微软AR/VR专利介绍视觉里程计改进全息图的环境姿态理解
帮助执行鲁棒深度计算和由此产生的姿态估计
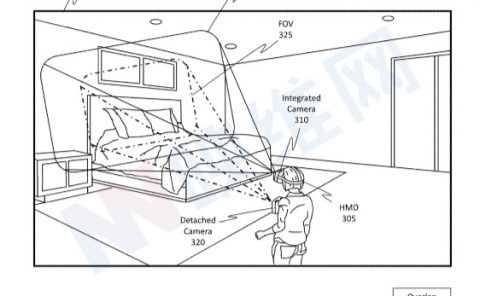
(映维网Nweon 2024年08月07日)全息图可以分为视场锁定全息图或世界锁定全息图。世界锁定全息图意味着锚定到现实世界。无论用户的移动如何,世界全息图都与现实世界锚定在一起。
相比之下,对于视场锁定全息图,无论用户视场发生任何移动,它都会持续显示在用户视场的特定位置。例如,视场锁定全息图可以持续显示在用户视场的右上角。
为了正确显示世界锁定全息图,MR系统需要获得对环境的空间理解以及相对于环境的姿态。显然,这就要求改进MR系统姿态的确定或估计方式。
在日前由美国专利商标局公布的一份专利申请中,微软就介绍了一种相关的视觉里程计。
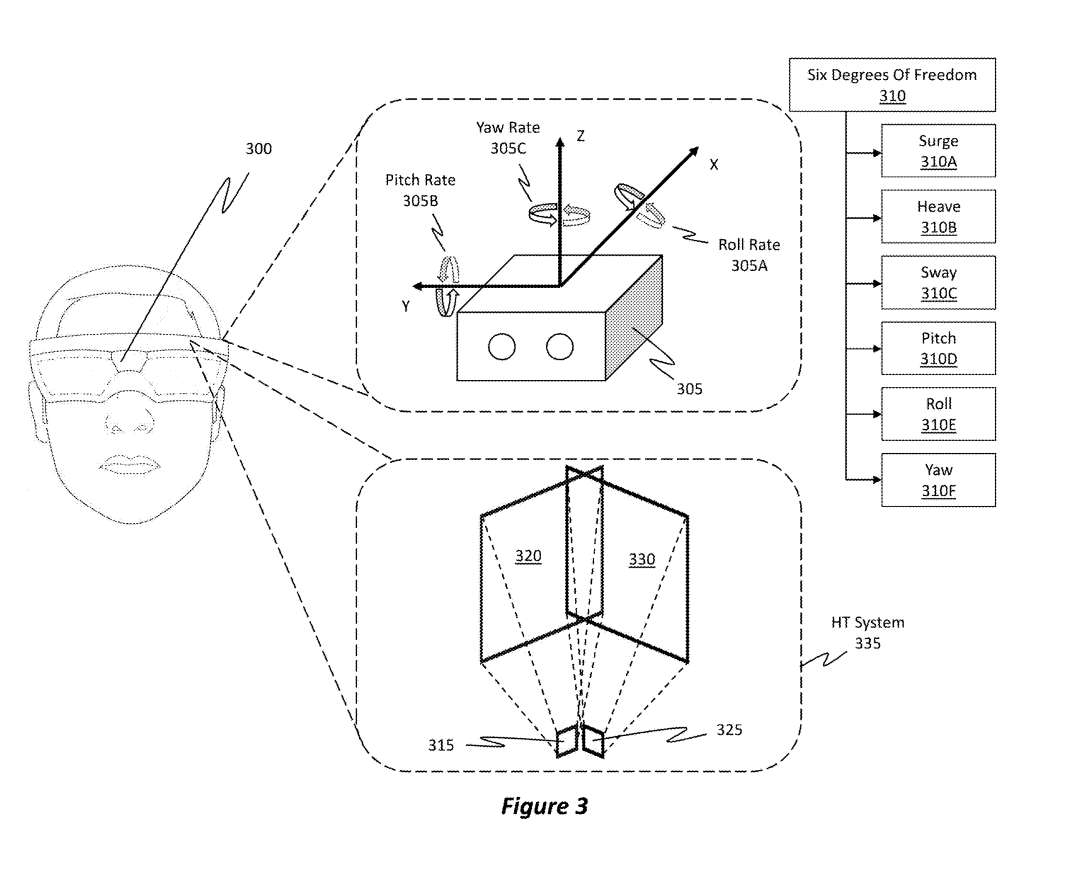
图3示出了第一摄像头315及其相应的视场320的可观测区域,以及第二摄像头325及其相应的FOV 330。
头显300能够利用IMU 305产生的显示定位信息和摄像头系统335产生的显示定位信息来确定头显300的位置和姿态。位置和姿态信息将允许头显300能够在MR场景中准确渲染全息图。
最先进的追踪是通过高效准确的视觉惯性里程计VIO模块实现。通常,VIO模块从IMU获取带有时间戳的图像和数据作为输入。系统使用图像、现有的3D点和关于设备状态的知识来计算对应于3D世界点的2D特征观测值。
为了完成全息图放置操作,可以使用运动模型(如卡尔曼滤波器)将来自摄像头的信息和来自IMU的信息结合起来,以提供鲁棒的头部追踪位置和姿态估计,并使用位置和姿态信息执行全息图放置。
卡尔曼滤波器是一种组合算法,其中多个传感器输入在规定的时间段内收集,并使用IMU和摄像头组合来提供相较于单独传感器更准确的显示定位信息。
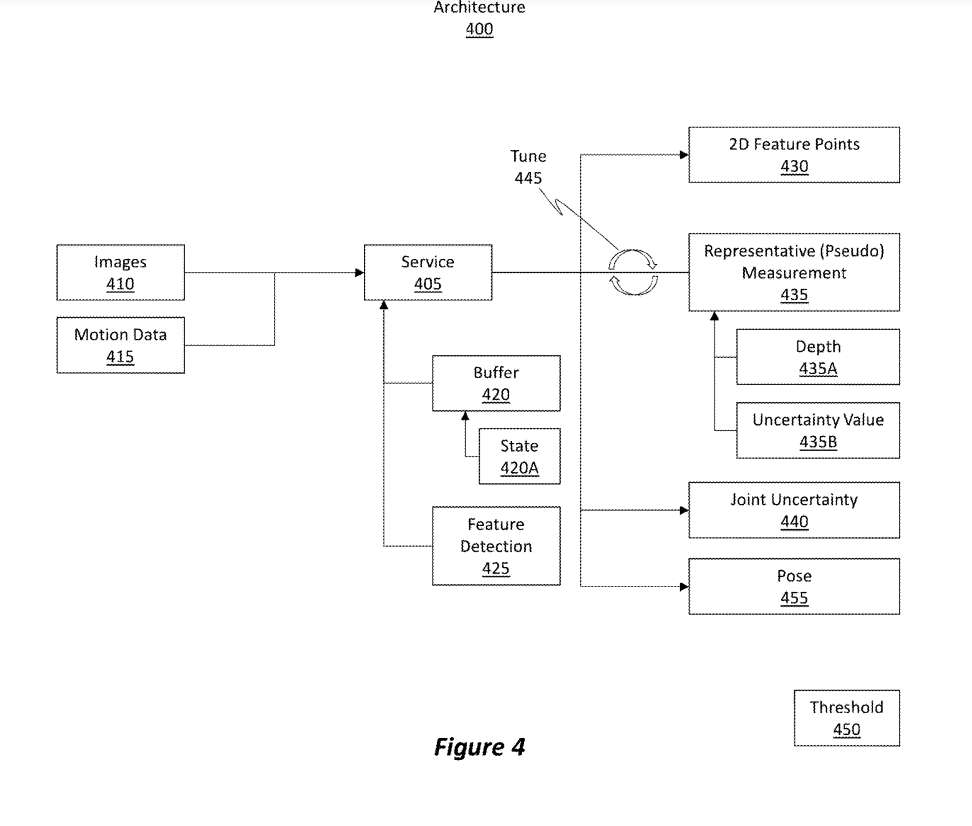
