耳处理210A或右耳处理210B中的任何一种。左/右耳处理220节点的输入包括之前的220A输入和当前的220B输入。前一个220A输入代表前一个左耳延迟205A的输出之一,或者是前一个右耳延迟205C。
类似地,当前220B输入表示当前左耳延迟205B的输出之一,或者当前右耳延迟205D的输出。
220A输入和220B输入馈送至一组基滤波器225A、225B、225C和225D。在这个示例实现中,有四个基本过滤器。每个基本滤波器都包含一个快速傅立叶变换FFT,它将音频信号从时域转换为频域。左/右耳处理220节点然后线性组合来自基滤波器的结果,如线性组合230所示。
换句话说,基滤波器的输出可以在频域线性组合,因为基滤波器通过各自的fft将信号转换到频域。然后,信号受到时间延迟235。
可选地,这个时间延迟可以被删除并合并到基滤波器阶段,以产生类似的输出。然后使用逆FFT (IFFT)将信号转换回时域,如IFFT 240所示,从而产生输出245。输出245代表图2A中的左输出215A或右输出215B中的任何一个。
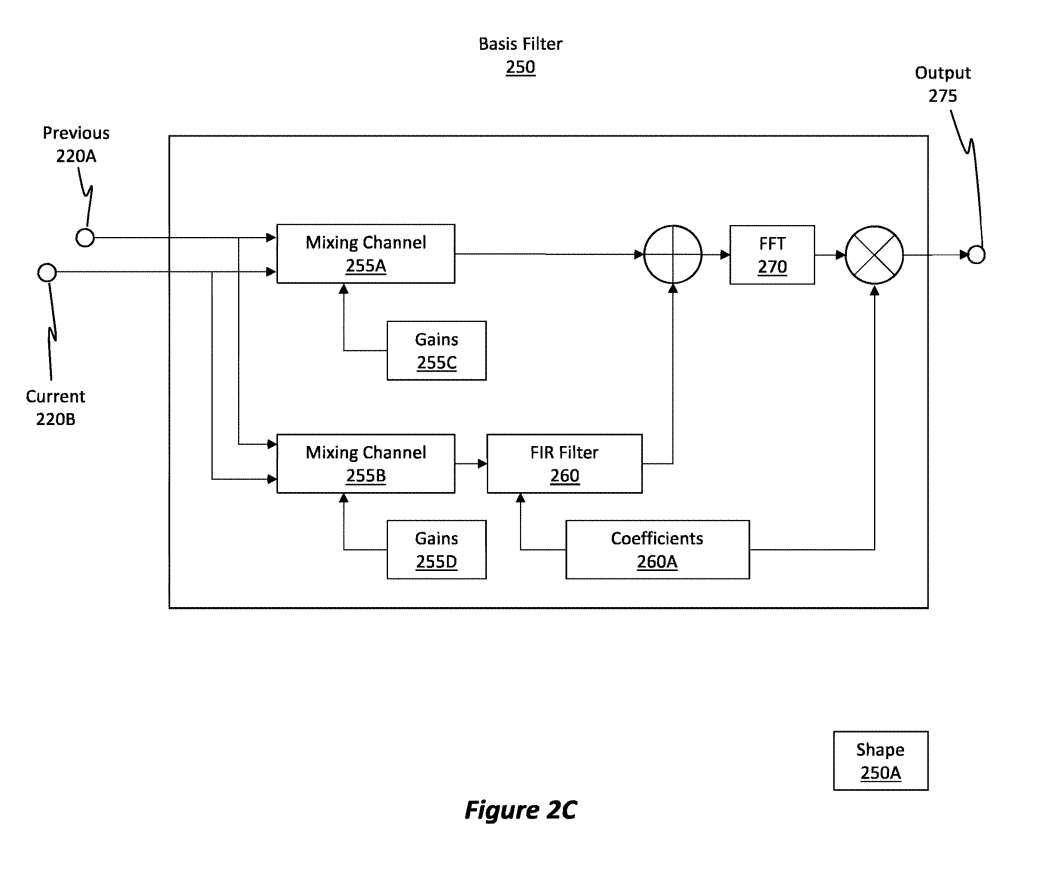
图2C以更细粒度的方式示出基滤波器。具体地说,图2C显示了基滤波器250,它代表图2B中的基滤波器225A、225B、225C或225D中的任何一个。
之前的220A输入和当前的220B输入馈送到基滤波器250。基滤波器250包括混合通道255A和混合通道255B。
混合通道255B的输出馈送至有限输入响应FIR滤波器260,滤波器由一组系数260A控制,而系数260A包含在近似数据中。然后,混合通道255A的输出和FIR滤波器260的输出加在一起,然后通过FFT 270。FFT 270的输出可以延时,然后产生输出275。
在这个图中,FFT 270之后有一个乘法阶段。在FFT 270之后,网络可以通过在分解步骤中导出的基滤波器缩放频率幅度。这个卷积可以由系数260A驱动。输出275将与其他基滤波器的输出线性组合。值得注意的是,每个基滤波器具有相应的形状250A。
