微软AR/VR专利分享在运行情况下改进视频压缩和视频传输系统
减少带宽要求和/或提高分辨率
(映维网Nweon 2024年08月13日)在视频压缩和流媒体直播视频方面,头显设备提出了独特的挑战。带宽限制是一个挑战。另外,头部运动可能导致图像数据发生更频繁和大幅度的变化,从而降低了已知视频压缩技术的有效性。典型的流媒体视频压缩策略不能适应大量的camera移动。
所以,在camera移动频繁发生的情况下,需要改进的方法来进行视频压缩和视频流,从而减少带宽要求和/或提高分辨率。
在日前由美国专利商标局公布的一份专利申请中,微软就介绍了一种改进的视频压缩和视频传输系统。
这是通过结合用户环境形状的3D表示、图像数据以及代表camera在连续图像帧之间位置和方向变化的数据来实现。微软表示,所述方法减少了在camera运动的情况下发送流式视频所需的数据带宽。
在一个实施例中,专利描述的方法可以包括:从并入第一设备的摄像头捕获视频的连续帧,视频的连续帧包括前一帧图像和当前帧图像并包括表面(深度)信息;基于前一帧图像的表面(深度)信息和与前一帧图像相对应的第一camera位置和方向构建用户环境形状的第一3D表示;将前一帧图像投影到第一3D表示;检测前一帧图像与当前帧图像之间camera位置和方向的变化,并生成代表当前帧图像的camera位置和方向的当前帧camera位姿数据;
然后,基于与当前帧图像相对应的第二camera位置和方向构建用户环境形状的第二3D表示;渲染第二3D表示,以生成从所述camera的第二位置和方向查看的重投影前一帧图像;将重新投影的前一帧图像传递给视频压缩器,用于计算重新投影的前一帧图像与实际当前帧图像之间的差异;并生成仅包含重投影的前一帧图像与实际当前帧图像之间的差异的压缩视频数据。
另一实施例包括视频流系统和可以通过以下方式解码压缩视频数据的方法:在第二设备接收压缩视频数据和当前帧camera姿态数据;通过第二设备,基于接收到的当前帧camera姿态数据构建用户环境形状的3D表示,并渲染3D表示以生成重新投影的前一帧图像数据;将接收到的压缩视频数据应用于重新投影的前一帧图像数据,生成当前帧图像数据。
