微软AR专利探索多源摄像头捕获图像生成场景叠加图
选择特定图像以便生成叠加图像
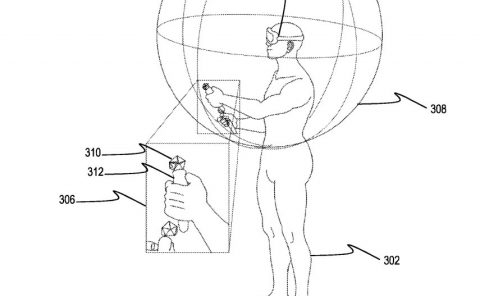
(映维网Nweon 2023年04月19日)如果大家有关注微软的专利探索,这家公司曾多次提出一种集成式摄像头/系统摄像头+分离式摄像头/外部摄像头的系统理念。其中,集成式摄像头/系统摄像头是指物理集成到头显的摄像;分离式摄像头/外部摄像头则是指与头显分离的摄像头。
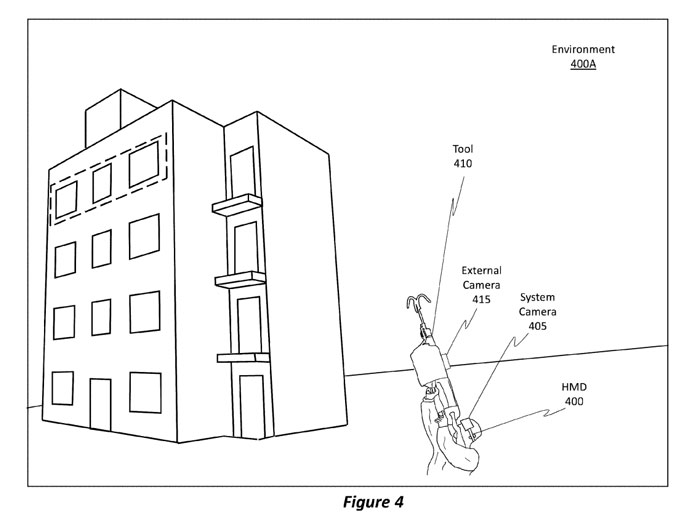
例如在一个场景中,可以将分离式摄像头捆绑或以其他方式放置在用户的胸部。在另一个场景中,分离式摄像头可以不放置在用户的身体上,而是由用户握持的工具上,如上面的图4所示。
在名为“Frame selection for image matching in rapid target acquisition”的专利申请中,微软介绍了评估来自多个不同源的多个图像,以及用于选择特定图像以便生成叠加图像的方法。
概括来说,系统获得第一组系统摄像头图像(如基于第一FPS速率)和第二组外部摄像头图像(如基于第二FPS速率)。访问一组规则以管理用于选择特定系统摄像头图像和特定外部摄像头图像的选择过程。
所选择的图像指定用于生成叠加图像。其中,选择过程是使用所访问的一组规则来执行的。实施例然后通过叠加和对准从所选图像获得的内容来生成叠加图像。然后,可以在头戴式设备中显示叠加图像。
如前所述,微软构思的系统包括两个摄像头,而两个摄像头的至少一部分视场彼此重叠,所以有必要进行校准。因此,可以识别对应的内容,然后可以基于类似的对应内容生成合并、融合或叠加的图像。通过生成叠加图像,实施例能够向用户提供增强的图像内容。
为了合并或对准图像,实施例分析纹理图像(例如执行计算机视觉特征检测),试图找到任意数量的特征点。然后,确定图像特征是否存在于图像中的任何特定点或像素。通常,角落、可区分的边缘或脊用作特征点,因为边缘或角落的固有或鲜明对比可视化。
任何类型的特征检测器都可以编程来识别特征点。特征检测器可以是机器学习算法。
实施例检测任意数量的特征点,然后尝试识别在系统摄像头图像中检测到的特征点与在外部摄像头图像中识别出的特征点之间的相关性或对应性。
实施例然后将特征或图像对应关系拟合到运动模型,以便将一个图像叠加到另一个图像上以形成增强的叠加图像。可以使用任何类型的运动模型。其中,运动模型是一种变换矩阵,它使模型、已知场景或对象能够投影到不同的模型、场景或对象上。