理想滤波器的工作方式是在其通频带中具有单位增益(0 dB)。理想滤波器的阻带增益为零(−无穷大dB)。在通带和阻带之间,滤波器将没有不确定性,并将有效地从0 dB渐近过渡到−无穷大dB。但对于实际的过滤器,情况并非如此。因此,形状250A表示基滤波器250的实际滤波特性,包括其通带增益和其阻带增益。
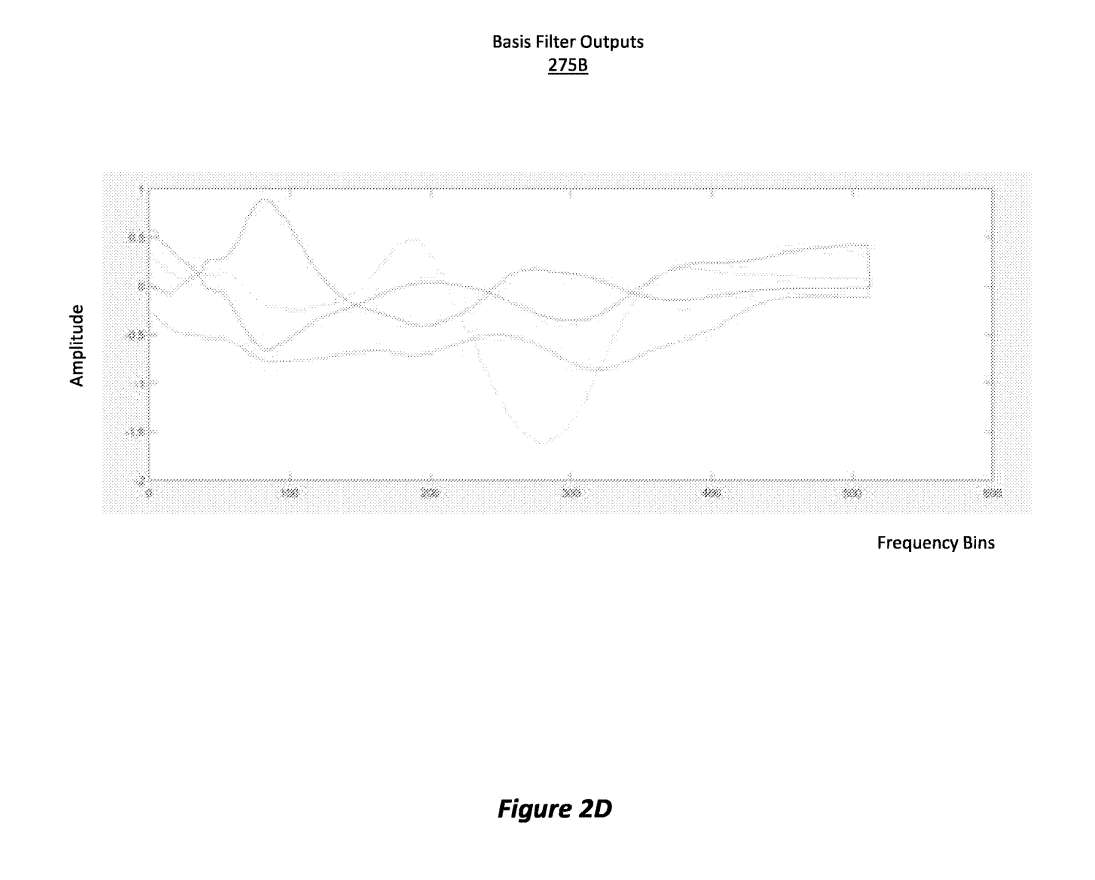
图2D显示了来自四个不同基滤波器225A、225B、225C和225D的基滤波器输出275B。图表中的每条线表示一个基过滤器。根据发明,每个HRTF滤波器可以表示为图2D中四种波形的特定线性组合,以及在基滤波器之前的混合通道滤波器的线性组合。
所述实施例能够确定要使用来自每个基滤波器的多少能量,以便线性组合所述信号以产生结果输出。换句话说,基滤波器的输出可以在频域中线性组合。所有的值都是每个HRTF过滤器,并且实施例将为滤波器中的每个过滤器获得一组不同的权重,然后提供近似于网络试图迭代重新创建的原始HRTF过滤器的近似。
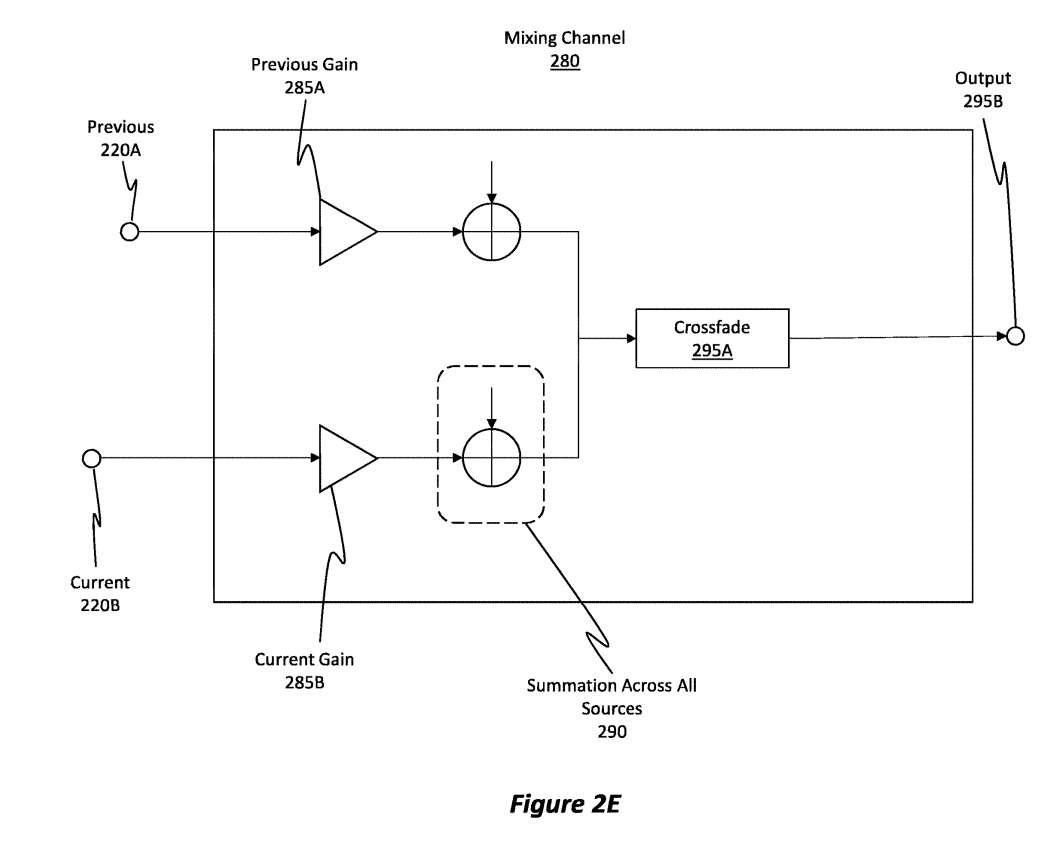
图2E以更细粒度的方式说明了图2C的混合通道。具体而言,图2E示出了混合通道280,它代表图2C中的混合通道255A或255B中的任何一种。
混合通道280使用一组增益,如前面的增益285A和当前增益285B所示,并对输入音频信号执行逐元乘法。前面的增益285A和电流增益285B包含在近似数据中,并包含在图2C的增益255C和255D中。混合通道280还跨所有源290操作执行求和,其中所述源包括输入信号。
源是一个具有音频信号和与其相关联的位置的对象。在执行渲染过程时,实际上可以同时渲染多个不同的源。使用所描述的技术,每个源可以与其自己相应的混合通道增益集相关联,其可以独立于其他源的增益。