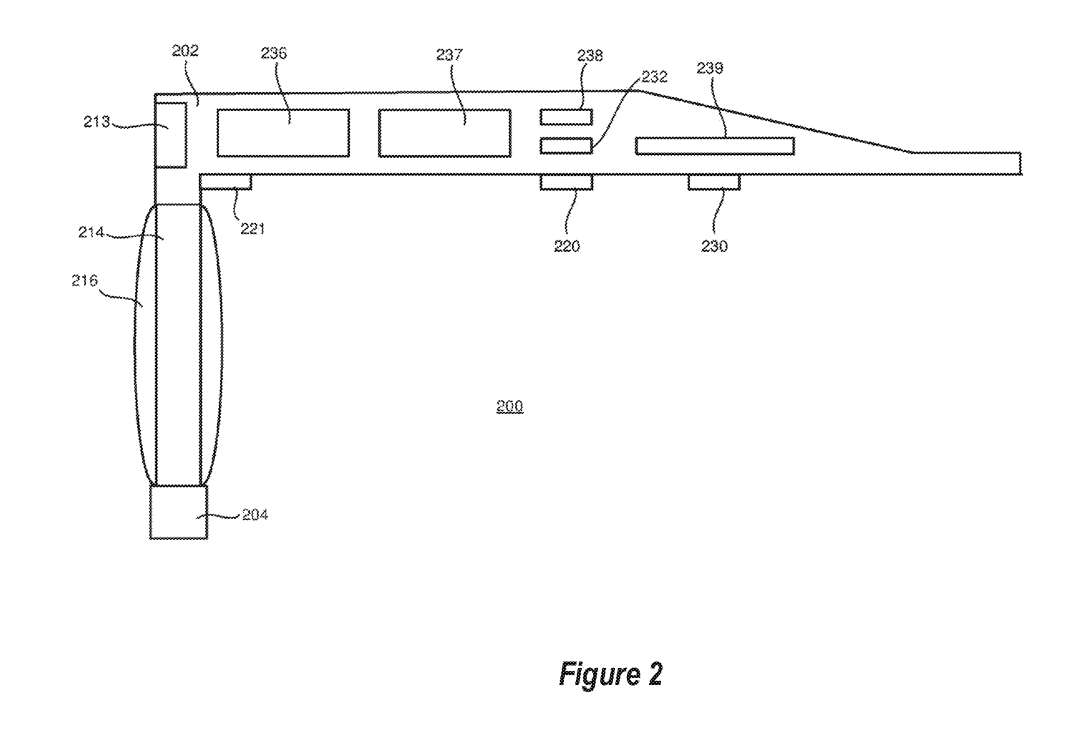
图2描述了向头显用户提供增强现实环境或混合现实环境的设备。所述设备的一个例子是微软HoloLens。HoloLens包括一个深度摄像头,它能够检测深度摄像头视场内对象的3D位置。
参考图3,HoloLens可以提供特别适合于位于不同位置的两个或多个用户之间的培训和其他交互活动的独特通信体验。利用集成在头显中的前向深度摄像头,远程用户可以观察头显用户的环境,并为头显用户提供实时反馈、指令和指示。
如图3所示,头显19可以通过一个或多个网络180向在另一个远程位置操作计算设备的另一个人通信音频和视频数据。另外,远程设备300可以向头显19发送指令,以在头显用户的视场内呈现全息图像,例如书面指令和/或绘图。
为了在头显19和远程设备300之间传输视频流,通常使用各种数据压缩方法来减少数据带宽和/或提高分辨率。然而,正如前面所讨论,传统的数据压缩系统和方法往往在camera移动常见的环境中效率较低。
视频通常使用p帧(或b帧)进行压缩。这减少了需要发送的数据量,因为只需要发送与前一帧不同的数据。不移动的图像区域不需要发送任何额外的数据。如果camera静止,传统的p帧或b帧视频压缩效果最好。当camera移动时,图像的每个像素都可以从一帧到下一帧发生变化。
为了处理运动,需要额外的关于像素如何移动的信息。例如,camera向右移动,处理图像的一种方法可能是将所有内容向右移动一定数量的像素,然后根据移动的图像计算差异。当然,这并不是那么简单,因为像素会因为独享在不同的深度而移动不同。
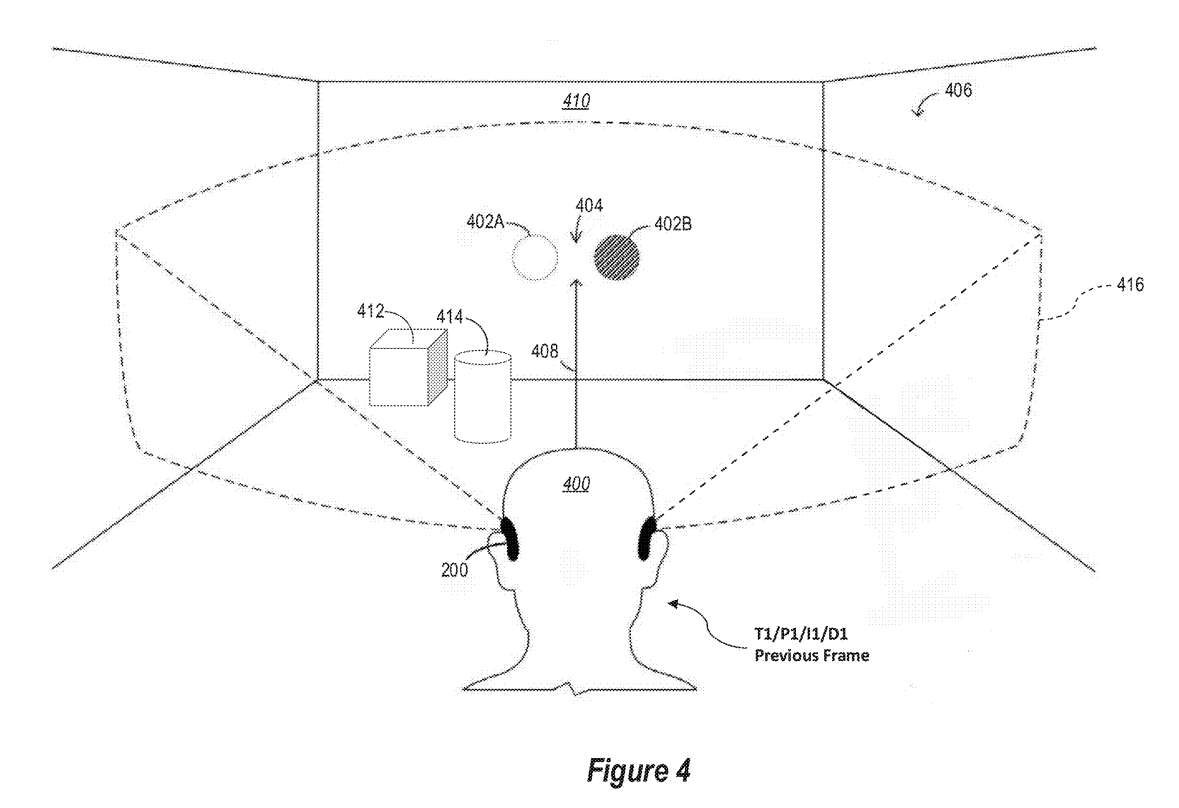
图4示出由用户400佩戴的头显设备200的增强现实配置,三维环境406是现实世界中的房间,并且全息光标402显示在立体显示器,使得全息光标402对用户400显示为悬停在位置404处的房间中间。