图4演示的示例架构400包含服务405。服务405可以是任何类型的服务。架构400展示了如何将一组图像410作为输入馈送到服务405。
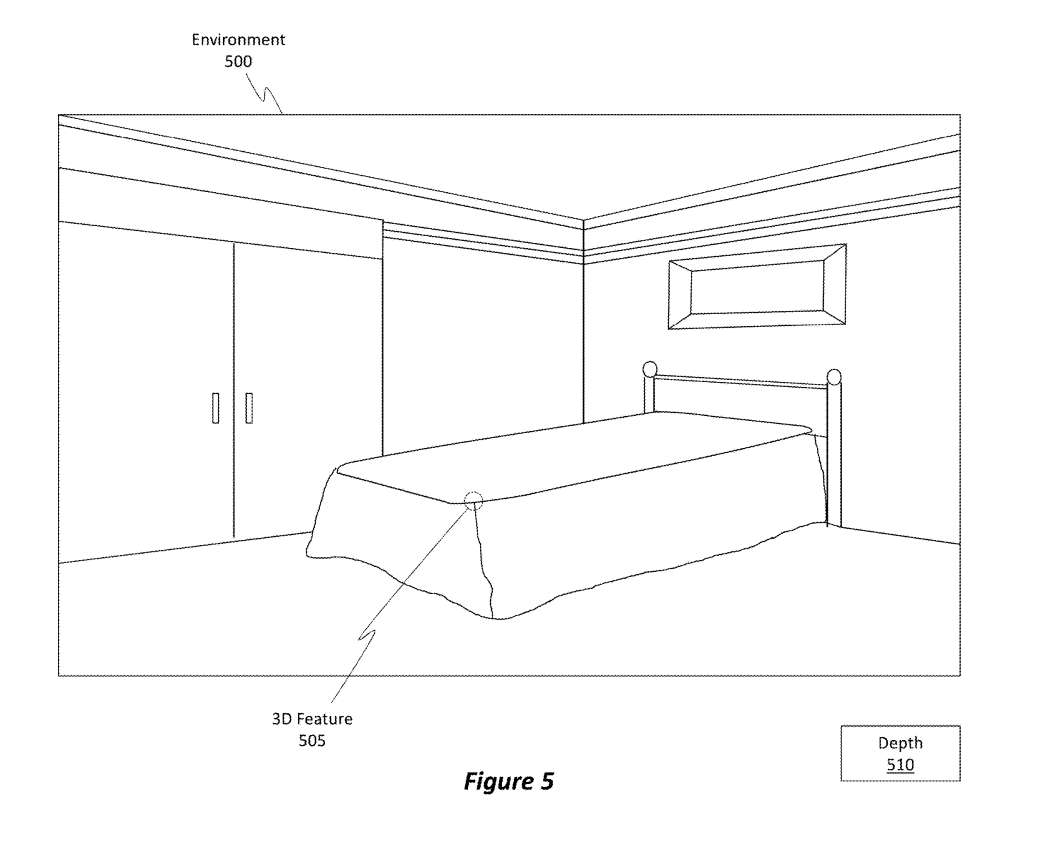
作为示例,图5示出环境500的一个示例卧室。图5同时示出包括在环境500中的特定3D特征505。在本例中,3D特征505是床的一角。另外,3D特征505具有相对于可以拍摄环境500的图像的摄像头位置的确定深度510。
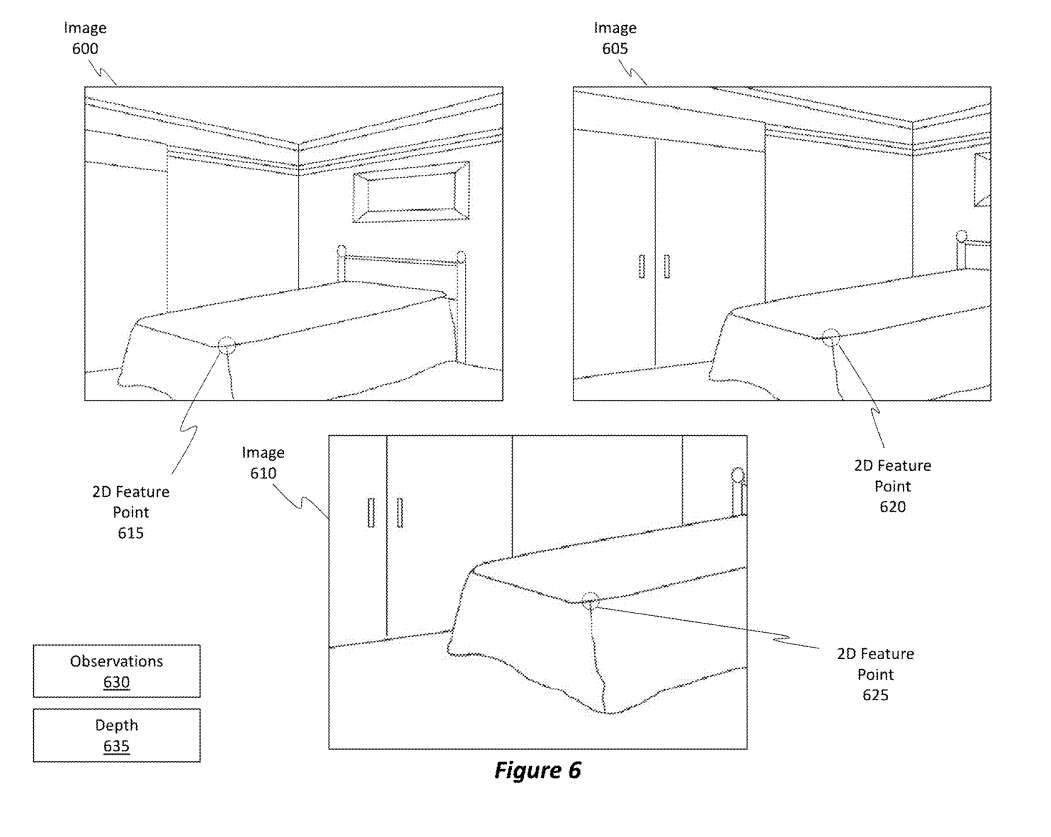
图6显示了图5中环境500的三种不同图像。例如,图6显示了第一图像600、第二图像605和第三图像610。注意,所有三个图像都包括对图5中的3D特征505的观察。即,2D特征点615是指一组一个或多个图像像素,其表示环境500中包含的可检测特征或对象。
回到图4,图像410可以代表图6中的图像600、605和610。图像410作为输入馈送到服务405。
在一个实施例中,运动数据415可以作为输入馈送到服务405。运动数据415可以包括由IMU生成的数据。
服务405使图像410存储在缓冲区420中。通常而言,将缓冲区420的大小设置成它可以存储选择数量的图像和/或选择数量的估计状态,如状态420A所示。图像的数量在2到16个图像之间。状态420A可以包括在图像中反映的姿态信息。所述状态420A可包括其它可变信息,如定时信息、速度信息和/或传感器的内在或外在参数。
服务405同时负责对图像410执行特征检测425。通过“特征检测”,意味着服务405能够计算图像的各种抽象,然后为每个像素做出集中或本地化的决策,以确定是否存在由像素表示的特定类型的内容。
换句话说,特征检测是指对每个像素进行分类或分配类型的过程,其中分配的类别是基于像素所代表的内容。
例如,如果图像中的一组像素表示一只狗,则像素中的每一个都可以归类为“狗”类别。特征检测执行这种分类。另外,可以定制特定类型的类别,以便特征检测搜索特定类型的内容,例如执行角、边或其他可区分的对象。