在获得增益后,实施例将来自该源的音频的缩放副本发送到特定增益所对应的混合通道中。在这种情况下,混合通道280能够获取附加源的缩放音频内容,并将其与已经在混合通道中的内容相加。
混合通道由所有源共享,因此当对一个源进行空间化时,在混合通道中可能已经存在缩放的信号,这就是实施例求和而不是简单替换它的原因。在渲染每个请求的帧之前,混音通道的内容被清除,亦即设置为全零。然后,混合通道280对信号进行交叉淡出,如交叉淡出295A所示,从而产生输出295B。
回到图2C,混合通道255B的输出馈送到FIR滤波器260。所述实施例能够生成一组用于控制FIR滤波器260的系数260A。FIR滤波器260可以是一个四阶FIR滤波器,这样它可以有5个系数。FIR滤波器260实际上是基滤波器250的FFT 270的预滤波阶段。
在网络中包含FIR滤波器260使网络在转向提供给FFT 270的信号时具有额外的自由度。实际上,包含FIR滤波器260的操作就好像提供了一个额外的FFT,但没有额外的FFT成本。在计算成本方面,FIR滤波器260的成本大大低于FFT 270。另外,FIR滤波器260允许细粒度调谐,以便使信号更好地适应基滤波器250的形状250A。
因此,网络200可用于分解HRTF数据集以生成近似数据。这个分解过程是一个迭代过程,目的是为了确定一组最优的近似数据,其中包括一组混合通道增益,一组FIR系数,甚至基滤波器的形状。
随着时间的推移,近似数据被迭代地学习和修改,以产生接近实际输入HRTF数据集的输出。实施例通过识别输出近似HRTF数据集与输入HRTF数据集匹配或对齐的紧密程度(来确定近似数据是否充分微调。
为了确定如何迭代地修改近似数据,实施例计算输出近似HRTF数据集和输入HRTF数据集之间的误差度量。迭代过程执行,直到误差度量小于一个阈值水平。
换句话说,迭代学习包括迭代地修改近似数据,直到输出近似HRTF数据集与输入HRTF数据集之间的误差度量小于误差阈值。与输入HRTF数据集相比,近似数据更稀疏。