用户400所佩戴的头显200的前向深度摄像头捕获三维环境406的图像数据,所述三维环境406可以包括房间的物理布局、位于房间中的实际有形物体,例如物体412和414,以及它们彼此之间和相对于头显200的各自位置。
头显200创建了三维环境406的详细3D纹理模型,模型随时间不断更新。另外,对于深度摄像头捕获的每一帧视频,将图像数据的每个像素映射到3D模型的相应位置。这种将图像像素映射到3D纹理模型或网格的方法使得执行同形变换来重新投影图像成为可能,使其看起来就像用户400从不同的相对位置查看图像一样。
例如,图4示意图示出了用户400和时间T1以及位置P1。此时,头显200的前向深度摄像头采集第一帧图像数据(I1)和深度数据(D1)。出于讨论目的,与I1相关联的图像数据可以简单地称为11、图像数据1或前一帧图像。如前所述,头显200可以使用深度数据D1在用户的视窗内创建3D纹理模型或环境网格。
另外,头显200将图像数据1映射到3D模型或网格(D1)。通过将图像数据I1映射到3D模型或网格D1,可以从不同的观看位置重新投影、重新绘制或重新渲染I1,以创建重新投影的前一帧图像。
这样的重投影可以通过已知的图像变换方法或不同计算复杂度的重投影技术来完成。3D场景中的2D平面可以根据头显的最终用户在特定时间段内关注的虚拟对象来确定。在一个示例中,眼动追踪可用于确定在特定时间段内最频繁查看的虚拟对象。
在单个平面的情况下,单个平面可以根据在特定时间段内最常被查看的虚拟对象的深度来选择。在多个平面的情况下,增强现实环境中的虚拟对象可以基于与多个平面的接近程度划分为多个组。例如,如果近平面是最接近第一虚拟对象的平面,则第一虚拟对象可以映射到近平面,如果远平面是最接近第二虚拟对象的平面,则第二虚拟对象可以映射到远平面。
然后可以生成包括基于所述近平面的第一虚拟对象的第一渲染图像,并且可以生成包括基于所述远平面的第二虚拟对象的第二渲染图像。