参照图6,服务405对图像600、605和610进行特征检测。服务405将2D特征点615、620和625识别为图5中3D特征505的观测值630。特征点615、620和625中的每一个都可以具有确定的相应深度635值,其中深度635是3D特征505相对于生成图像600、605和610的摄像头的实际深度510的尝试近近值。
返回到图4,如前所述,服务405导致将图像410存储在缓冲区420中。在某些情况下,当图像410存储在缓冲区420中时,特征检测425发生。在其他情况下,特征检测425在图像410存储在缓冲区420之前发生。图7示出了所述缓冲器420。
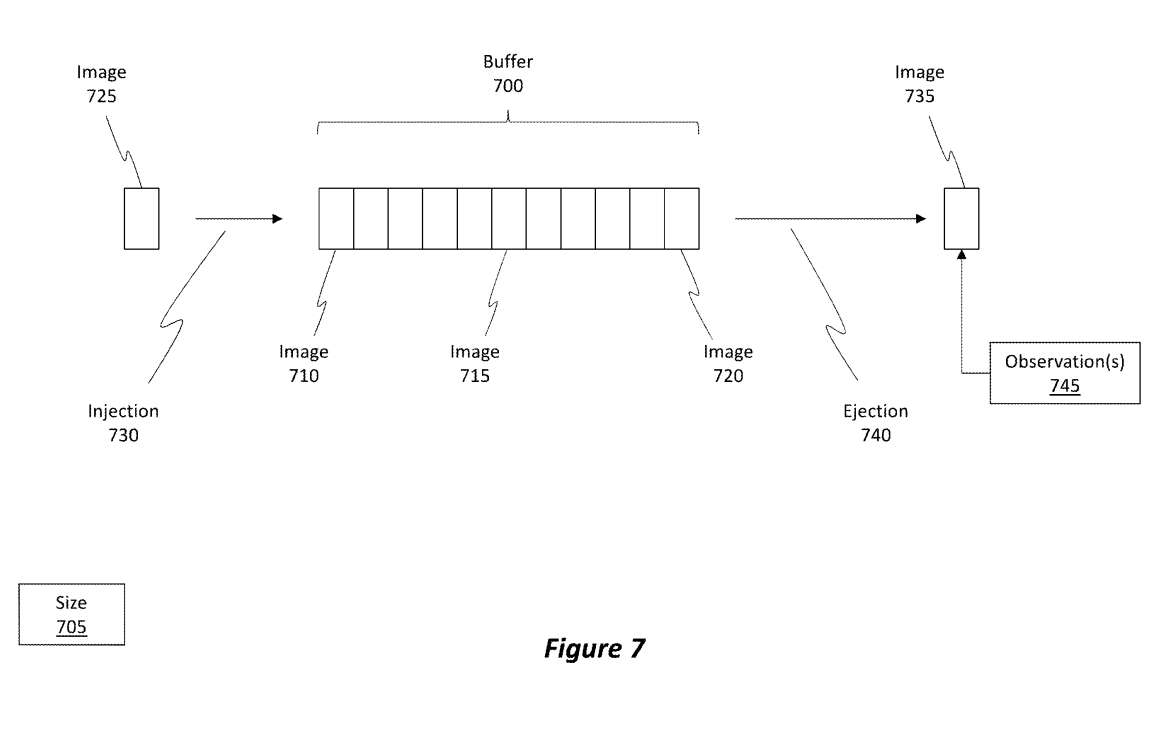
图7所示为缓冲器700,其代表缓冲器420。缓冲区700的大小705是有限的,它支持或可以包含一定数量的图像。
图7显示了存储在缓冲器700中的若干图像。例如,除其他外,缓冲区700目前正在存储图像710、图像715和图像720。目前,缓冲区700的存储能力已达到极限。如果要将新图像注入或插入到缓冲区700中,则将需要从缓冲区700中弹出现有图像,例如弹出740。
缓冲区中的各种不同图像包括对3D特征的观察。观察结果用于确定3D特征的深度。深度数据是有用的,因为它有助于通过使MR系统确定其相对于环境的姿态来定位MR系统。全息图的显示依赖于MR系统的姿态。所以,为了确保MR系统能够提供高质量的图像内容,需要具有准确和鲁棒的深度数据。
另外,缓冲区700中的旧图像包含可用于确定3D特征深度的丰富数据量。通常情况下,缓冲区700中的旧图像从与新图像不同的有利位置或角度观察3D特征。有时候,较旧的图像从不同的深度观察到3D特征。
所以,新旧图像的组合提供了一个更大的基线来从中计算3D特征的深度,通常情况下,更大的基线可以更准确地确定深度小。