然后,当网络在实际音频信号上运行时,可以使用近似数据来驱动网络。

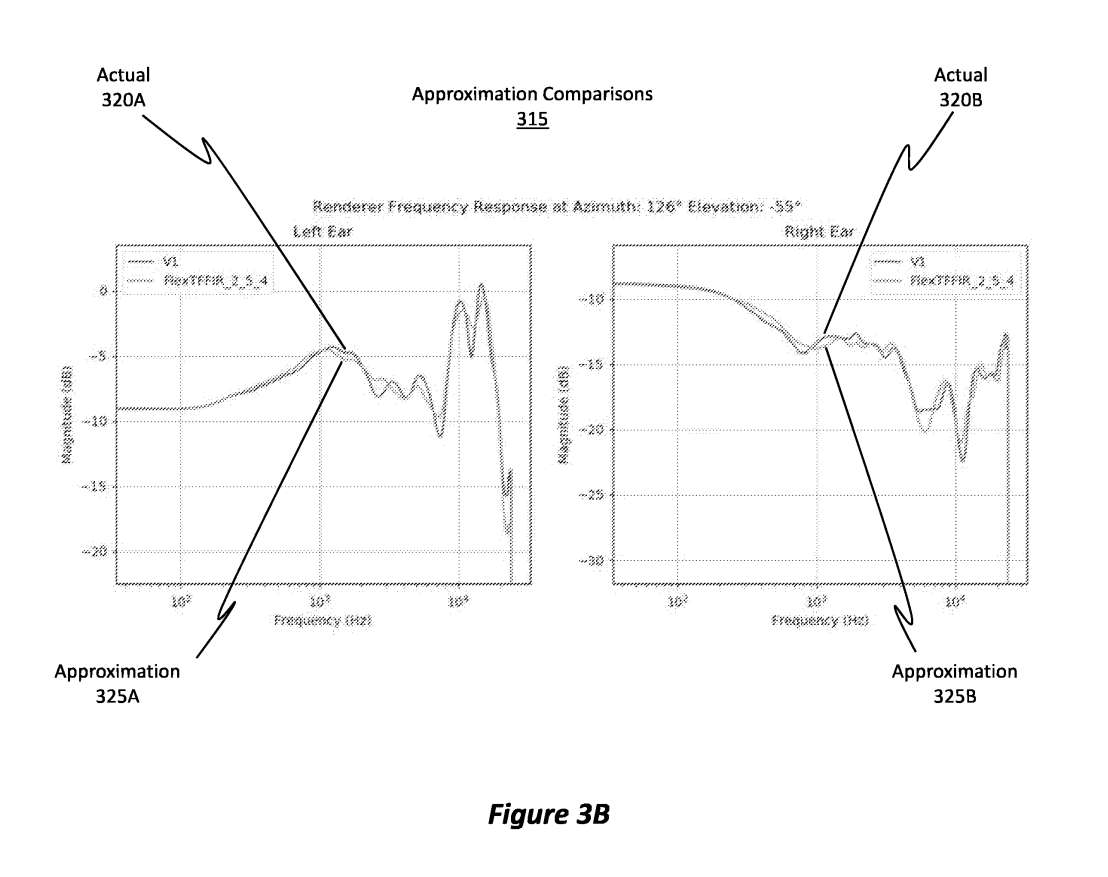
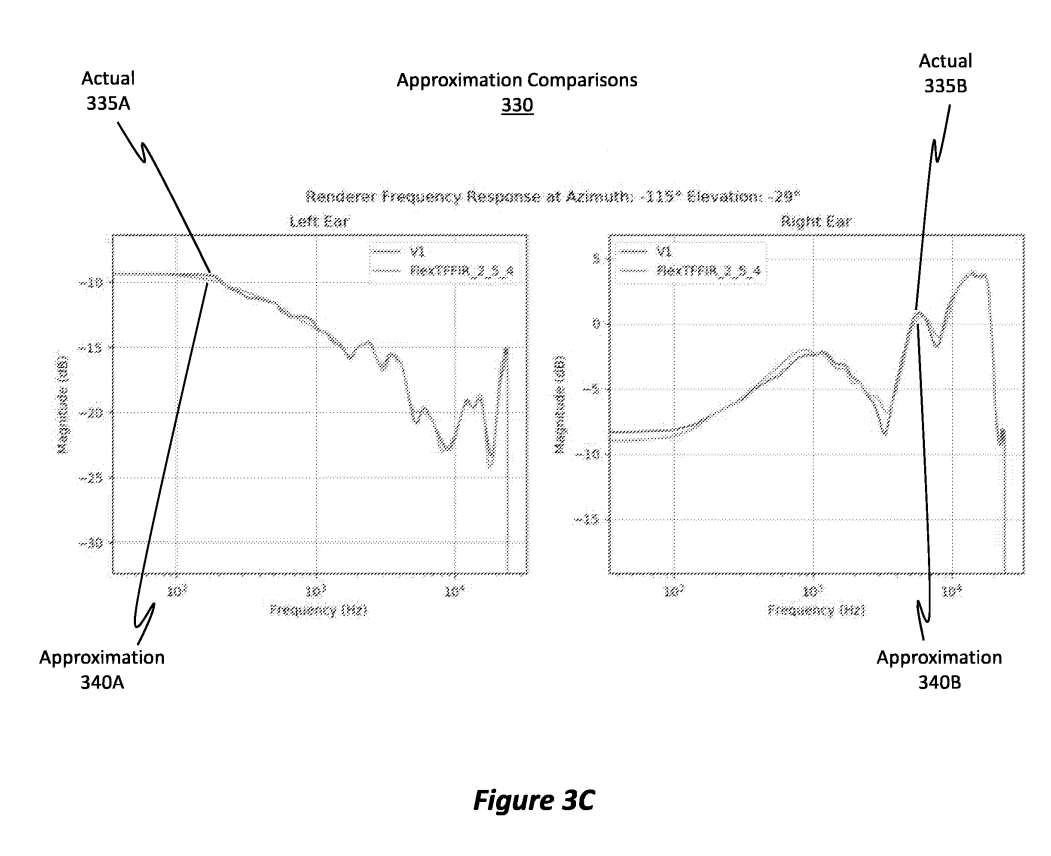

图3A到3D显示了说明了近似数据如何与原始HRTF非常接近。
现在将注意力转向图4,图4演示了用于近似HRTF滤波器的示例方法400。
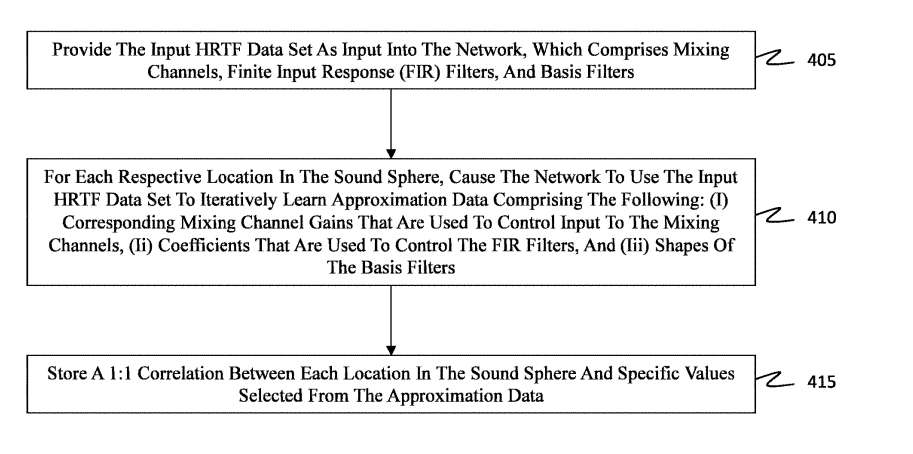
方法400包括感知分解过程,其中输入HRTF数据集馈送到网络中,并用于生成近似数据。值得注意的是,网络配置为迭代地微调近似数据,直到输出与输入HRTF数据集充分匹配。方法400可以使用图2A的网络200来实现。方法400侧重于感知分解过程。
具体地,方法400包括提供输入HRTF数据集作为网络输入的行为(act 405),网络包括包括混合通道、有限输入响应FIR滤波器和FFT的基本滤波器。输入HRTF数据集包括一组对应于声球中每个位置的HRTF过滤器。
对于声球中的每个相应位置,act 410包括使网络使用输入HRTF数据集迭代学习近似数据。所述近似数据包括以下内容:
-
用于控制混合通道输入的相应混合通道增益
-
用于控制FIR滤波器的系数,
-
基滤波器的形状。
值得注意的是,混合通道增益的特定组合以及FIR系数和基滤波器输出的线性组合使网络生成与输入HRTF数据集对应的输出。换句话说,输出是一个输出近似HRTF数据集。迭代学习试图通过迭代修改近似数据来最小化输出近似HRTF数据集与输入HRTF数据集之间的误差度量。
然后,act 415包括在声球中的每个位置与从近似数据中选择的特定值之间存储1:1的相关性。通过随后在声球中选择一个特定位置,从近似数据中选择相应的一组值,其中对应的一组值包括特定的混合通道增益、系数和基滤波器形状。