运动模型可以简单地是旋转运动模型。在旋转模型的情况下,实施例能够将一个图像移动任意数量的像素(例如可能向左移动5个像素,向上移动10个像素),以便将一幅图像叠加到另一幅图像上。
一旦识别了图像对应关系,实施例就可以识别那些特征点或对应关系的像素坐标。一旦识别出坐标,则实施例可以使用上述旋转运动模型方法将外部摄像头的图像叠加到头显摄像头的图像上。
一种用于对准图像的技术包括使用IMU数据来预测系统摄像头和外部摄像头的姿态。一旦估计或确定了这两个姿势,实施例就使用这些姿势来将图像的一个或多个部分彼此对准。
一旦对准,则一个图像的一个或多个部分(这些部分是对准的部分)叠加到另一图像的相应部分上,以便生成增强的叠加图像。在这方面,IMU可以用于确定相应摄像头的姿势,然后这些姿势可以用于执行对准过程。
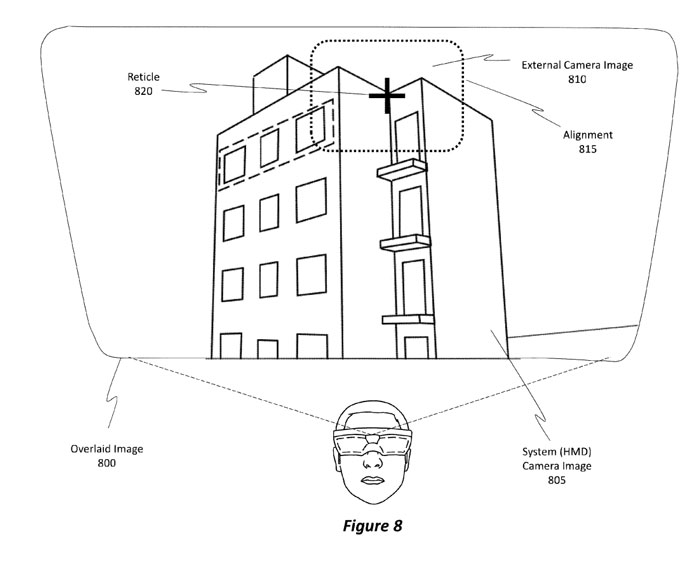
图8示出了包括系统摄像头图像805和外部摄像头图像810来对准这些图像。可选地,附加的图像伪影可以包括在叠加图像800中,例如可能用于帮助用户瞄准工具的标线820。通过对准图像内容,工具的用户可以确定工具的目标位置,而不必向下看工具的瞄准器。相反,用户可以通过简单地查看头显中显示的内容来辨别工具的目标位置。
提供增强的叠加图像800允许快速的目标获取,如图9中的目标获取900所示。所以,可以以快速的方式获取目标,因为用户不再需要花费时间通过工具的瞄准器进行观察。
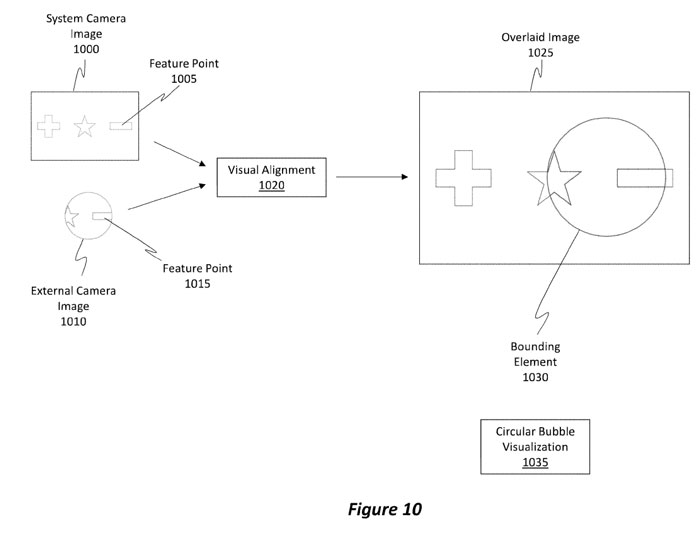
图10示出了具有特征点1005的系统摄像头图像1000和具有与特征点1005相对应的特征点1015的外部摄像头图像1010。
施例能够使用特征点1005和1015在系统摄像头图像1000和外部摄像头图像1010之间执行视觉对准1020,以便产生叠加图像1025。
叠加图像1025包括从系统摄像头图像1000提取或获得的部分和从外部摄像头图像1010提取或获得。注意,叠加图像1025包括包围像素的边界元素1030,所述像素是从外部摄像头图像1010和/或从系统摄像头图像1000获得。可选地,边界元素1030可以是圆形气泡可视化1035的形式。然而,其他形状可以用于边界元素1030。
当视觉对准过程不可用时,实施例可以执行基于IMU的对准过程。
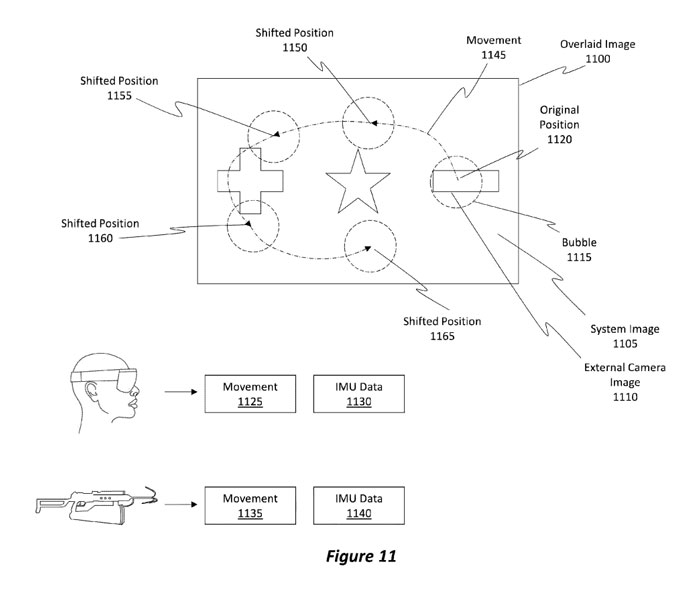
图11示出了叠加图像1100,其代表了来自图10的叠加图像1025。实施例可以在第一时间点执行视觉对准技术的情况。此后(至少在一段时间内),实施例执行基于IMU的技术,如图11所示。