当其中一个图像从缓冲区700中弹出时,特别是其中一个较旧的图像,则可用于计算深度的可用数据或观测量745通常会减少。通常情况下,最早的映像首先弹出,例如在先进先出类型的队列中。当然,缓冲器700可以选择以任何方式配置,而且不限于先进先出方案。
当与新图像进行比较和对比时,新旧图像的组合提供了确定深度的强大机制。然而,当旧图像弹出时,传统的情况是,现在可用于确定深度的数据量显着减少。由于这种减少,深度计算的稳健性将有所减损。
微软介绍的实施例旨在减轻从缓冲器700弹出图像时发生的影响,以便可以执行鲁棒深度计算和由此产生的姿态估计。
回到图4,服务405的任务是从图像中识别2D特征点430,如前所述。例如,图6中的二维特征点615、620和625代表二维特征点430。
服务405同时负责计算所谓的“代表性度量”或“伪度量”,如代表性度量435所示。在一个实施例中,为图像中的每个2D特征点计算代表性测量435。作为示例,为2D特征点615计算第一代表性测量,为2D特征点620计算第二代表性测量,并且为2D特征点625计算第三代表性测量。代表性测量中的每一个都与图5中的3D特征505相关或相关联。
应当注意,实施例如何避免或不计算每个2D特征点的代表性测量。在一个实施例中,代表性测量的数量可以小于特定3D特征的2D特征点的数量。例如,假设5张图像通常具有相同的3D特征。服务可以为3D特征识别5个2D特征点。然后,可以生成5种不同的代表性测量。然而,其他实施例可以产生少于5个代表性测量。
代表性测量435包括为3D特征505确定的深度435A。代表性测量435包括对于所确定的深度435A的确定的不确定度值435B。不确定度值435B反映了在特定图像内可获得多少深度信息的相应度量,以确定3D特征的深度435A。
特定图像可能比其他图像具有更多可用的深度信息,所以特定图像的不确定性值可能更高或更低。一般来说,不确定性值435B反映了计算深度435A准确性的可能性。