另外,可以在预渲染图像的不同部分上执行不同的图形调整,以便合并更高频率的姿态估计。然后,重投影可以作为屏幕空间操作来应用。图像的每个像素都有颜色和深度。这用来根据每个像素的3D位置将图像翘曲到一个新的视角。
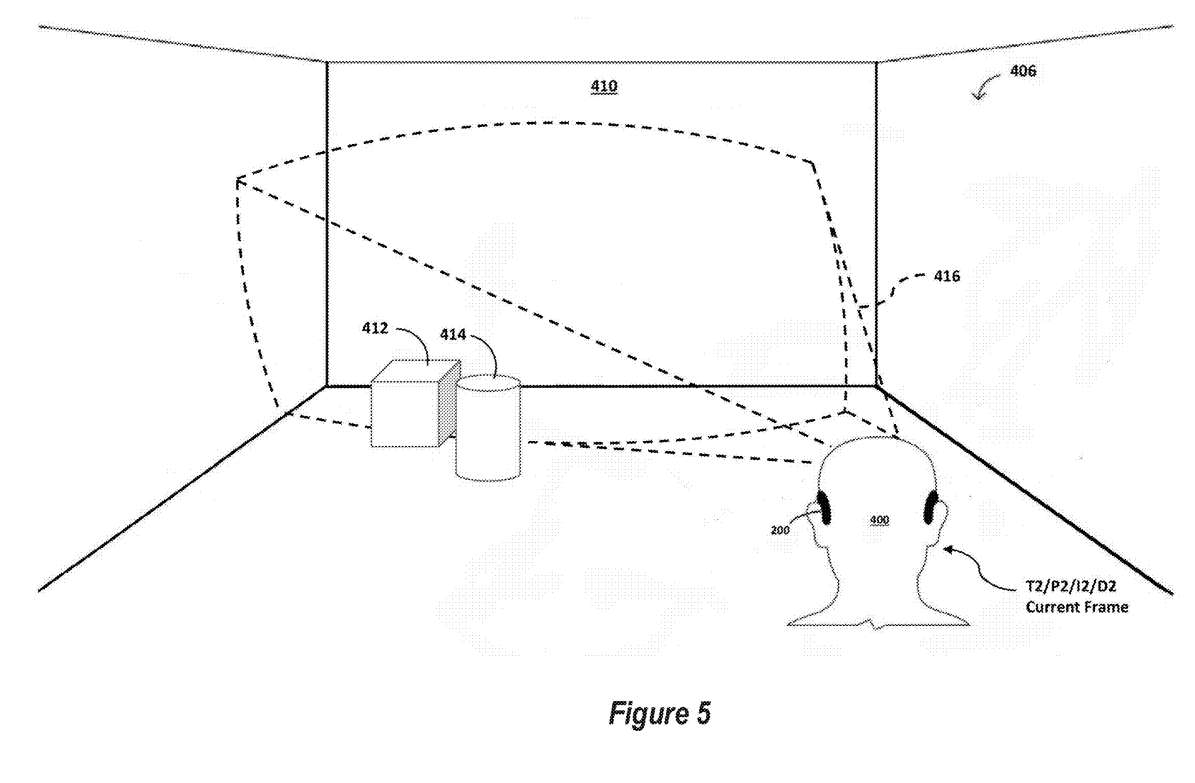
类似地,图5示意性地示出用户400在随后的时间点T2和相对于3D环境406的不同位置P2。例如,T1和T2可以与两个连续的图像帧相关联,I1(前一帧图像)和I2(当前帧图像)。如果选择16ms的常规帧率,则T1和T2之间可以间隔16ms。在T2时刻,头显200的前向深度摄像头捕获第二帧图像数据(I2)和深度数据(D2)。出于讨论目的,与I2相关联的图像数据可以简单地称为I2、图像数据2或当前帧图像。如前所述,头显200可以使用深度数据D2在用户的FOV内创建环境的3D纹理模型。另外,头显200将图像数据I2映射到3D模型(D2)。
图4和图5说明了在camera经常移动的情况下使用传统视频压缩的一个问题。在这种情况下,由于camera的位置和/或方向的变化,大部分背景不会保持静态。所以,传统的p帧处理效率较低,并且可能不会显著减少渲染下一帧图像所需的数据集的大小。
HoloSkype目前以两个独立的流发送以下内容:表面数据,它提供了用户环境形状的3D表示;HoloLens前端摄像头的视频数据。表面数据可以与视频数据相结合,从而获得更低的带宽或更高质量的流视频。
压缩前:将前一帧图像投影到camera前一帧位置的三维几何体;检测前一帧与当前帧之间camera姿态的变化;利用所述camera的当前帧姿态构建三维几何图形,以产生前一帧的重投影图像;将重投影后的前一帧图像传递给压缩器,计算其与当前帧图像的差值。这将消除由于camera运动的差异。
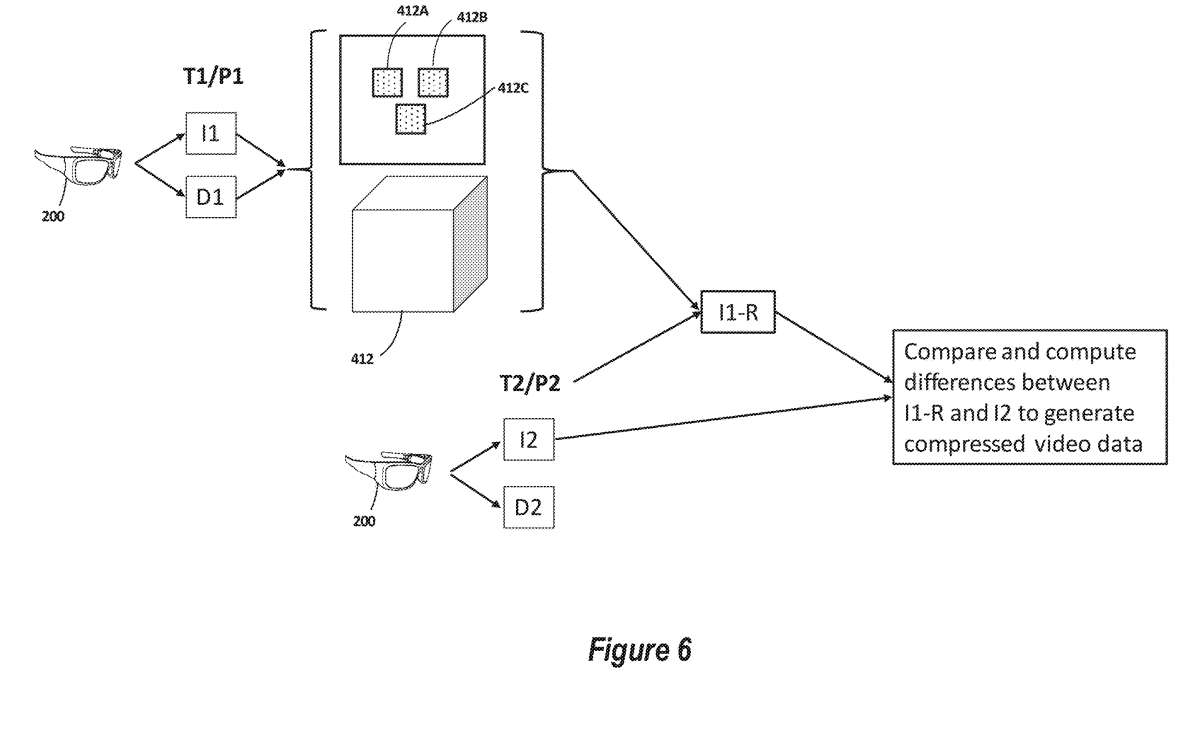
这一过程如图6所示。首先参考图6左上部分,在时间T1和位置P1,头显200的前向摄像头捕获图像数据I1和深度数据D1,它们都与前一帧图像(I1)相关联。
