微软AR/VR专利提出基于神经辐射模型的虚拟姿态渲染
基于神经辐射模型的虚拟姿态渲染
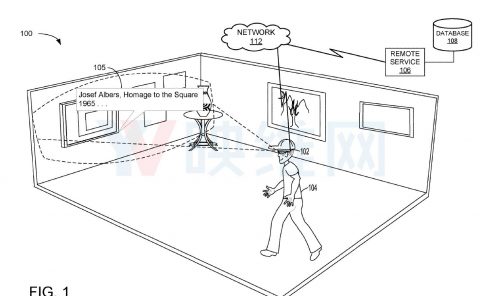
(映维网Nweon 2024年08月09日)对于VR头显会用虚拟内容取代用户对现实世界对象的感知。
如图1所示,由于用户无法看到现实世界对象,所以在参与VR体验时,用户可能很难与现实世界的对象进行交互。
为了解决这个问题,相关物品可以使用特定的虚拟模型来表示。这种虚拟模型在虚拟环境中与真实物品相对于用户的位置相同,并可以作为其在虚拟环境中的虚拟表示。然而,你依然很难与真实物品进行交互,除非虚拟表示具有与真实物品非常相似的外观和姿势。另外,生成一个与对应现实世界对象的外观紧密匹配的虚拟对象模型通常非常困难和耗时。
微软在一份专利申请中提出,可以利用神经辐射模型来渲染具有与相应现实世界对象真实姿态一致的虚拟姿态的虚拟对象。
在一个实施例中,捕获真实世界对象的数字图像并用于渲染相应虚拟对象的视图。至少部分地基于由神经辐射模型编码的真实世界对象的3D空间数据。在渲染视图中,虚拟对象具有与真实世界对象的图像姿态一致的虚拟姿态。
然后,虚拟对象视图可以作为虚拟环境的一部分显示,使得虚拟对象能够在VR体验中作为真实对象的逼真表示。
神经辐射模型来源于先前捕获的真实世界对象的多个图像。在一个示例中,真实世界对象是一个单一的、特定的真实世界对象。例如,神经辐射模型是为用户的特定键盘生成,而不是为一般键盘或特定型号的所有键盘生成。
