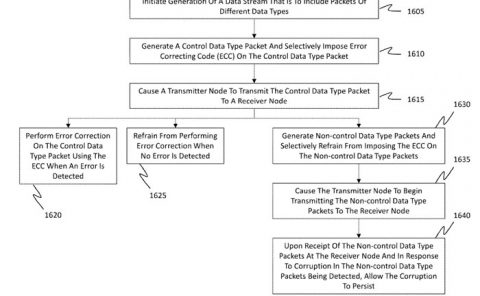
微软AR/VR专利分享基于优化的深度学习参数模型拟合
基于优化的深度学习参数模型拟合
(映维网Nweon 2023年11月10日)Landmark检测这项计算机视觉任务可以在图像和视频中检测和定位人脸或身体的关键点。
但由于可变性以及姿势和遮挡等诸多因素,Landmark检测具有挑战性。计算机视觉中的大多数任务都需要拟合参数模型来输入数据。但由于头戴式设备的位置和输入信号的稀疏性造成的自遮挡,从头戴式设备估计3D人体姿势是一个难题。
能够以准确、鲁棒和快速的方式将人体、手或脸的参数模型拟合到稀疏的输入信号中,这有望显著提高AR和VR场景的沉浸感。在处理所述问题的系统中,通常第一步是直接从输入数据回归参数模型的参数。但转换和优化系统以高性能运行需要定制实现,这需要工程师和领域专家投入大量时间。
对噪点输入数据拟合参数模型是计算机视觉中一个常见的任务。经典的优化方法可以通过迭代最小化手工制作的能量函数来紧密地拟合参数模型,但容易出现局部最小值。
所以,从业者通常将这两种方法结合起来,从它们的互补优势中受益,从回归器初始化模型参数,然后使用经典优化器最小化能量。