图11示出了如何从系统图像1105和外部摄像头图像1110形成叠加图像1100。叠加图像1100包括围绕来自外部摄像头图像1110的内容的气泡1115。
注意,气泡1115具有原始位置1120。基于头显的移动(例如移动1125),以及基于外部摄像头的移动(如移动1135),实施例能够将气泡移动或重新定位到新的位置,以反映头显和外部摄像头的运动。
例如在给定的时间段内,头显和外部摄像头之间存在相对移动1145,导致气泡1115重新定位到新的位置,例如在一个时间点的移位位置1150、在另一个时间点将移位位置1155、在另个时间点将移位位置1160和在另一时间点将移动位置1165。偏移的位置是使用IMU数据1130和1140来确定。
在另一个时间点,执行视觉对准的选项现在可用。因此,实施例能够使用混合方法,其中执行视觉对准过程和基于IMU的过程,以便生成叠加图像并基于检测到的移动来重新定位边界元素。
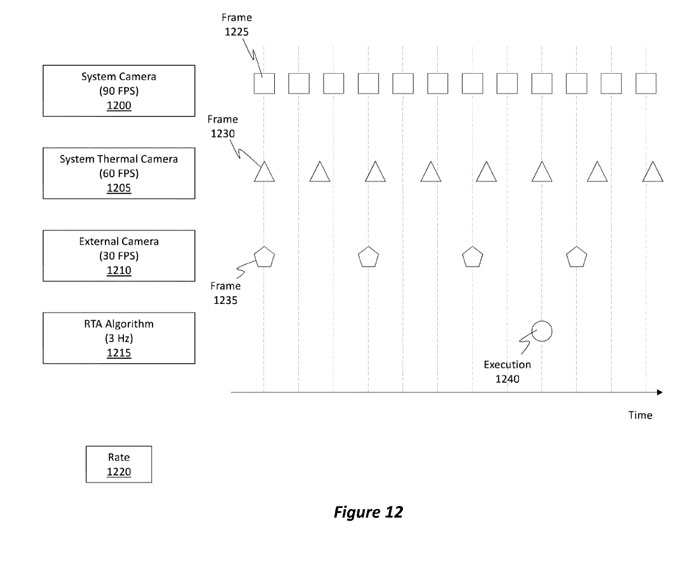
现在将注意力转向图12,图12示出了系统摄像头1200、系统热摄像头1205和外部摄像头1210。
如图所示,系统摄像头1200可以配置为以大约90FPS的FPS速率操作。系统热摄像头1205以大约60FPS的FPS速率操作。
快速目标获取“RTA”算法1215是使用视觉对准过程来生成叠加图像的算法。RTA算法可以结合基于IMU的过程来执行。通常,视觉对准过程(即RTA算法的性能)以大约3Hz的速率执行。基于IMU的过程可以更频繁地执行,但其准确性较低。仅出于示例目的,RTA算法1215被图示为以3Hz的速率发生。
图12示出了由系统照摄像头1200生成的帧1225。这里,帧是以大约90FPS的速率生成。
帧1230(即三角形)代表由系统热摄像头1205生成的帧。其他三角形表示由系统热像仪1205生成的其他图像或帧。
帧1235(即五边形)代表由外部摄像头1210生成的帧。其他五边形表示由外部摄像头1210生成的其他图像或帧。
圆圈(标记为执行1240)表示RTA算法1215触发并执行视觉对准过程以便生成叠加图像时的时间实例。另外,施例可以或多或少频繁地执行基于IMU的操作。换句话说,关于视觉对准过程,RTA算法1215通常以大约3Hz的速率执行。
注意,在执行1240发生之前,系统摄像头1200、系统热摄像头1205和外部摄像头1210都分别生成了多个图像。传统上,RTA算法1215将依赖于最近生成的图像,以便尝试执行图像对准。
专利描述的实施例能够考虑自上次执行视觉对准过程以来已经生成的所有或至少多个图像,而不是依赖于或仅使用最近生成的图像来执行视觉对准。实施例可以审查和分析这些图像,以确定哪些图像将为成功的视觉对准过程提供最高的可能性。