如上所述,头显200构建了一个位于头显200视场内的3D环境模型。具体地说,头显200可以构建视场内每个物理对象的每个可见表面的表面图。例如,纹理映射可以包括与物理对象412相对应的区域,所述区域可以由与对象412的三个可见表面412A、412B和412C相对应的多边形组成。
接下来,头显200将图像数据1的像素映射到纹理模型上的相应位置。如上所述,这一映射允许通过同质变换技术重新投影前一帧图像1,以显示从不同camera姿势查看时的样子。
如果检测到头显200的位置和/或方向在前一帧和当前帧之间发生变化,则头显200使用纹理模型和camera的新位置(P2)执行必要的同形变换以重新投影I1,从而生成重新投影的前一帧图像I1- r。然后将I1-R和I2传递给压缩引擎,以比较I1-R和I2之间的差异并生成压缩图像数据。
接下来,压缩图像数据可以与更新的姿势数据P2一起传输到第二个设备。使用前一帧图像与更新的姿态数据P2相结合,第二个设备执行类似的同形变换以生成前一帧图像I1的重投影,从而生成重投影的前一帧图像I1- r。然后,第二设备将压缩的视频数据应用于重投影的前一帧图像I1-R,以呈现当前帧图像I2。
在渲染重新投影的前一帧图像时,第一设备和第二设备应使用相同的3D模型。例如,第一设备可以向第二设备发送3D模型,并且这两个设备同意将用于呈现重新投影的前一帧图像的3D模型。因此,与前一帧相关联的3D模型可以在两个设备之间通信并由两个设备使用,以生成重新投影的前一帧。
类似地,与当前帧相关联的3D模型可以在两个设备之间通信并由两个设备使用,以生成重新投影的前一帧。在另一个实施例中,对3D模型的更新可以在第一和第二设备之间通信并由第一和第二设备使用。在3D环境没有显著变化的情况下,另一种可能是扫描3D模型,在每次会话开始时发送它,然后执行相对于该模型的所有重新投影而不发送更改。