为了获得使用深度学习和经典数值优化的最佳回归,名为“Optimization-based parametric model fitting via deep learning”的微软专利申请利用了基于机器学习的连续优化领域。
在一个实施例中,网络不是使用一阶或二阶模型筛选器更新模型参数,而是学习迭代更新参数,以使目标损失最小化,并具有快速推理的额外优势。端到端网络训练消除了手工制作先验的需要,因为模型直接从数据中学习先验。
基于Levenberg-Marquardt和Adam算法的特性,发明使用迭代机器学习求解器扩展了现有方法,算法能够保留以前迭代的信息,独立控制每个变量的学习率,以及(结合梯度下降和能够快速降低拟合能量的网络的更新,从而实现鲁棒性和收敛速度。
学习优化是一个将优化视为学习问题的领域。目标是创建能够学习利用问题结构的模型,从而产生更快、更有效的能量最小化方法。
这样,就不需要手动设计参数更新规则和先验,因为系统可以直接从数据中学习它们。所述方法已用于图像去噪和立体声深度估计、刚性运动估计、视图合成、运动和场景几何的联合估计、模拟数据的非线性层析反演问题、人脸对齐和单个图像的对象重建。
当前的人脸参数化模型和用户辅助方法将模型拟合到图像中,可以训练神经网络回归器,从而可以从图像和视频中可靠地预测SMPL参数。随着表情模型的引入,目前的回归方法可以预测三维的身体、面部和手。