在一个实施例中,仅当要从缓冲区420弹出图像时才计算代表性测量值。所以,在填充缓冲区420时不计算有代表性的测量。从缓冲区420弹出图像可以是导致计算代表性测量的触发事件,包括要弹出的图像。
服务405同时为图像集410计算所谓的联合不确定度440。联合不确定度440是基于代表性测量的组合计算。
在计算联合不确定度440之后,服务405允许从缓冲区420弹出图像之一。可选地,一个新的图像可以注入到缓冲区420。联合不确定度440现在将作为“检查”或“中间量”运行,用于以调谐操作的形式优化结果的代表性测量。
换句话说,服务405执行调优操作来调优伪测量的不确定性,以尽量减少由于从缓冲区弹出帧而丢失的信息。
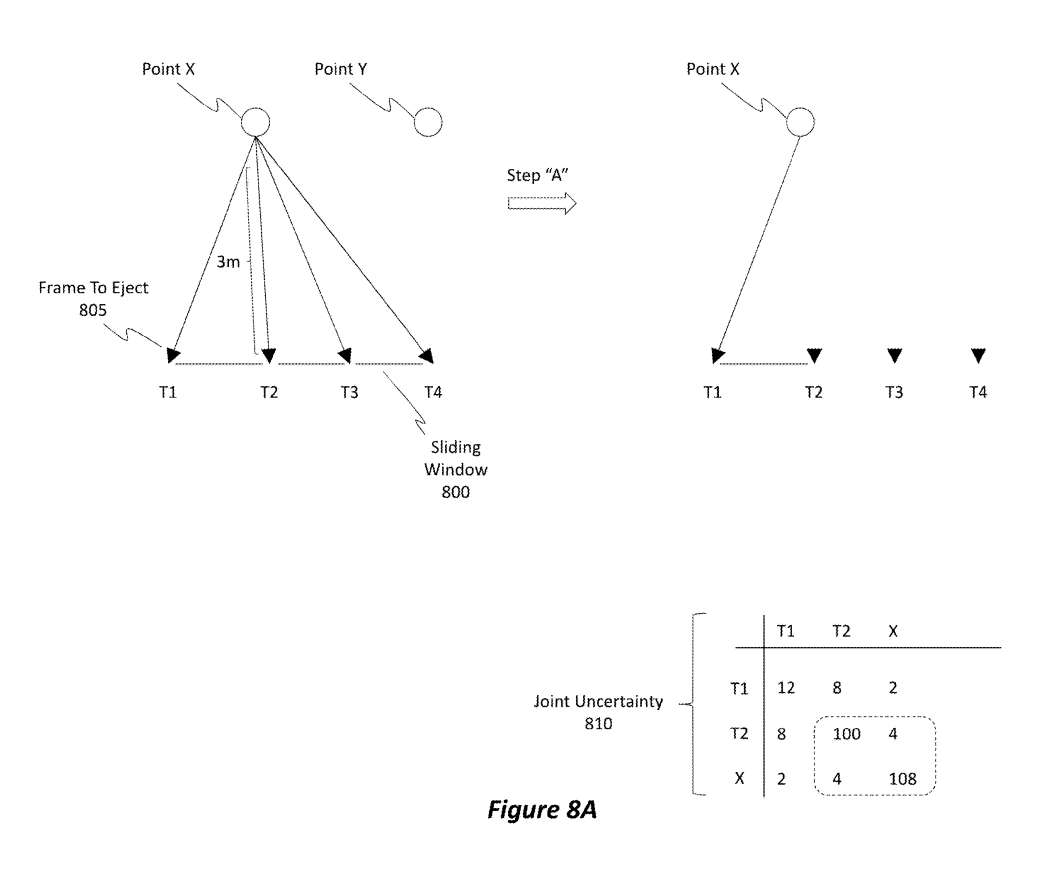
图8A显示了包含4帧的滑动窗口800,标记为T1-T4。图8A同时显示了两个点X和Y。测量值用实线表示。在这个阶段,没有以前的伪测量,但在其他场景中可能有。帧对帧的测量可以存在,但不是严格必要。帧T1从滑动窗口800弹出,如图所示为弹出805的帧。
如图8A所示,在步骤“A”中,服务可以忽略除涉及T1之外的所有测量,因为在这个步骤中,服务的重点是保留将因弹出T1而丢失的信息。这使得服务有两个度量。服务计算点X、T1和T2上的联合不确定度810。通常,联合不确定度810由通过任何测量和/或伪测量与T1相关的所有变量组成。
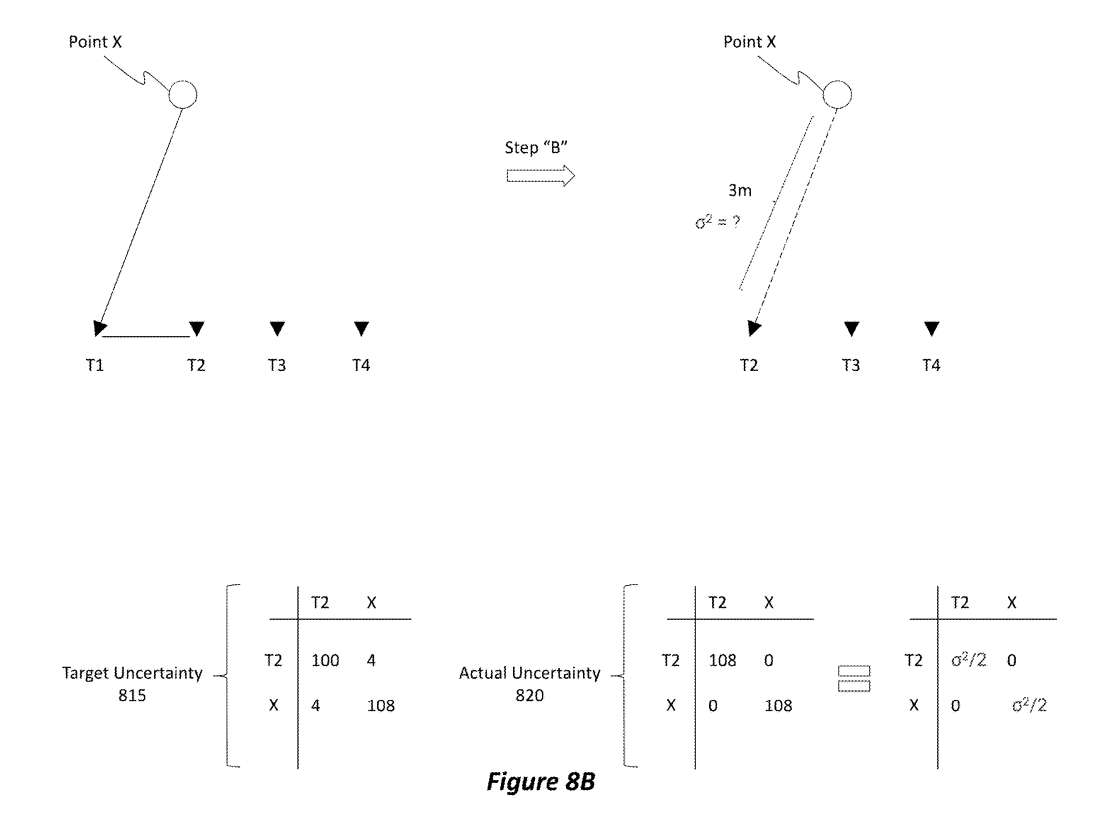
如图8B所示,在步骤“B”中,服务将对帧T2中点X的单次伪测量计算不确定度。图8B示出目标不确定度815和实际不确定度820。注意,目标不确定度815对应于图8A的联合不确定度810中的框值。
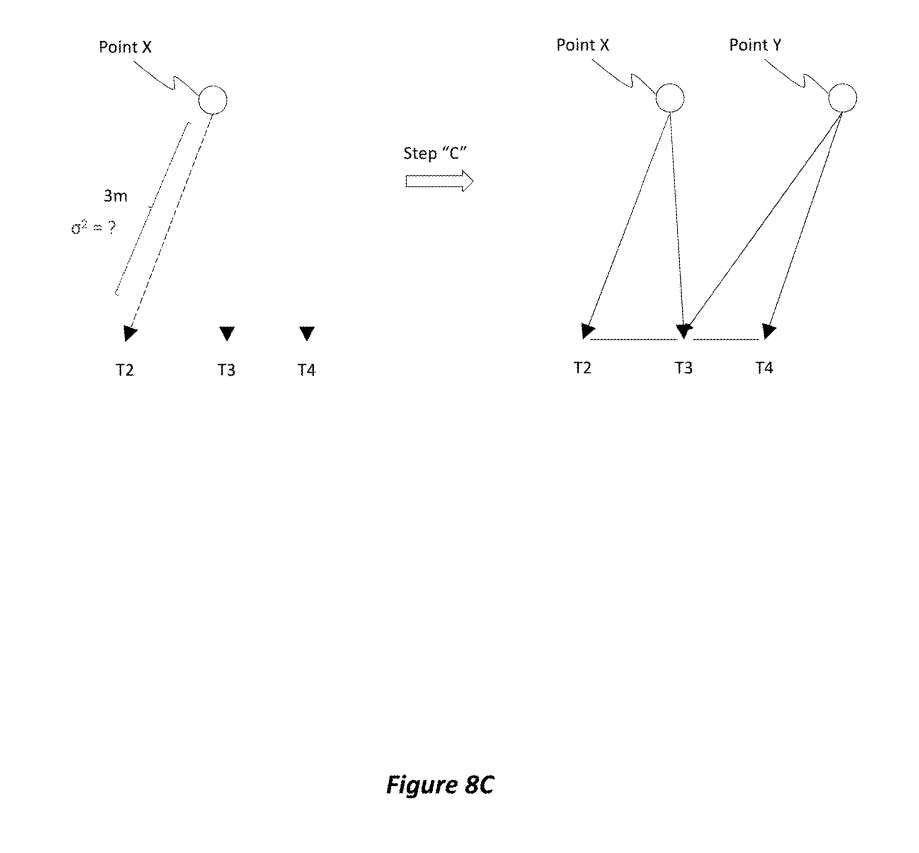
如图8C所示,在步骤“C”中,服务将伪测量并入弹出T1的滑动窗口中。服务现在不再考虑先前计算的联合不确定性。服务可以用一个新的框架来增加滑动窗口,并重复这个过程,将其视为任何其他追踪系统。在这里,伪测量的生成和合并作为替代方法,可以删除最旧的帧并丢失信息。