当选择一个特定的位置时,特定于所述位置的值包括混合通道增益。FIR系数和基滤波器可以保持不变,无论位置几何。
在这种意义上,实施例直接基于HRTF数据派生出一组近似数据。当渲染音频信号时,所述近似数据可用于驱动各种component。
换句话说,经过分解过程,网络可以用来渲染音频信号。这个音频信号将对应于声源或声球上的一个位置。实施例可以确定所述位置,然后选择对应于该特定位置的特定近似数据集。接下来,这个选择的近似数据可以用于配置或驱动网络中的component,以便正确渲染音频信号,从而允许音频信号如同起源于声球上的位置一样进行播放。
从这个意义上说,近似数据包括多个混音通道增益、多个系数和多个基滤波器形状(例如,声球上每个位置的特定值)。此外,使用近似数据(例如,当输入是HRTF数据集时)生成近似HRTF,并且迭代修改近似数据,直到近似HRTF与实际HRTF之间的误差度量小于错误阈值。与实际的HRTF过滤器相比,近似数据要稀疏得多。
任选地,方法400可进一步包括呈现被馈送到网络中的输入音频信号。在一些实施例中,呈现包括识别声球中的特定位置,并基于声球中的特定位置,从近似数据中选择一组特定的混合通道增益,从近似数据中选择一组特定的系数,以及从近似数据中选择一组特定的基滤波器形状。
所述呈现过程可进一步包括基于所选的特定混合通道增益集、基于所选的特定系数和基于所选的特定基滤波器形状集来配置所述网络。在配置网络之后,所述方法可包括将所述输入音频信号作为输入馈送到所述网络的行为。
然后可以使网络产生一个左输出信号和一个右输出信号。然后可以通过一对扬声器播放左输出信号和右输出信号。
现在将注意力转向图5,图5演示的示例方法500使用在感知分解过程中生成的近似数据来呈现音频信号,换句话说,在执行图4的方法400之后执行方法500。
另外,可以使用图2A的网络200执行方法500。而网络200使用HRTF数据集作为输入200A来分解HRTF数据集,当执行方法500时,网络200使用与声球上的特定源或位置相关联的音频信号作为输入200A。
