微软研究团队分享:增加面部landmark数量实现更精确3D面部重建
通过增加面部landmark的数量来实现更精确的3D面部重建
(映维网Nweon 2022年10月26日)计算机视觉是计算机科学中最引人注目的领域之一。它的发展速度非常迅速,并且有望显著影响人们的生活和工作方式。近年来,机器学习和计算机视觉的融合交叉进展正在加速,并为众多领域带来了重大进展,包括医疗保健、机器人、汽车工业和增强现实。
为了帮助人们实现更多目标,微软研究人员一直在与所述领域的学者和专家合作,共同开展一系列的计算机视觉项目。一个例子是PeopleLens。这款以HoloLens作为灵感的头戴式设备可以通过空间化音频识别周围的人员,从而帮助失明人士或视力低下人士在社交场合进行互动。另一个例子是Swin Transformer。这个计算机视觉架构在目标检测中实现了高精度,并提供了将计算机视觉和自然语言处理(NLP)架构统一的机遇。
在日前举行的2022年欧洲计算机视觉大会(ECCV),微软介绍了团队在计算机领域的最新成果。下面将重点与混合现实相关的两份研究论文。第一篇是通过增加面部landmark的数量来实现更精确的3D面部重建,在降低所需计算能力的同时获得最先进的结果。另一篇主要涉及一个利用AR设备对真实世界进行视觉定位和映射的数据集。以下是第一篇“3D face reconstruction with dense landmarks”的分享。
1. 方法介绍
Landmark通常在人脸分析中起着关键作用,但关于身份或表情的众多方面无法仅用稀疏Landmark来进行表示。为了更精确地重建人脸,行业通常将Landmark与深度图像等附加信号或微分渲染等技术相结合。
通常,从业者用来训练ML模型的公共数据集包含68个面部Landmark的注释。然而,人脸并不能仅用68个Landmark来精确地表示,需要额外的方法来补充Landmark检测,而这增加了训练工作的复杂性,并增加了所需的计算能力。
所以,研究人员好奇的一个问题是:为了进一步简化流程和优化资源利用,是否可以单纯依靠(密集)Landmark来实现逼真的人脸重建呢?
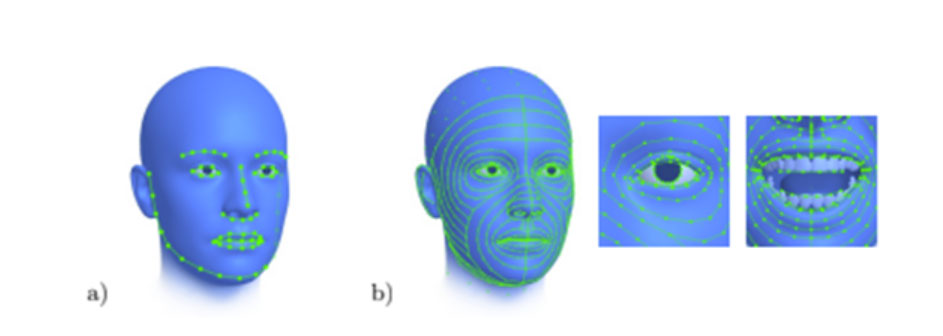
为了实现准确的3D人脸重建,微软提出了自己的解决方案:单纯依靠密集Landmark来实现逼真人脸重建。其中,团队表示相关方法可以准确预测十倍于平常的Landmark,覆盖整个头部,包括眼睛和牙齿。
正如前面所述,微软表示他们的方法可以准确预测十倍于平常的Landmark,覆盖整个头部,包括眼睛和牙齿,如图1所示。简单来说,这是通过使用合成训练数据来实现,从而保证了完美的Landmark标注。
概括而言,团队的方法主要包括两步:
- 首先预测概率密集Landmark L,每个Landmark都具有位置µ和确定性σ。
- 然后,研究人员将3D人脸模型拟合到L,通过优化模型参数Φ最小化能量E
值得注意的是,尽管人类可能会始终使用68个Landmark标记图像,但手动使用密集Landmark标注图像是不可能的。为了保证完美的Landmark标注,微软使用人脸合成系统渲染了100000张合成训练图像。团队指出,没有合成数据提供的完美注释,密集地标预测是不可能的。
通过将可变形模型拟合到密集Landmark,研究人员实现了自然场景下最先进的单目3D人脸重建结果。通过在单目和多视图场景中展示准确和富有表现力的面部表现捕捉,团队表明密集的Landmark是跨帧整合面部形状信息的理想信号。实验比较证明了所述方法的高效性:可以预测密集Landmark,并在单个CPU线程以超过150FPS的速度拟合3D人脸模型。

2. 使用合成数据提高隐私、公平和效率
在计算机视觉领域,尤其是人脸重建领域,在训练ML模型时对匿名性的担忧可以理解,因为训练数据通常来自真人。微软提出的方法显著减少了隐私问题,因为它只使用合成数据来训练ML模型,不使用真人的图像。换句话说,当建立合成数据管道时,微软非常注重保护用户的隐私,并且获得了数百名被试的同意。团队指出:“如果我们要使用真实数据,这是必要的环节。”
使用合成数据有助于保护数据主体的隐私,以及摄影师和内容创作者的权利。微软强调,他们都是以符合道德和负责任的方式来构建技术。另外,由于数据集中不包括用户的私人信息,如果ML模型受到攻击,只有合成数据会受到损害。
合成数据同时为解决包容性和公平性问题提供了机会。这主要是因为数据的分布完全受控,ML从业者可以通过在数据集中包含不同的样本来管理表示的公平性,并且所有需要这样做的数据都会被完美地标记
使用合成数据训练ML模型同时存在其他优点。例如,模型需要大量的数据,而这给从业者获取数据带来了诸多困难,例如找到所需人数的后勤、在实验室安排时间,以及设置多个摄像头以捕捉人脸的不同角度。合成数据大大减少了所述方面的担忧。
另外,由于数据不需要来自真人,所以提高3D人脸重建质量的迭代速度非常高,从而创建了一个稳健的工作流程。当使用合成数据时,没有必要对每个Landmark的图像应用QA过程,这是另一个节省成本和时间的优势。另一点是这增加了Landmark数据的精度、速度和成本效益。因为要求某人在一组图像中一致地标记703个Landmark几乎不可能实现。

微软总结道:“人脸分析是众多ML系统的基础,例如人脸识别和控制Avatar。使用一种既能提供精度和效率,又能解决隐私和公平问题的方法打破了现有技术的界限。使用密集Landmark和合成数据实现3D人脸重建的能力有可能真正改变ML。”