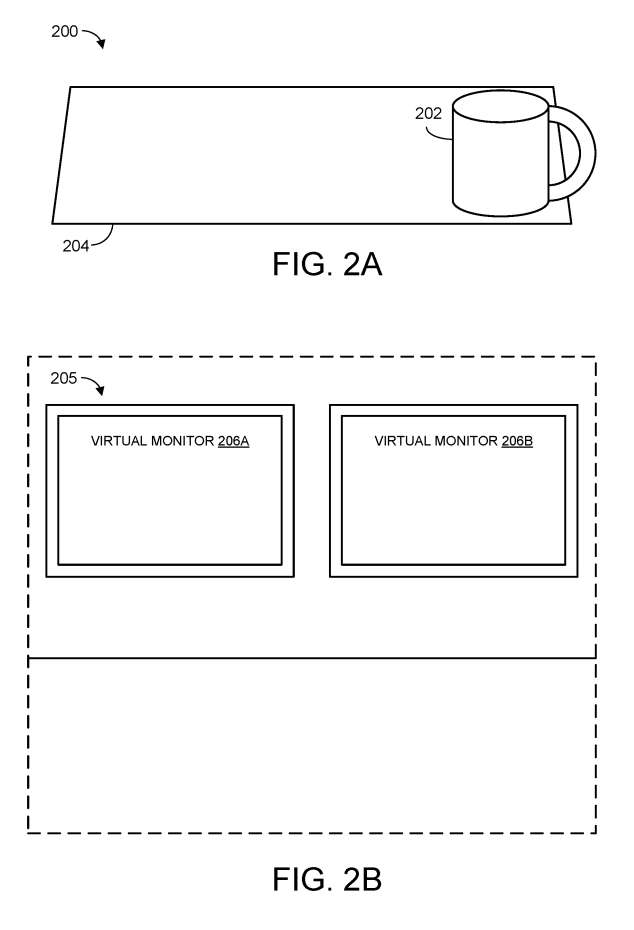
图2A-2C进行了图解说明。图2A显示了一个真实世界的环境200,包括一个示例真实世界的对象202(采用咖啡杯的形式),它位于真实世界的表面204之上。换句话说,环境200是头显用户拿起杯子202喝饮料的真实环境。
图2B显示了由用户头显呈现的示例虚拟环境205。在图2B的示例中,虚拟环境包括两个虚拟显示屏206A和206B,它们不存在于用户的真实环境中。
虚拟环境实质上用计算机生成内容取代了用户对现实世界环境的感知。如图所示,现实世界的杯子202和现实世界的表面204不再可见,因为它们被用于形成虚拟环境的虚拟图像所隐藏。所以,用户很难安全地饮用饮料,因为它不再可见。

转向图2C,从头显的虚拟视角来看,虚拟对象与现实世界的对象对齐。换句话说,从用户的角度来看,虚拟对象208与现实世界的杯子202具有基本相似的外观和姿势。这有利于提供改进人机交互的技术效果,允许用户能够在参与虚拟体验的同时安全地与现实世界的对象进行交互。
在一个实施例中,当检测到真实世界的杯子202的姿势变化时,头显会更新虚拟杯子的渲染姿势,以保持与其真实世界的对应物的一致性。