最初,方法500包括访问用于驱动网络组件的近似数据的行为(act 505)。近似数据是通过一个迭代学习过程生成的,在这个过程中,输入的HRTF数据集作为输入输入到网络中,网络使用近似数据来生成输出的近似HRTF数据集。
网络对近似数据进行迭代微调,直到输出近似HRTF数据集和输入HRTF数据集之间的误差度量低于误差阈值。近似数据包括:
-
用于控制网络混合通道的混合通道增益
-
用于控制网络有限输入响应FIR滤波器的系数
-
网络基滤波器的形状。
act 510包括执行渲染过程,以渲染用于在一对扬声器上播放的输入音频信号。值得注意的是,输入的音频信号作为输入馈送到网络中。绘制过程如图6所示。

具体地,图6显示的渲染方法600包括确定输入音频信号如同声音起源于声球上的特定位置一样进行播放的行为(act 605)。
act 610包括使用特定位置从近似数据中选择一组混合通道增益。例如,如前所述,声球上的每个声源或位置都与一组近似数据相关联。每个源的近似数据作为执行方法400的结果生成。所述实施例识别与所述音频信号相关的源或位置,然后选择为所述特定源生成的特定近似数据集。
act 615包括将所述混合通道增益集应用于所述输入音频信号以产生所述混合通道输出集,所述混合通道输出集将通过所述网络中包含的每个基滤波器进一步馈送。在一个实施例中,在应用增益集之后,所述方法进一步包括跨所有源执行求和,并将求和添加到混合通道集。源包括输入音频信号以及任何其他音频信号。
act 620包括将系数应用于网络中的每个FIR滤波器,其中FIR滤波器作为基滤波器中包含的FFT的预滤波器,以便在FFT操作之前对输入音频信号进行预滤波。
act 625包括在FIR滤波器对输入音频信号进行操作后,将基滤波器的FFT应用于输入音频信号。值得注意的是,FFT将输入音频信号从时域转换到频域。