然而,所有回归场景都存在一个常见问题,即预测和输入数据的不一致。因此,它们通常作为基于优化方法的初始点,然后对估计参数进行细化,直到满足某些收敛准则。
这种组合产生了有效、稳健的系统,能够在具有挑战性的条件下实时工作。调整优化器以实时运行是一项非常重要的操作。在实践中,显式计算雅可比矩阵通常令人望而却步。加速优化的最常见和最实用的方法是利用问题的稀疏性或做出特定假设来简化它。
发明描述了一种新的更新规则,计算为梯度下降步骤和网络更新的加权组合。在实施例中,使用具有内部存储器的优化器,使用RNN来预测网络更新和组合权重。
通过这种方式,网络可以选择遵循梯度或网络方向更多,同时能够使用当前和过去的残差值。
基于相关算法,微软提出了一种新的神经优化器,它容易适用于不同的拟合问题;可以在不需要大量努力的情况下以交互速率运行;不需要手工制作先验;携带有关先前求解迭代的信息;独立控制每个参数的学习率;鲁棒性和收敛速度;结合了梯度下降法和一种能够快速降低拟合能量的方法。
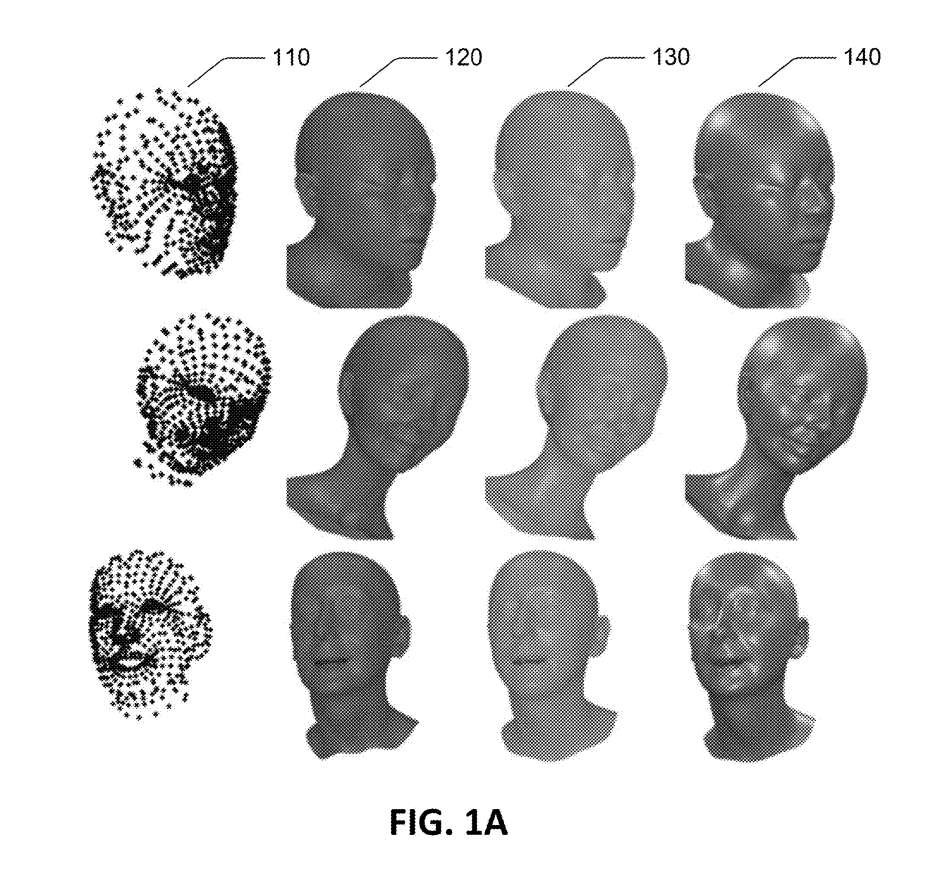
图1A所示的是将3D人脸模型的姿态、表情和身份参数拟合到密集的2D Landmark的示例:目标2D Landmark110、LM筛选结果120、筛选结果130和ground-truth 140。
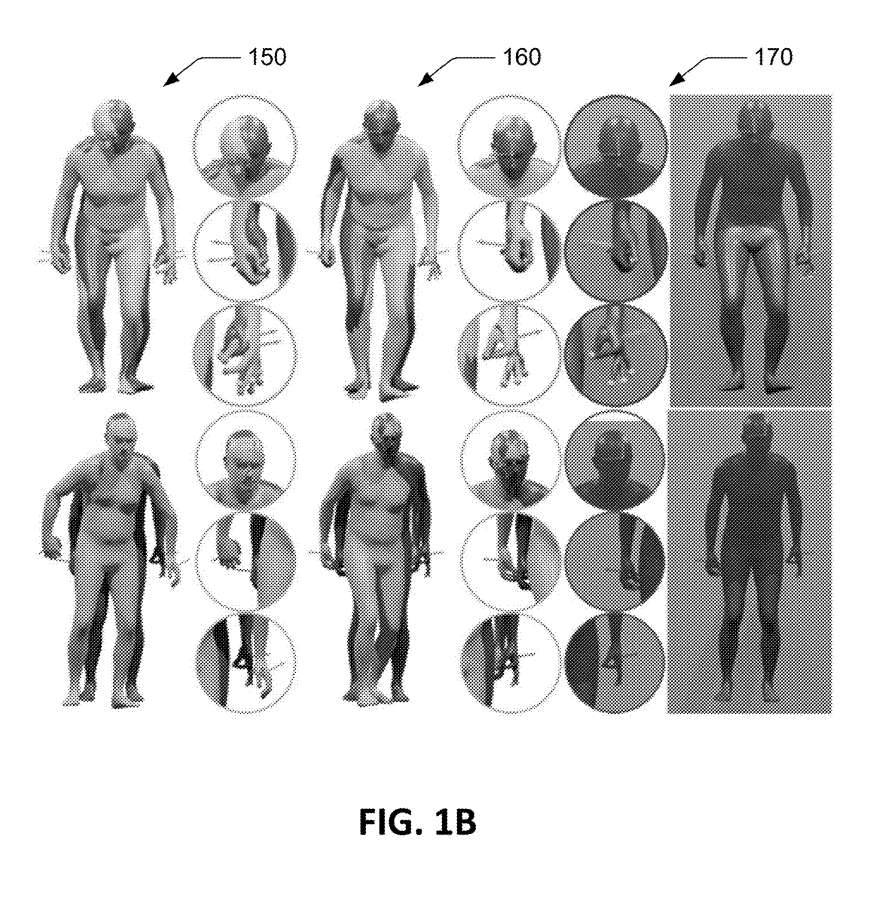