回到图4,“调优”的代表性测量以某种方式进行调优,使得所得到的联合不确定性相对于缓冲区420满时计算的联合不确定性在阈值450度内。调整后的代表性测量值可用于计算或估计设备的姿势。
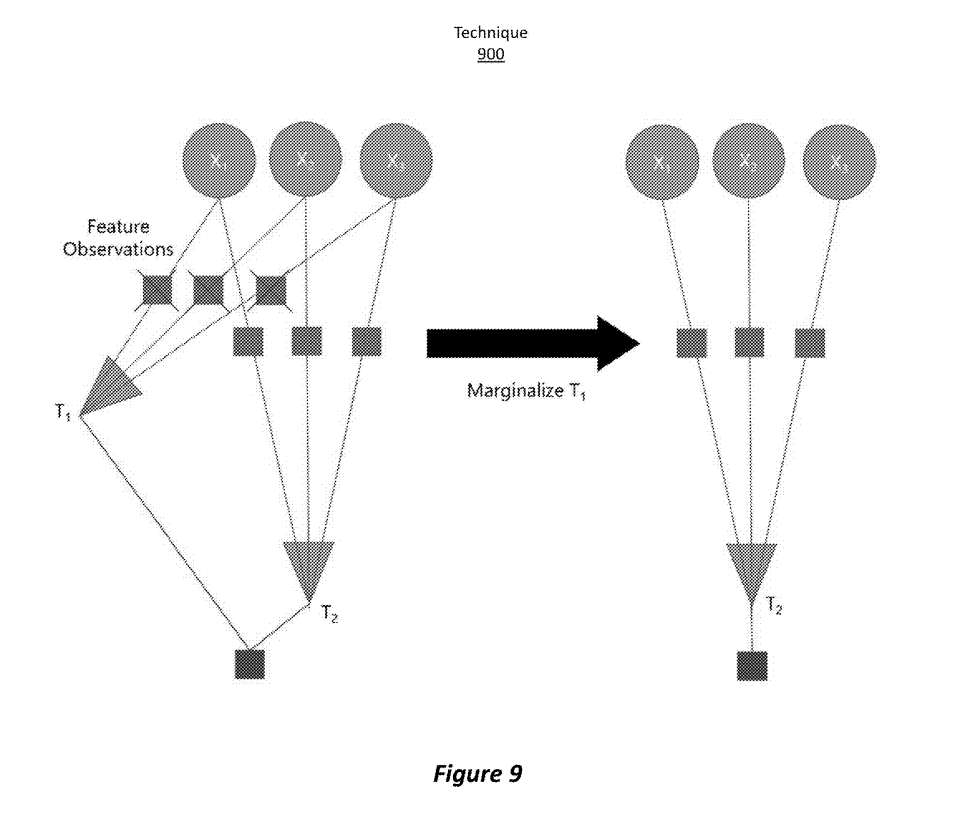
图9示出通过移除最旧关键帧的状态来维持状态滑动窗口的技术900。优化问题中包含各种测量或约束。每个编码连接到它的变量的特定信息。
中间的方格是由图像衍生的3D点的2D观测值。下面的正方形是一个边缘化先验,编码关键帧之间关系的信息,包括它们的相对姿势和惯性测量的可选约束。所应用的转换称为“边缘化”,它由移除最旧的关键帧所需的特定数值计算组成。在边缘化之前,通常会删除对最旧和最新关键帧都可见的特征观察。这将导致信息的丢失,进而降低追踪的准确性。
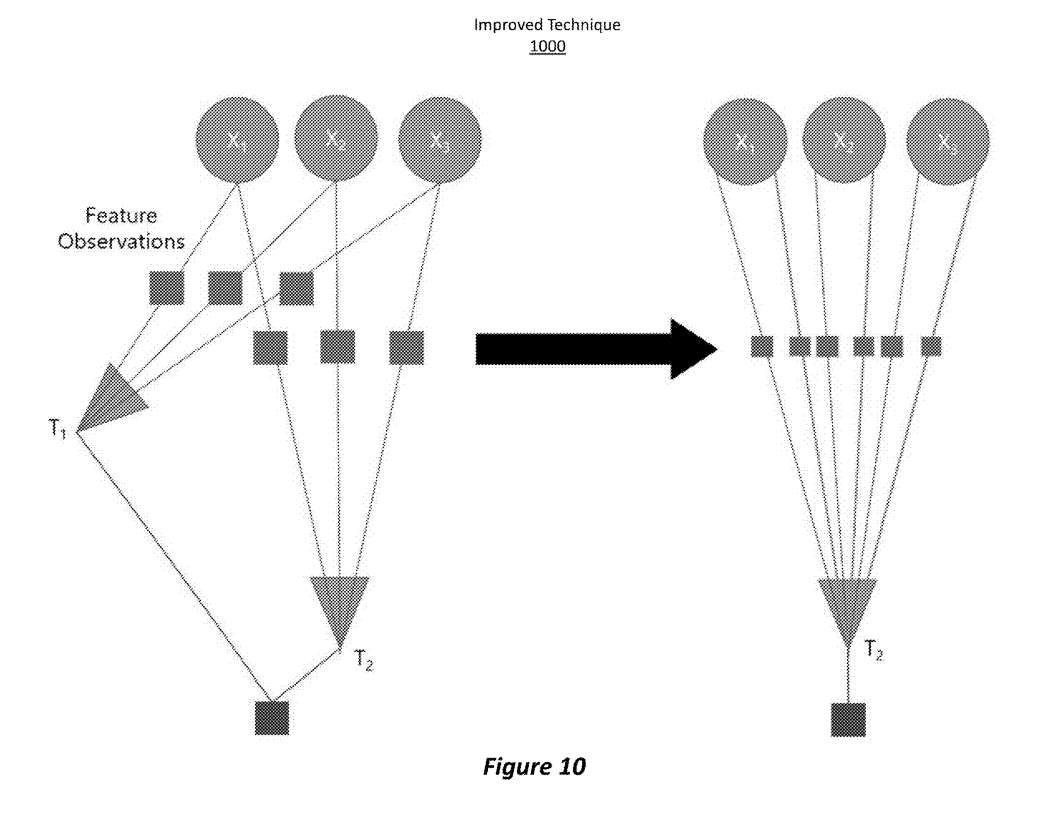
图10给出了改进技术1000的概述。
在移动设备中嵌入由陀螺仪和加速度计组成的惯性测量单元。一个或多个可见光摄像头连接到设备。基于设备状态滑动窗口的VIO方法用于融合视觉和惯性测量,产生设备运动的估计。通过求解非线性最小二乘优化问题来估计器件的状态。更新后的设备瞬时状态返回给其他子系统。
以前的状态通过产生伪测量值的过程从滑动窗口中移除,并将其纳入后续的优化问题中。伪测量减轻了信息丢失,从而提高了追踪精度。
实施例首先只考虑图9中仅包括将边缘化的变量T1、涉及变量的任何误差项以及涉及误差项的任何变量的部分。所以,描述剩余变量建模的高斯分布将具有密集的信息矩阵。由于缺乏结构,这个问题往往成本太过昂贵而无法解决。所以,需要用与稀疏信息矩阵相关的伪测量来近似信息。
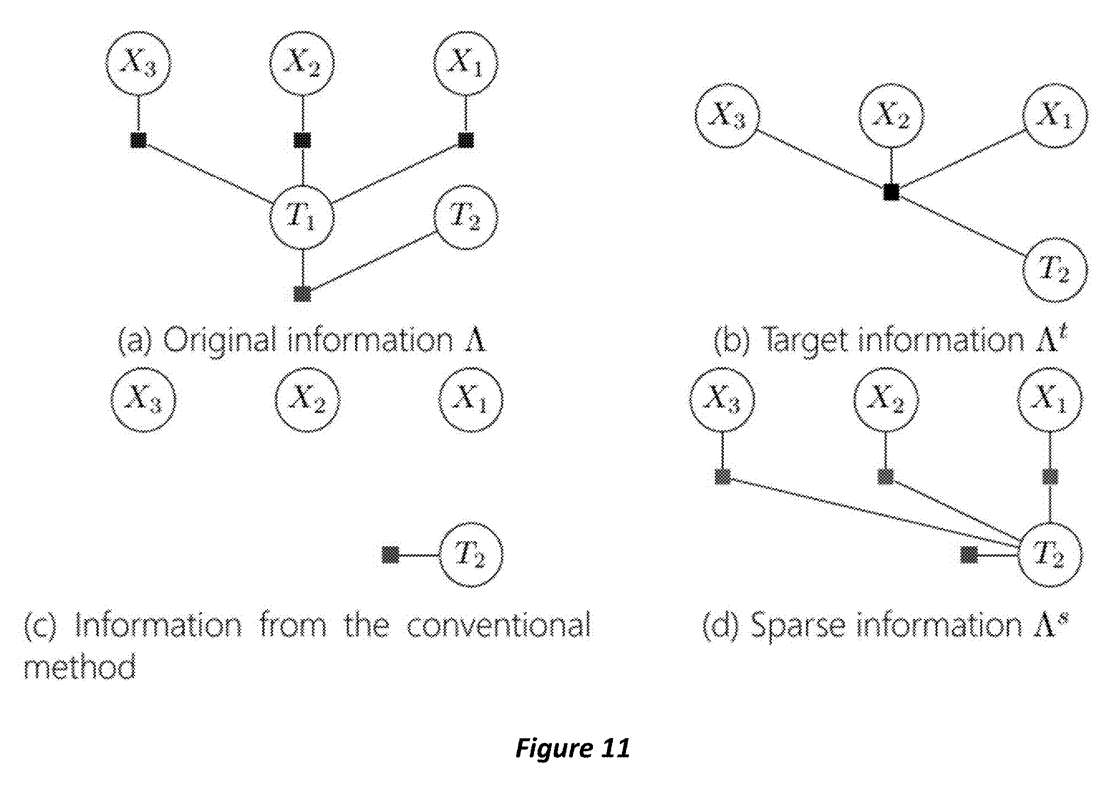
图11显示了各种子图,包括:
-
要边缘化的变量和相关的误差项
-