换句话说,当真实马克杯的位置和方向发生变化时,虚拟马克杯的位置和方向同样会相应更新。另外,头显不需要局限于只呈现一个虚拟对象对应于一个现实世界的对象,而是可以呈现任何适当数量的不同虚拟对象对应于任何相应数量的真实对象。
当用户举起杯子时,头显呈现虚拟图像,描绘用户的虚拟手表示,就像用户在现实世界中执行的动作一样。
另外,头显可以显示一个或多个与虚拟对象相近的虚拟注释。例如在图2C中,头显显示接近虚拟对象208的注释210。这种注释采用任何合适的形式,并且可以包含任何合适的信息。作为示例,注释可以包括零件标签、装配/拆卸/维护说明、标签和虚拟控件等。这有利于在虚拟环境中增强现实世界中的对象。
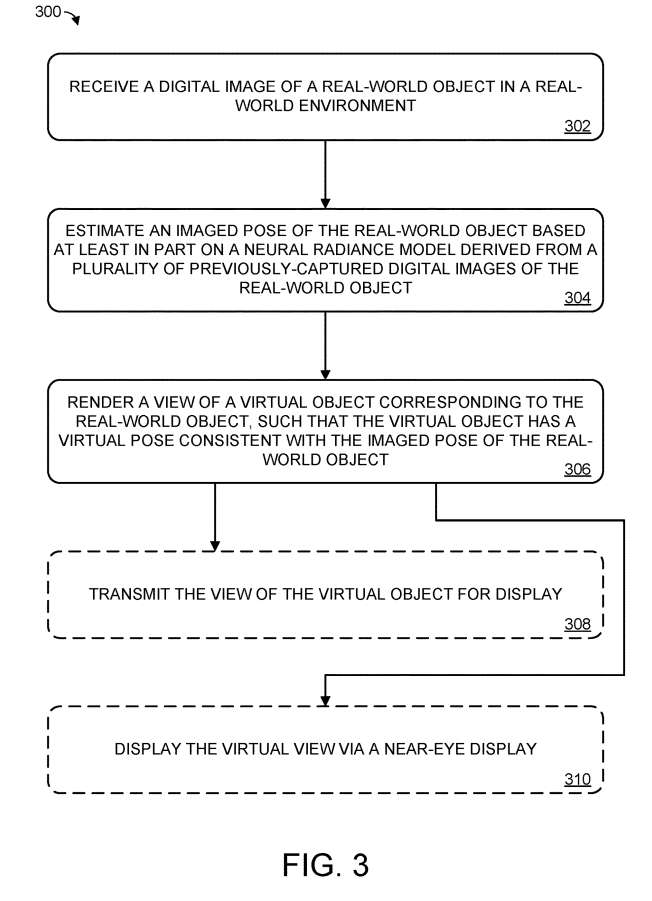
图3示出用于虚拟对象姿态渲染的示例方法300。
在302,接收在真实世界环境中的真实世界对象的数字图像。
在304,至少部分地基于编码现实世界对象的3D空间数据的神经辐射模型来估计现实世界对象的成像姿态。
在一个实施例中,这包括通过在围绕输入对象的几何中心的3D坐标空间内安排输入图像,以及在摄像头中心和输入图像的像素之间投射光线,从而生成成像对象的体三位表示。
在一个实施例中,基于捕获每张图像时摄像头的已知姿态,将图像排列在3D坐标空间中。生成神经辐射模型的过程可以描述为优化与成像对象对应的连续体积函数。一个合适的神经场模型是NeRF模型。
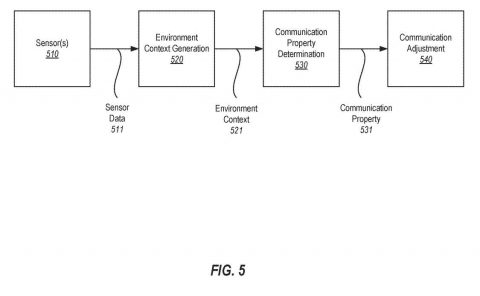