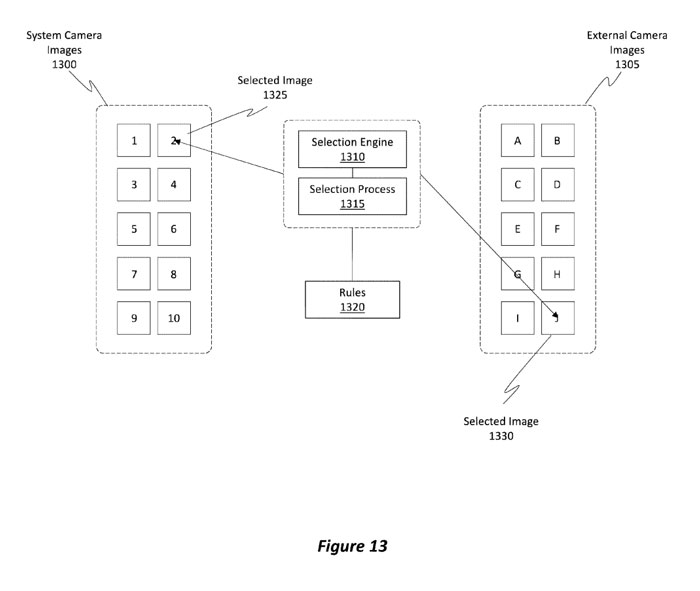
图13示出了标记为1、2、3、4、5、6、7、8、9和10的一组系统摄像头图像1300。图13同时示出了标记为a、B、C、D、E、F、G、H、I和J的一组外部摄像头图像1305。
图像“1”是最早生成的图像并且具有最旧的时间戳,而图像“10”是最近生成的图像,并且具有最新的时间戳。类似地,图像“A”是最早生成的图像并且具有最早的时间戳,而图像“J”是最近生成的图像,并且具有最近的时间戳。
系统摄像头图像1300可以可选地是图12中所示的正方形图像或三角形图像。类似地,外部摄像头图像1305可以可选地是图12中所示的五边形图像。
智能选择引擎1310可以基于一组规则1320执行选择过程1315,以从系统摄像头图像1300中智能地选择特定图像(例如所选图像1325),并从外部摄像头图像1305中智能地选出特定图像。在被选择之后,图像然后被用于生成前面提到的叠加图像。
注意,尽管所选图像1330是最近生成的图像,但所选图像1325不是最新生成的图像。换句话说,可能存在两个所选图像的时间戳彼此不相同并且可能完全不同的情况。不管时间戳的任何差异如何,实施例选择这些图像是因为,选择引擎1310确定这些图像将提供成功的视觉对准过程,。
可选地,所选图像的时间戳之间可能存在差异,所以这些图像的姿势或内容可能彼此不同。为了解决这种差异,实施例可以对图像中的一个或两个执行一个或多个变换,以使它们彼此适当对准。
例如,可以执行修改模型、执行重投影等技术。在执行了图像的充分重投影之后,可以将来自外部摄像头图像的内容对准并叠加到系统摄像头图像上。实现重投影的一种方法是通过使用由追踪系统或从IMU获得的姿态数据。然后,重投影校正记录图像的时间戳和期望的时间戳(例之间的姿态差。
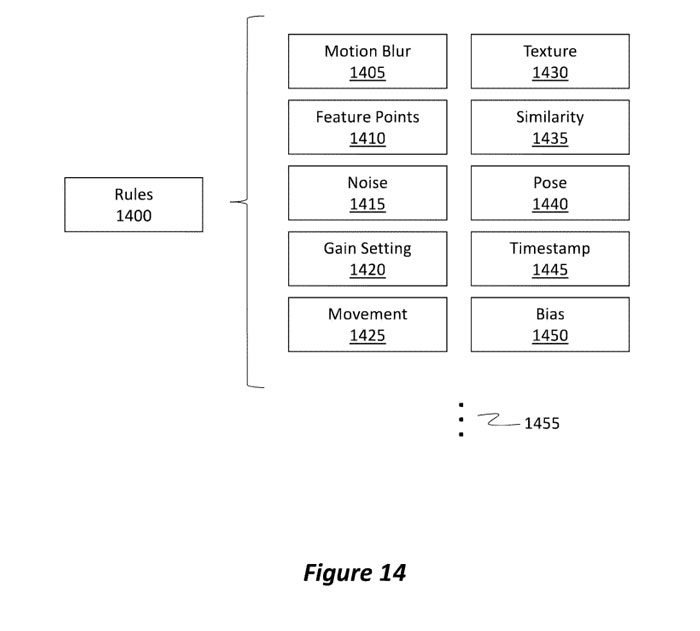
图14更全面地说明了图13中提到的规则1320。图14的规则1400代表规则1320。
规则1400管理将从多个候选图像中选择哪个图像以供RTA算法使用。如图14所示,当执行选择过程时,规则1400可以考虑各种不同的参数或因素。
所考虑的一个示例因素是在每个图像中检测到的运动模糊1405的量。举例来说,实施例能够分析图像中的每一个,以确定存在于每一个相应图像中的运动模糊1405的量。具有超过预定阈值的运动模糊量的图像可以被丢弃,因此不被考虑。