图1B所示的是使用SMPL+H滤波器从头显信号估计出的身体的示例:初始Φ输出(黄色)150,滤波器的迭代N=5(黄色)160,ground-truth overlay 170(蓝色)。发明描述的学习优化器成功地拟合目标头部和手部数据,并为完整的3D身体产生合理的姿势。在第二排,手在视场之外,所以不完全拟合。
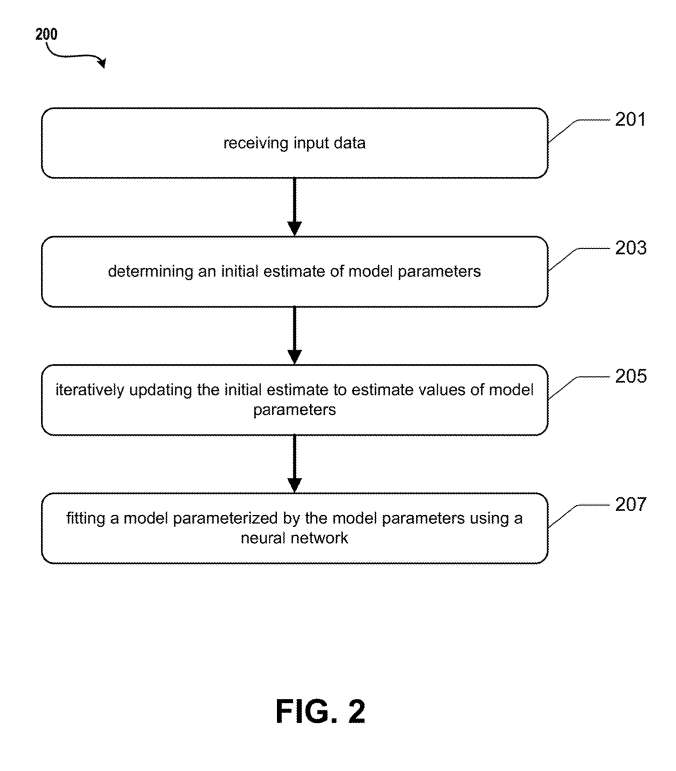
图2示出了一个操作程序。操作201表示接收输入数据D。操作203说明基于输入数据D,确定模型参数的初始估计Θ0。
操作205演示了使用机器学习,迭代地更新初始估计Θ0以估计模型参数的值Θ。操作207说明拟合模型参数参数化Θ使用神经网络Φ。
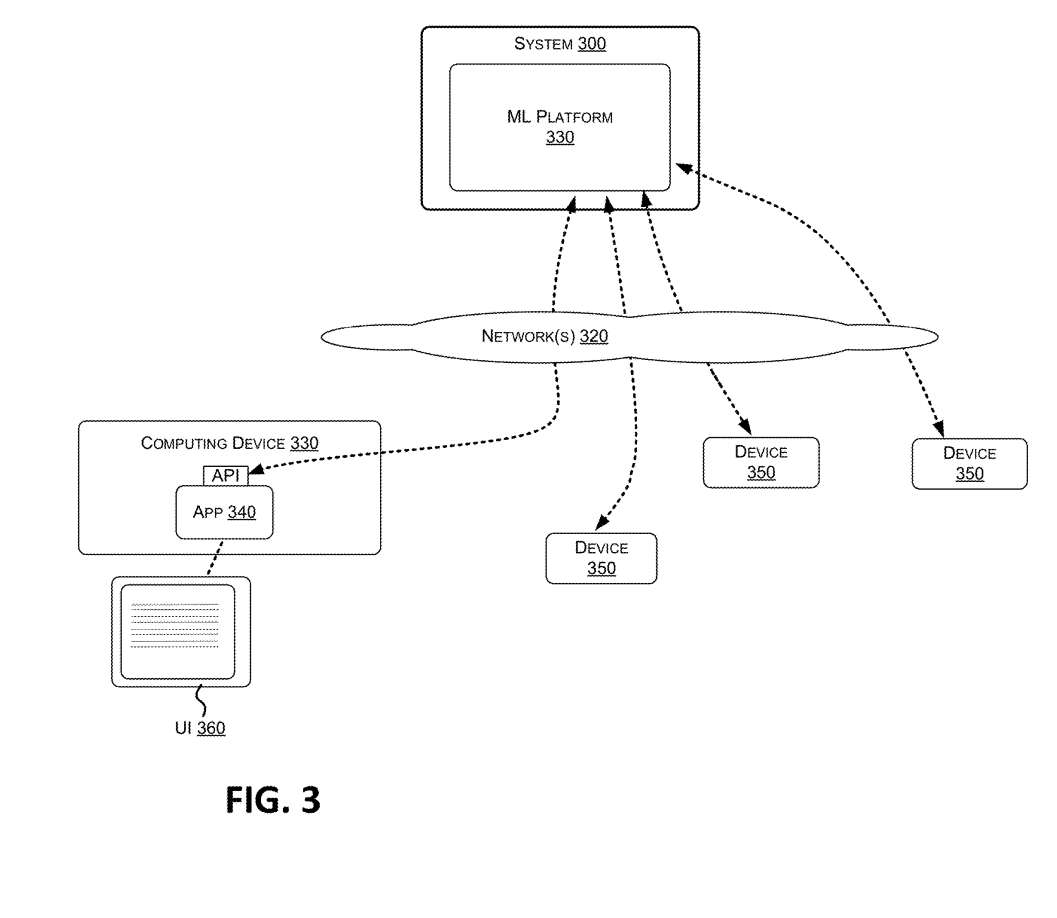
图3示出了实现机器学习330的系统300。可以将ML平台330配置为通过网络320以及计算设备330向各种设备350提供输出数据。用户界面360可以在计算设备333030呈现。用户界面360可以与应用程序340一起提供。
机器学习平台330可以实现机器学习系统来执行一个或多个任务。机器学习平台330利用机器学习系统来执行诸如图像和书写识别等任务。机器学习系统可以配置为使用本文所述的技术进行优化。
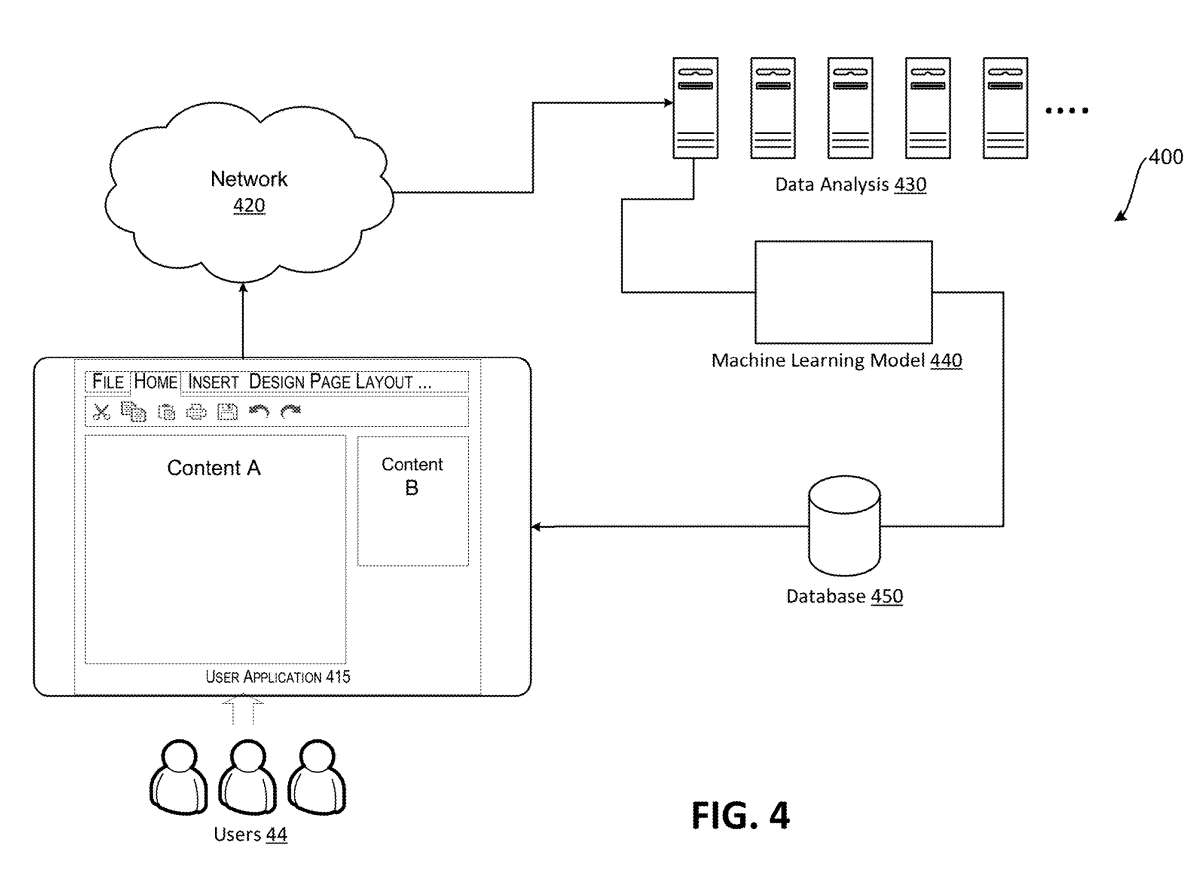
图4显示实现机器学习模型的系统架构图。如图4所示,可以将机器学习系统400配置为基于由数据分析组件430收集和处理的各种数据来执行分析、识别、预测或其他功能。
数据分析组件430可以包括诸如物理计算设备、相关的硬件组件和网络组件。数据分析组件430同时可以包括操作系统和应用程序等虚拟组件。
数据库450可以包括数据,如数据库。反馈可用于进一步更新机器学习模型420使用的各种参数。可以向用户应用程序415提供数据,以便使用应用程序415向各种用户44提供结果。
在特定配置中,机器学习模型420可以配置为利用监督和/或无监督机器学习技术。
微软指出,发明描述的基于稀疏性诱导正则化优化的模型压缩框架可以减少在相关系统和应用中需要处理的数据量。在处理大量数据的迭代时,有效的模型压缩可以为使用所述技术的众多应用程序提供改进的延迟,例如图像和声音识别、推荐系统和图像分析。
相关专利:Microsoft Patent | Optimization-based parametric model fitting via deep learning
名为“Optimization-based parametric model fitting via deep learning”的微软专利申请最初在2022年4月提交,并在日前由美国专利商标局公布。