在3D环境的大部分内容是静态的情况下,通过使用发明实现的带宽节省最好。在这种情况下,3D模型本身的变化所带来的任何误差通常都相对较小。当前一帧与当前帧的3D模型不同时,无论使用前一帧模型还是当前帧模型,都会导致重投影的前一帧图像出现误差。当3D环境本身在移动时,很难理解这种3D运动并使用它以一种解释这种运动的方式重新投影。
然而,使用发明描述的方法,当将错误包含在捕获重新投影的前一帧与实际当前帧之间的差异的压缩视频数据中时,错误可以纠正。
在另一个实施例中,表面几何形状可以随时间不断更新。当用户观察3D环境的不同区域时,可能会看到不同的表面。随着时间的推移,纹理模型可以更新和改进,以包括额外的表面。
当用户环顾房间时,所有之前的帧都可以用来细化应用于表面的纹理。如果发送方和接收方构建匹配的模型,则可以根据camera的当前位置计算相对于模型渲染的帧差。通过这种方式,每当一个新的表面进入视图时,即便它在前一帧图像中不可见,都可以使用对象的最新视图。
上述视频压缩系统和方法的一个实施例如图7所示。
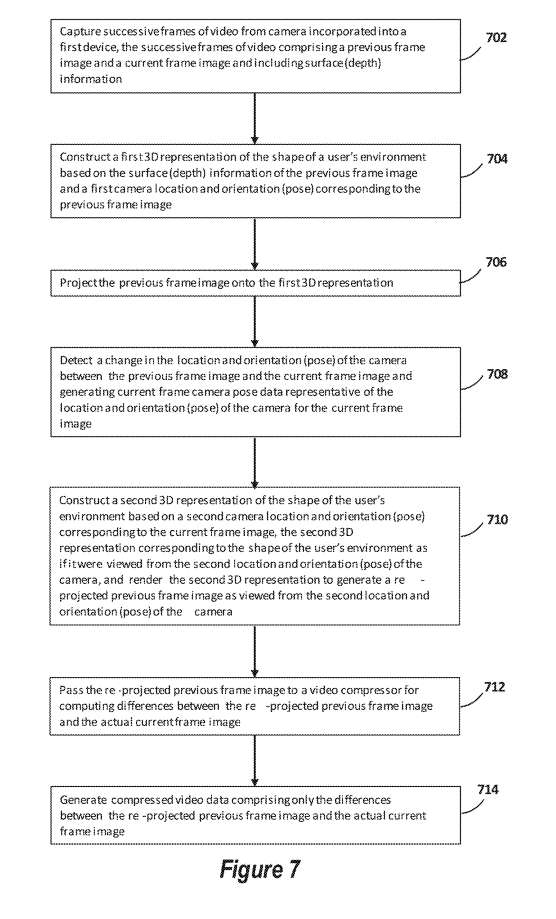
在702中,从并入第一设备的摄像头捕获视频的连续帧,所述视频的连续帧包括前一帧图像和当前帧图像并包括表面(深度)信息。
在704中,系统可以基于前一帧图像的表面(深度)信息和与前一帧图像相对应的第一camera位置和方向构建用户环境形状的第一3D表示。
在706中,可以将所述前一帧图像投影到所述第一3D表示。
在708中,所可以检测所述前一帧图像与所述当前帧图像之间所述camera的位置和方向的变化,并生成当前帧camera位姿数据。
在710中,可以基于与当前帧图像相对应的第二camera位置和方向构建用户环境形状的第二3D表示该第二3D表示与用户环境的形状相对应;渲染第二3D表示,以生成从所述camera的第二位置和方向查看的重新投影前一帧图像。
在712中,可将所述重新投影的前一帧图像传递给视频压缩器,以计算所述重新投影的前一帧图像与实际当前帧图像之间的差异。