将由普通边缘化过程产生的信息
-
将由传统的丢弃观测值方法产生的信息
-
用伪测量近似目标信息的稀疏信息。稀疏信息与传统方法一样具有期望的结构,但保留了更多的信息。
给定图11所示的结构,所述实施例可以将信息矩阵划分为块。
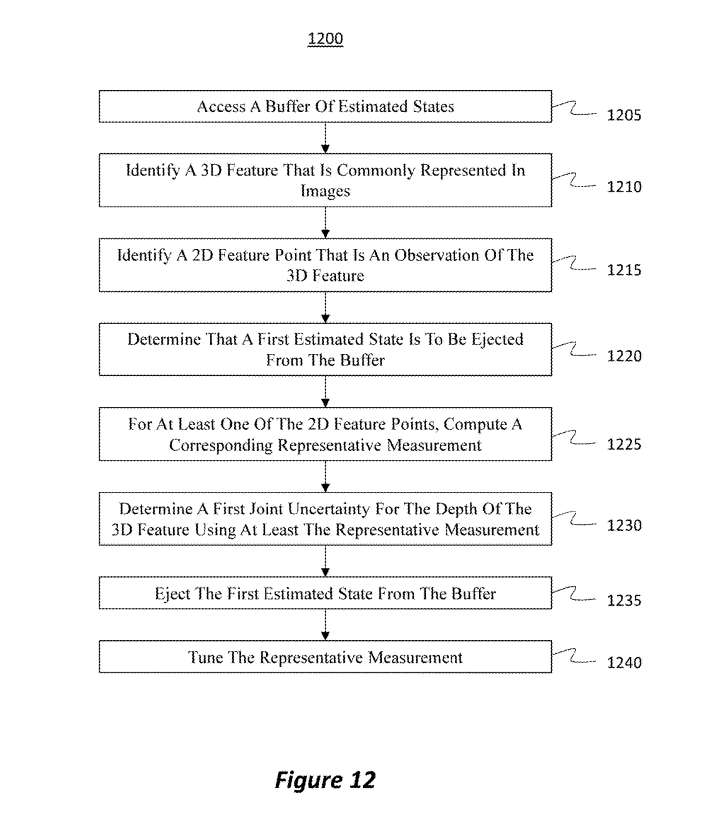
图12演示了相关示例方法。方法1200可以在图4的架构400内实现。另外,方法1200可以由服务405实现。
在1205,访问基于源自多个图像的视觉观察生成的估计状态的大小有限缓冲区。
在1210,识别通常在图像中表示的3D特征。例如,可以在图像600、605和610中的每一个中识别3D特征505。
在1215,在每个图像中识别2D特征点,所述特征点是对3D特征的观察。值得注意的是,这图像提供了可用于确定3D特征深度的数据。
在1220,确定将从限制大小的缓冲区中弹出的第一估计状态。任选地,可以另外或交替地从缓冲区中弹出第一图像。发生这种情况可能是因为一个新的图像现在可以插入到缓冲区中,或者因为一个新的估计状态将插入到缓冲区中。
对于所述2D特征点中的至少一个,1225包括计算包含相应深度和该深度的相应不确定度值的相应代表性测量(又称伪测量)。所以,计算一个或多个代表性测量值。每个不确定性值都反映了一个相应的测量,即有多少深度信息可用于确定3D特征的深度。
更详细地说,对于有N个值的测量,不确定性值是高斯分布的N × N协方差矩阵。
每个不确定度值通常基于图像的像素分辨率。与具有较低像素分辨率的图像相比,具有较高像素分辨率的图像为确定深度提供了更好的框架。
在1230,使用至少一个或多个代表性测量来确定3D特征深度的第一联合不确定度。第一联合不确定度考虑了实际深度测量数据和一个或多个代表性测量。
在1235,从限制大小的缓冲区中弹出第一图像和/或第一估计状态,从而对可用于确定3D特征深度的数据进行修改。