神经辐射模型来源于先前捕获的真实世界物体的多个数字图像。这通过图5进行说明。
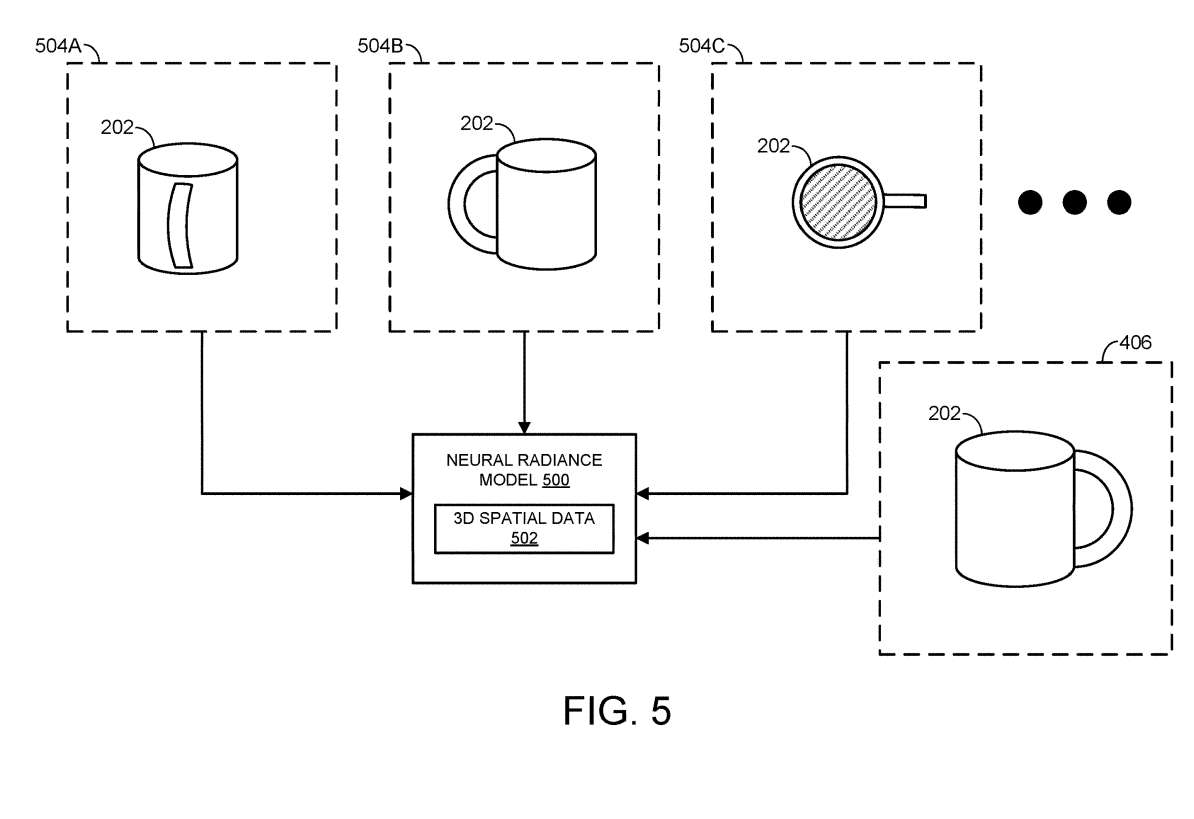
图5显示了编码与现实世界对象202对应的3D空间数据502的示例神经辐射模型500。
所述3D空间数据来源于先前捕获的从各种角度和视点捕获的真实世界对象202的多个数字图像504A-504C。
在一个实施例中,先前捕获的多个图像是“随意捕获”。当用户使用头显时,它们会随着时间的推移而被动捕获。这有利于生成神经辐射模型,而不需要用户特别努力捕获特定图像,从而提供减少用户输入计算设备负担的技术效果。另外,可以有意地捕获先前捕获的多个图像中的一个或多个,以便为神经辐射模型提供输入图像。
每次捕获到真实世界对象的新数字图像时,神经模型都会更新。在识别新的数字图像与先前捕获的图像之间的对应关系后,根据新的对应关系更新连续体积函数。如图5所示,数字图像406有助于神经辐射模型500编码的3D空间数据502。
如上所述,真实世界对象的成像姿态至少部分基于神经辐射模型进行估计。然而,完成这一操作的具体方式因实现而异。
在一个实施例中,神经辐射模型首先用于训练基于合成对象视图的推理模型,模型从各种任意视点描绘虚拟对象。在其他例子中,神经辐射模型本身是在代理中训练,以估计现实世界对象的姿态。