在714中,可以生成仅包含重新投影的前一帧图像与实际当前帧图像之间的差异的压缩视频数据。压缩后的视频数据可以保存到一个文件中,以便进行额外的处理。另外,可以将压缩的视频数据传输到第二接收设备进行进一步处理,如图8所示。
图7所示的方法同时可以传输基于当前帧camera姿态数据的表面(深度)数据的变化。另外,图7所示的方法可以配置为对于所有先前的图像帧积累3D环境的纹理模型,以细化当用户从不同camera位置随着时间的推移遇到3D环境时应用于表面的纹理。
在HoloSkpye或其他视频会议会话的情景中,以上述方式导出的压缩视频数据随后可以传输到第二接收设备,同时通过camera的位置和旋转发送设备camera的位置,而这是非常少量的数据。在接收设备,解压执行相同的步骤,然后对前一帧的相同重投影应用差异,从而在另一侧产生匹配的图像。
参照图8。
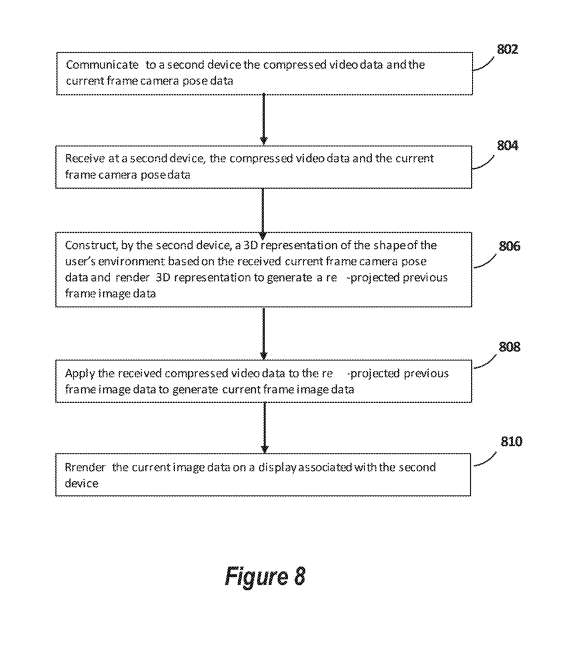
如步骤802所述,可以向第二设备通信所述压缩视频数据、所述当前帧相机姿态数据和所述用户环境形状的3D表示。
在步骤804中,可在第二设备接收所述压缩视频数据、所述当前帧camera姿态数据和所述用户环境形状的3D表示。
在步骤806中,可以通过第二设备基于所接收的当前帧camera姿态数据构建用户环境形状的3D表示,并呈现所述3D表示以生成重新投影的前一帧图像数据。
在步骤808中,可以将接收到的压缩视频数据应用于重新投影的前一帧图像数据,以生成当前帧图像数据。
在步骤810中,可以在与第二设备相关联的显示器呈现当前图像数据。
相关专利:Microsoft Patent | Reprojecting holographic video to enhance streaming bandwidth/quality
名为“Reprojecting holographic video to enhance streaming bandwidth/quality”的微软专利申请最初在2023年10月提交,并在日前由美国专利商标局公布。