在第一图像和/或第一估计状态剔除后,1240包括调整一个或多个代表性测量,直到基于调整的一个或多个代表性测量的产生的第二联合不确定度在与第一联合不确定度相似的阈值水平内。
换句话说,代表性测量的不确定度是可调的。深度值通常是固定的。与测量和伪/代表性测量相关的不确定性随后用于姿态估计。利用测量值和不确定性进行估计可以用加权最小二乘、卡尔曼滤波或类似的方法来完成。

图13示出的流程图用于为计算深度保留一定程度的不确定性。方法1300可以通过图4中的服务405来实现。
在1305,法1识别在包含在缓冲器中的图像中表示的3D特征。所述图像包括第一图像和第二图像,所述图像提供可用于确定所述3D特征的深度的数据。
在1310,在图像中识别2D特征点,所述特征点是对3D特征的观察。
在1315,对2D特征点计算包含深度和深度不确定值的伪测量。
在1320,使用所述伪测量确定3D特征深度的第一联合不确定度。
在1325,从缓冲器中弹出第一图像,至少暂时导致减少到可用于确定3D特征的深度的数据量。对可用于确定所述3D特征的深度的数据量的减少包括在所述图像中并且相对于所述3D特征可用的若干观测值的减少。
在1330,调整伪测量,直到所得到的基于所述伪测量的第二联合不确定度在与第一联合不确定度相似的阈值水平内。调优伪测量可以包括修改作为伪测量一部分的深度的不确定度值。在一个实施例中,不确定性值只确定一次,而不是从以前的某个值修改。
方法1300同时包括将新图像注入缓冲区。然后,这个过程可以使用这个新图像重复自己。
总的来说,发明所述的实施例改进了如何基于深度数据估计设备姿势的技术。当图像从滑动窗口或缓冲区弹出时,即便用于计算深度数据的观测数据丢失,所述实施例都能够提供高度准确的估计。
相关专利:Microsoft Patent | Visual odometry for mixed reality devices
名为“Visual odometry for mixed reality devices”的微软专利申请最初在2023年1月提交,并在日前由美国专利商标局公布。