在生成合成对象视图的情况下,可以使用合成对象视图来训练推理模型。当提供数字图像时,模型可用于估计现实世界对象的姿态。换句话说,真实世界对象的成像姿态由先前至少部分地基于从神经辐射模型的3D空间数据生成的多个合成对象视图进行训练的推理模型估计。
例如,在训练期间提供给推理模型的每个合成对象视图都与呈现视图的虚拟对象的实际姿态配对。随着时间的推移,通过适当的训练过程,训练推理模型以准确地估计新输入视图的对象姿态。
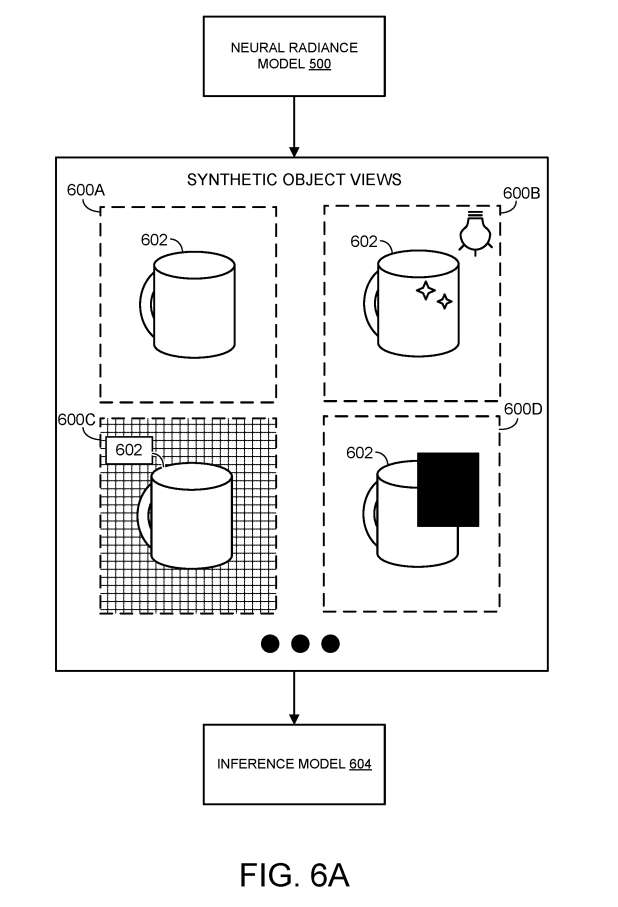
图6A给出了神经辐射模型500的示意图。如上所述,神经辐射模型训练为输出虚拟对象的任意虚拟姿态,至少部分地基于在多个先前捕获的现实世界对象图像之间识别的优化体积函数。这包括从神经辐射模型的3D空间数据中提取显式网格,并在不同的光照和背景条件下从多个视图渲染网格。
在图6A中,神经辐射模型用于输出多个合成对象视图600A-600D,每个视图描绘类似于现实世界对象202的虚拟对象602。合成对象视图用于训练推理模型604。
通过在训练数据集中包含相对多样化的图像,可以有益地提高推理模型的性能,从而在相对广泛的条件下训练模型。所以,生成多个合成对象视图包括在多个合成对象视图中的一个或多个之间改变一个或多个照明条件、背景条件、遮挡和虚拟对象姿势。这提供了提高推理模型性能的技术效果,使得推理模型能够更准确地估计成像对象的姿态。