另一个因素涉及在每个相应图像中可观察到的可检测特征点1410的数量。例如,实施例能够分析每个图像以尝试识别特征点。可以丢弃不具有阈值数量的特征点的图像。特征点1410可以指通常存在于各种图像之间的特征点的数量。
尽管在任何两个单独的图像中都可以检测到大量的特征点,但如果通常存在于这两个图像之间的共同特征点的数量不满足阈值,则可以丢弃这些图像,因为不能确定这两个图像之间足够数量的相关性。
实施例同时可以考虑图像中存在的噪点1415的量。噪点1415的量越高,图像的质量就越低。因此,可以丢弃噪点超过特定阈值的图像。
移动量1425同时可以由规则1400来考虑。移动1425可以通过将一个图像的内容与另一个图像进行比较来确定。如果比较显示像素内容相似,那么移动相对较小。另一方面,如果像素内容非常不同,则已经发生了大量的移动。如果检测到阈值移动量1425,则可以丢弃图像。
图像中的纹理1430的数量同样可以是考虑的因素。纹理1430通常指图像中颜色的空间排列,或者更确切地说是指图像中强度的空间排列。如果在图像中没有检测到阈值量的纹理1430,则可以丢弃该图像。
相似性1435是指一个图像与另一个图像的相似程度。例如,相似性1435与移动1425因子相似,因为可以比较和对比两个或多个不同帧之间的像素。相似性确定可以基于整体图像,也可以基于图像的特定部分。
至少两个图像之间的高相似度导致更高的精度结果,而至少两个图片之间的低相似度导致更低的精度结果。在一些情况下,相似性1435也可以或可替换地指希望选择与先前选择的图像不同的图像的场景。也就是说,相似性1435可以指示任何当前选择的图像将不同于任何先前选择的图像。
可以将图像的姿势1440与另一图像的姿势进行比较,以确定这些图像彼此之间的关系有多密切。姿态中的较高相关性导致较高的精度结果,而姿态中的较低相关性导致较低的精度结果。
另外,可以执行时间戳(例如时间戳1445)之间的比较。由于图像是随时间生成的,因此可能发生了移动或新内容进入了场景(即摄像头指向的区域)。
长时间使用通常会导致图像变旧。与旧图像相比,新图像(即在执行视觉对齐过程时生成的图像)更受欢迎。因此,实施例可以引入或合并偏置1450。
通过上述方式,微软描述的方法可以在快速目标获取中进行图像对准。
相关专利:Microsoft Patent | Frame selection for image matching in rapid target acquisition
名为“Frame selection for image matching in rapid target acquisition”的微软专利申请最初在2021年10月提交,并在日前由美国专利商标局公布。