act 630包括线性组合由第一组基滤波器产生的输出以产生第一输出信号,以及线性组合由第二组基滤波器产生的输出以产生第二输出信号。
尽管没有在图6中示出,但方法600可以进一步包括在执行步骤630之后对信号应用IFFT的行为,以便将信号转换回时域。换句话说,在线性组合由第一组和/或第二组基滤波器生成的输出后,实施例可以进一步执行IFFT以生成第一和第二输出信号。
回到图5,方法500进一步包括使用第一输出信号和第二输出信号在一对扬声器上播放声音的行为(行为515)。如前所述,绘制过程可由图2A中的网络200执行。
因此,实施例通过使用一种新的双耳空间化技术,有效地解决了多源场景中昂贵的空间化问题,并同时降低了每个源渲染成本。
通常,在分解过程中,实施例使用一组随位置、源或位置变化的频率无关的混合矩阵处理输入。所述实施例同时用一组沿频率变化的混合通道滤波器处理输入。所述实施例使用包含在一组由所有源位置共享的基滤波器中的fft进一步处理所述输入。所述实施例对基滤波器的输出求和以产生所需的HRTF输出。
在网络中,混合通道滤波器和基滤波器中的FFT协同工作以重建HRTF数据集,混合通道滤波器在优化过程中具有更高的自由度。因此,这减少了精确逼近所需的总体基滤波器数量。
在示例实现中,混合通道过滤器不会在不同位置变化,并且输出是HRTF的单个通道。然而,发明描述的技术可以扩展以处理位置相关的混合通道滤波器以及HRTF数据集的多通道表示。另外,对于试图派生的任何值,实施例可以选择性地选择约束或预定义其中的特定值。
相关专利:Microsoft Patent | Efficient hrtf approximation via multi-layer optimization
名为“Efficient hrtf approximation via multi-layer optimization”的微软专利申请最初在 2022年3月提交,并在日前由美国专利商标局公布。