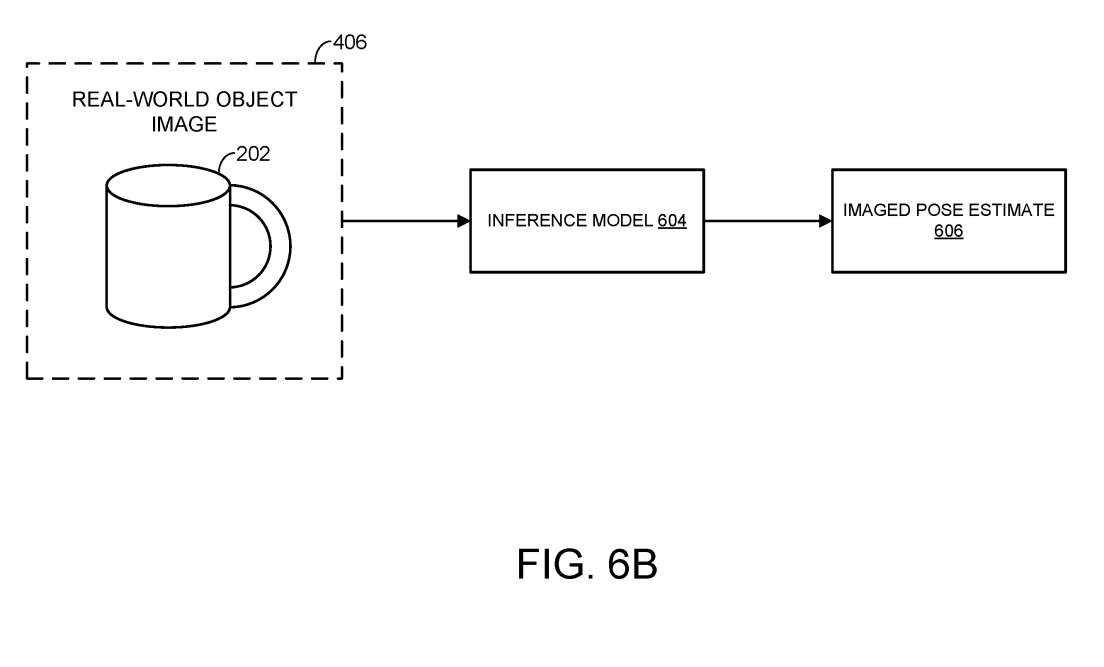
一旦通过多个合成物体视图训练推理模型,就可以用于估计数字图像中捕获的真实世界对象的成像姿态。如图6B所示,将描绘现实世界对象202的数字图像406传递给推理模型604。然后,推理模型输出预估606的真实世界对象的图像姿态。如上所述,推理模型通过任何合适的机器学习和/或人工智能技术实现。
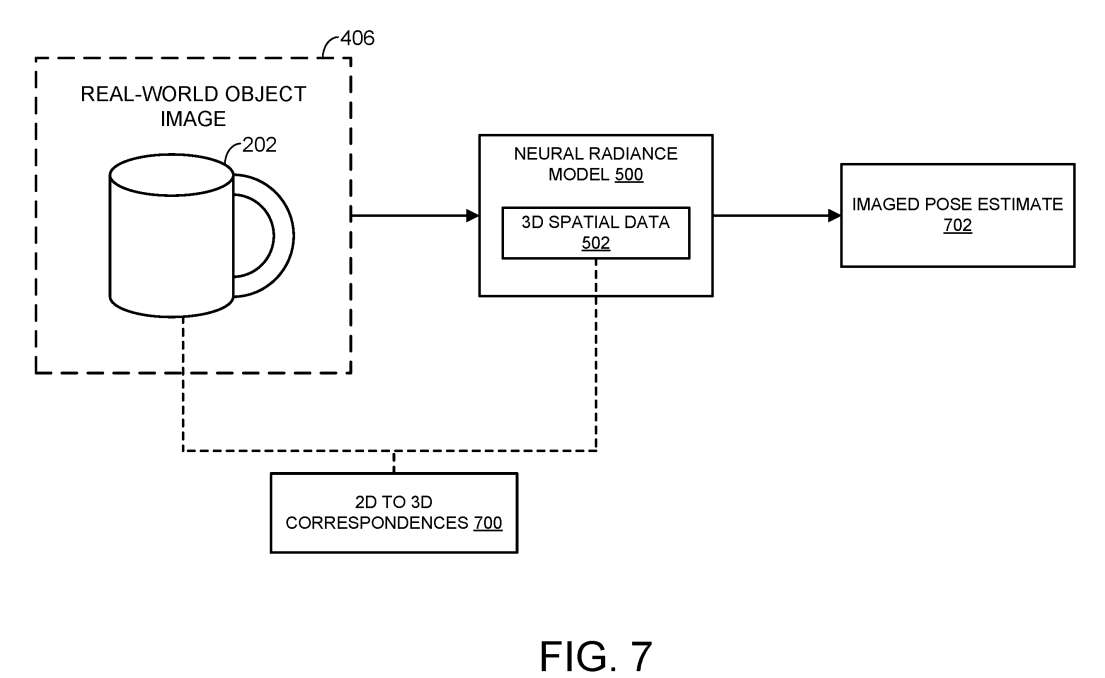
图7同样显示了神经辐射模型500,其包括3D空间数据502。计算系统识别数字图像406n的二维像素数据与神经辐射模型的三维空间数据之间的二维到三维对应700,使模型输出真实世界对象的成像姿态估计702。这样的估计以任何合适的方式输出。
在任何情况下,一旦真实世界对象的图像姿态估计出来,计算系统就会呈现出与图像姿态一致的虚拟对象视图。
回到图3,在306,方法300包括至少部分地基于神经辐射模型呈现与现实世界对象相对应的虚拟物体的视图,使得虚拟对象具有与数字图像中现实世界物体的成像姿态一致的虚拟姿态。
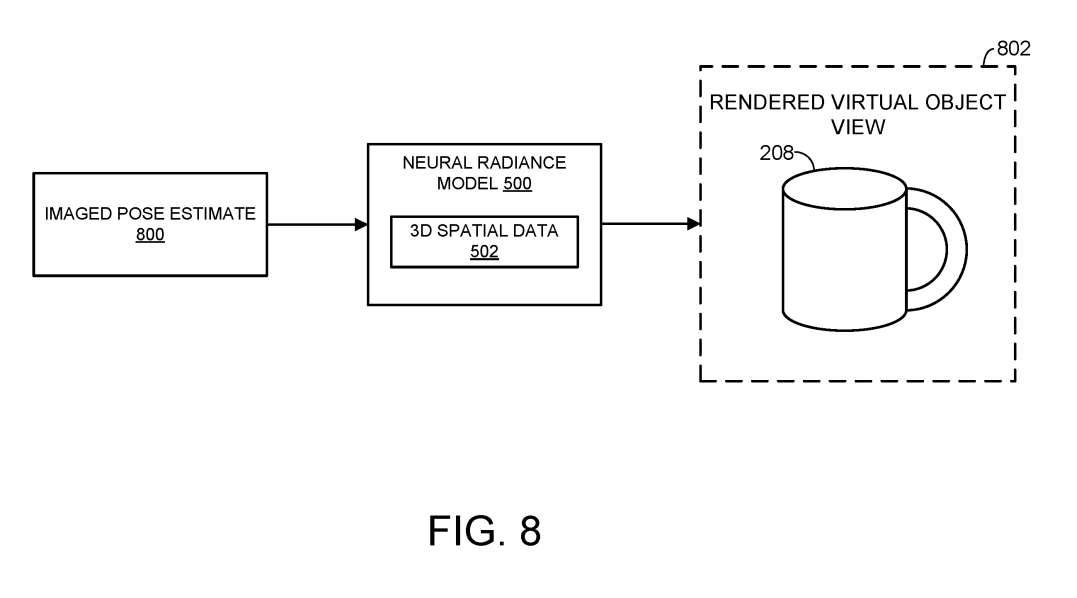
图8再次显示了神经辐射模型500。如图所示,基于真实世界物体的成像姿态的估计800,神经辐射模型输出虚拟对象视图802,其具有与真实世界对象的数字图像一致的外观和姿态。如上所述,可以用任何合适的方法估计真实世界对象的图像姿态。
值得注意的是,计算系统配置为以可变的细节级别呈现虚拟对象的视图。例如,在不需要在虚拟环境中高保真再现真实世界对象的情况下,可以在相对较低的细节级别呈现虚拟对象视图,以节省执行呈现的计算设备的计算资源。
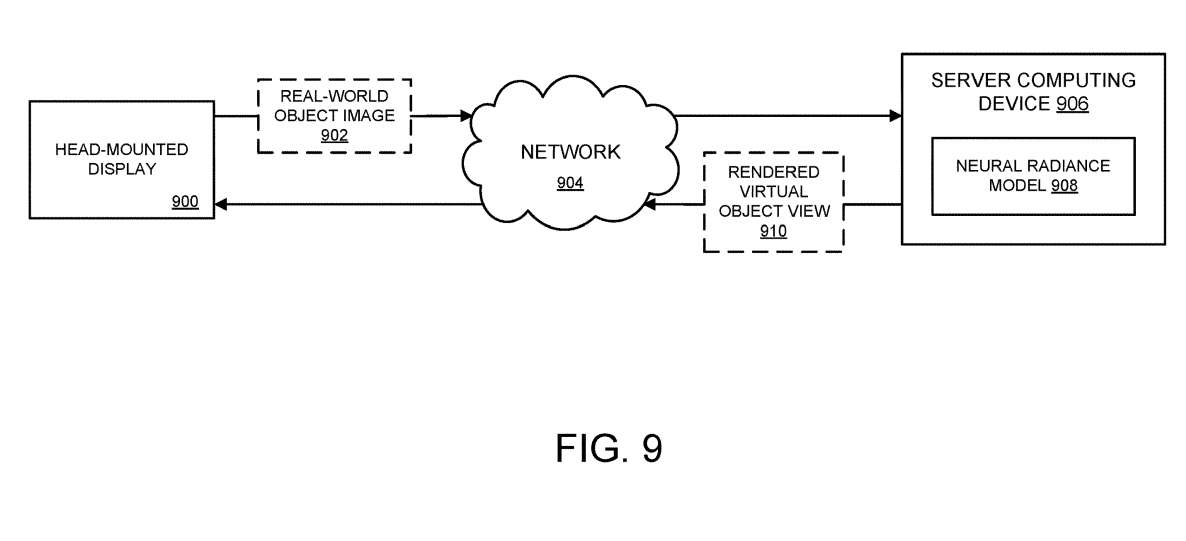
返回到图3,方法300可选地包括通过计算机网络传输虚拟对象的视图以供显示。图9说明了这一点。具体地,图9示意性地示出通过计算机网络904传输真实世界对象的图像902的示例头显 900。
所述真实世界对象的图像由服务器计算设备906接收,所述服务器计算设备906维持与所述真实世界对象对应的神经辐射模型908。如上所述,神经辐射模型是基于先前捕获的真实世界对象的多个图像生成的。先前通过头显 900和/或另一个合适的摄像设备传输到服务器。服务器计算设备估计数字图像中真实世界对象的成像姿态,并呈现虚拟对象视图910,以便通过计算机网络904传输回头显。
相关专利:Microsoft Patent | Virtual pose rendering using neural radiance model
名为“Virtual pose rendering using neural radiance model”的微软专利申请最初在2023年1月提交,并在日前由美国专利商标局公布。